






 本文介绍如何使用Selenium和Chromedriver爬取拉勾网职位信息,通过模拟用户操作避开反爬机制,并将数据导入Elasticsearch。重点在于代码实现和避免登录限制。
本文介绍如何使用Selenium和Chromedriver爬取拉勾网职位信息,通过模拟用户操作避开反爬机制,并将数据导入Elasticsearch。重点在于代码实现和避免登录限制。
前言
爬取的是拉勾的职位信息数据,由于官方做了反爬,试了下别人写的获取cookie的方法后失败了,后面又采用了另一个作者写的模拟网页操作的方法后,即可获取成功,暂时还没做登录操作,试了下只能最多爬到15页左右后就跳出需要登录的页面。改了下效果,爬取后添加到es里面进行保存,如果只要导出到csv,可以参考上一篇从es导出csv的文章。
一、获取chorme相同版本的chromedriver
Selenium 是 ThoughtWorks 提供的一个强大的基于浏览器的开源自动化测试工具。支持的浏览器包括 IE、Chrome 和 Firefox 等。
1、查看Chrome浏览器版本
点击Chrome菜单“帮助”→“关于Google Chrome”
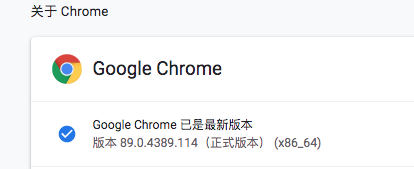
2、获取对应版本的chromedriver
打开链接
https://npm.taobao.org/mirrors/chromedriver/

下载对应系统的文件
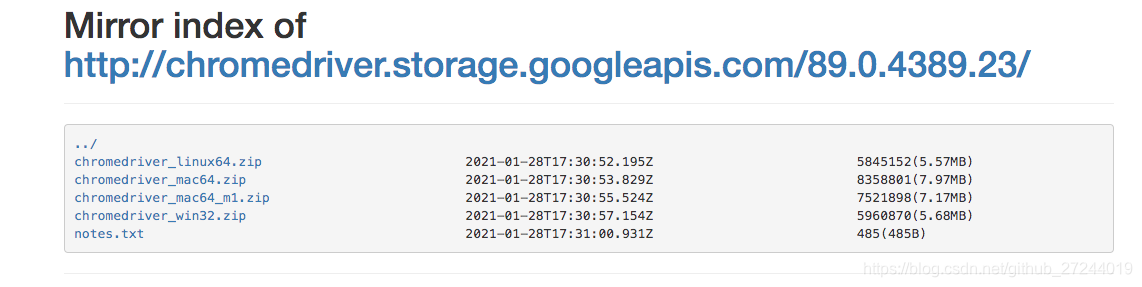
3、环境变量配置
下载完成后,将ChromeDriver的可执行文件配置到环境变量下。
如我的是mac,存放在 /usr/local/bin/chromedriver 中
修改 ~/.profile文件
export PATH="$PATH:/usr/local/bin/chromedriver"
source ~/.profile
配置完成后使用chromedriver:
chromedriver
如下图即是成功

二、代码
代码如下(示例):
import time
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from elasticsearch import Elasticsearch
# 写入ES
ES = [
'http://192.168.11.111:9200'
]
es = Elasticsearch(ES)
index_name = "lagou"
city = input("请输入您要查询的城市:")
major = input("请输入您要查询的工作:")
# 控制浏览器,自动化
driver = webdriver.Chrome()
url = 'https://www.lagou.com/jobs/list_python?px=default&city='+str(city)+'#filterBox'
driver.get(url)
inputJob = driver.find_element_by_xpath('//*[@id="keyword"]')
# 清空输入框
inputJob.clear()
# 获得并输入刚才输入的工作
inputJob.send_keys(major)
# 按回车键
inputJob.send_keys(Keys.ENTER)
# 暂停的时间至少在5秒上,少了怕被反爬虫机制识别
time.sleep(6)
last_page = driver.find_element_by_xpath("//div[@class='pager_container']/span[last()-1]")
# 取到页数的数字
last_page = int(last_page.get_attribute("page"))
# 判断页面并限制循环次数,每个页面爬取一次
for i in range(1,last_page+1,1):
print("正在爬取第%s页......\n"% i)
# 第一次不执行,停止由最大页数循环控制
while i > 1:
# 获取下一页按钮
next_page = driver.find_element_by_xpath("//div[@class='pager_container']/span[last()]")
# 点击下一页
next_page.click()
break
# 暂停五秒,注意反爬虫
time.sleep(5)
# 获取该网页源码
source = driver.page_source
# 解析网页
html = etree.HTML(source)
# 获取每条数据在的节点
works = html.xpath('//*[@id="s_position_list"]/ul/li')
for work in works:
# 职位名称
position_name = work.xpath("./div[1]/div[1]/div[1]/a/h3/text()")[0]
# 详情链接
position_url = work.xpath("./div[1]/div[1]/div[1]/a/@href")[0]
# 岗位描述,数组型数据
desc = work.xpath('./div[2]/div[1]/span/text()')
# 把数据型转化成字符型才能使用replace替换字符
desc = str(desc).replace("[","").replace("', '",",").replace("]","").replace("'","")
# 薪资
salary = work.xpath("./div[1]/div[1]/div[2]/div/span/text()")[0]
# 公司名称
company_name = work.xpath("./div[1]/div[2]/div[1]/a/text()")[0]
# 岗位需求
job_request_spans = work.xpath("./div[1]/div[1]/div[2]/div/text()")[-1]
job_request_spans = str(job_request_spans).replace("\n","").replace(" ","")
# 截取出工作经验
job_experience = job_request_spans.split('/')[0]
# 截取出学历
education = job_request_spans.split('/')[-1]
# 公司描述
company_resquest = work.xpath("./div[1]/div[2]/div[2]/text()")[-1]
company_resquests = str(company_resquest).replace("\n","").replace(" ","")
# 截取出公司的工作
company_work = company_resquests.split('/')[0]
# 截取出公司要求
company_resquest = company_resquests.split('/')[1]
# 截取出公司人数
company_people = company_resquests.split('/')[-1]
# 公司福利
company_welfare = work.xpath("./div[2]/div[2]/text()")
# 判断公司是否表明有福利,有则执行条件
if company_welfare != 0:
company_welfare = company_welfare[0]
# 获取所在城市位置
place = work.xpath("./div[1]/div[1]/div[1]/a/span/em/text()")[0]
infos = {
"name": position_name,
"url": position_url,
"detail":desc,
"salary":salary,
"company":company_name,
"experience":job_experience,
"education":education,
"profession":company_work,
"request":company_resquest,
"people":company_people,
"boon":company_welfare,
"site":place
}
# 插入es
es.index(index=index_name, doc_type=index_name, body=infos)
print ("拉勾网 "+str(city)+"的"+str(major)+"岗位已经获取完毕!")
三、效果图
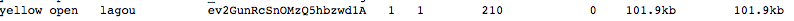
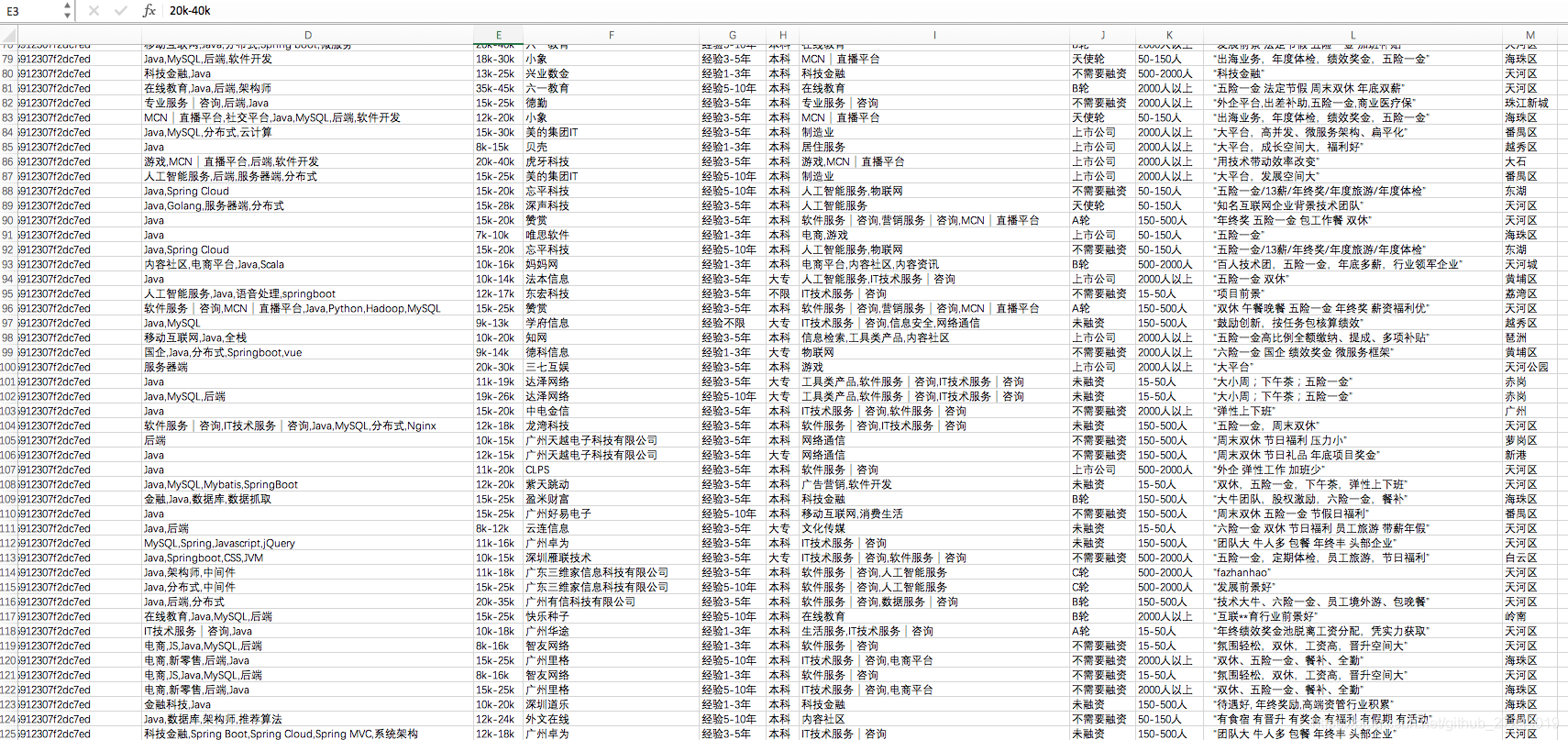


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









