




 本文探讨了机器学习中的模型融合技术——Blending和Stacking。Blending是将训练好的基模型对测试集的预测结果进行加权平均,而Stacking则通过k折交叉验证生成新的特征,避免数据泄露。两者区别在于Blending实现简单,但可能因数据利用不足导致过拟合,而Stacking更为稳健。
本文探讨了机器学习中的模型融合技术——Blending和Stacking。Blending是将训练好的基模型对测试集的预测结果进行加权平均,而Stacking则通过k折交叉验证生成新的特征,避免数据泄露。两者区别在于Blending实现简单,但可能因数据利用不足导致过拟合,而Stacking更为稳健。
各种比赛中常常见到在特征工程和调参取不到太大的进步的时候,转而进行模型融合操作。
常用方法用Stcaking和Blending,该文记录一下学习使用中的情况。
Blending
数据划分为不相交的部分,一部分用来训练不同的 Base Model,将它们对另外部分的数据输出取(加权)平均。实现简单,但对训练数据利用少了。可以通过对输出组合成一份数据,在其上训练一个LR模型。要求个别单模型效果要好而且模型之间有差异。
Stacking
stacking可以看作是复杂一点的blending。
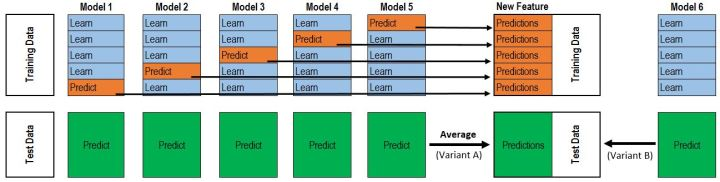
通过k折交叉验证的思想,避免数据泄露(避免再次预测做过训练集数据的样本标签的这种情况),用不同模型预测不同的样本。
def get_oof(clf, x_train, y_train, x_test):
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
oof_test_skf = np.empty((NFOLDS, ntest)) #NFOLDS行,ntest列的二维array
for i, (train_index, valid_index) in enumerate(kf): #循环NFOLDS次
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_va = x_train[valid_index]
clf.fit(x_tr, y_tr)
oof_train[valid_index] = clf.predict(x_va)
oof_test_skf[i, :] = clf.predict(x_test) #固定行填充,循环一次,填充一行,一行就是一个model对于测试集的预测
oof_test[:] = oof_test_skf.mean(axis=0) #axis=0,按列求平均,最后保留一行
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1) #转置,从一行变为一列
区别
1.blending比stacking简单(因为不用进行k次的交叉验证来获得新特征)。
2.blending两层训练使用的数据不同,所以避免了一个信息泄露的问题。
3.在团队建模过程中,不需要给队友分享自己的随机种子(可以开始划分确定划分)。
4.由于blending对数据集这种划分形式,第二轮(留下的)的数据量比较少,进而可能会过拟合;而stacking使用多次的CV,数据量也不变少会比较稳健。

















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









