






JavaGuide项目:Kafka核心原理与常见问题深度解析
 项目地址: https://gitcode.com/gh_mirrors/ja/JavaGuide
项目地址: https://gitcode.com/gh_mirrors/ja/JavaGuide 一、Kafka基础概念与核心架构
1.1 Kafka的本质与核心能力
Kafka本质上是一个分布式流式处理平台,其核心能力体现在三个维度:
- 消息队列能力:提供高效的消息发布与订阅机制,支持多生产者多消费者模式
- 持久化存储能力:所有消息持久化到磁盘,保证数据不丢失
- 流处理能力:内置完整的流处理类库,支持实时数据处理
1.2 Kafka的典型应用场景
在实际生产环境中,Kafka主要应用于两大场景:
- 实时数据管道:构建系统间可靠的数据传输通道,如日志收集系统、监控数据传递等
- 实时流处理:支持复杂事件处理(CEP)、实时数据分析等场景
1.3 Kafka的架构优势
相比传统消息队列,Kafka具有以下显著优势:
- 极致性能:单机可支持每秒千万级消息处理
- 水平扩展:通过分区机制实现线性扩展
- 生态兼容:与大数据生态无缝集成,是流计算领域的标准组件
二、Kafka消息模型详解
2.1 传统队列模型的局限性
传统队列模型存在两个主要问题:
- 消息独占消费:一条消息只能被一个消费者处理
- 广播场景支持不足:难以实现一条消息被多个消费者同时消费
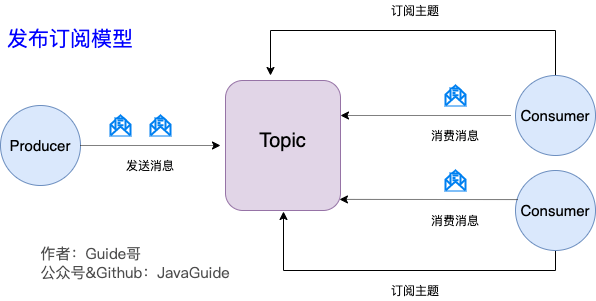
2.2 Kafka的发布-订阅模型
Kafka采用发布-订阅模型解决上述问题:
- **主题(Topic)**作为消息载体,类似广播频道
- 生产者发布消息到Topic,所有订阅该Topic的消费者都能收到消息
- 支持消费者组(Consumer Group)概念,实现负载均衡
三、Kafka核心组件解析
3.1 核心角色定义
| 组件 | 作用描述 | |------------|--------------------------------------------------------------------------| | Producer | 消息生产者,负责创建并发送消息到指定Topic | | Consumer | 消息消费者,订阅Topic并处理消息 | | Broker | Kafka服务实例,多个Broker组成集群 | | Topic | 消息类别/主题,生产者按Topic发布消息,消费者按Topic订阅 | | Partition | Topic的物理分区,一个Topic可分为多个Partition,分布在不同的Broker上 |
3.2 多副本机制解析
Kafka通过多副本(Replica)机制保证高可用:
- Leader-Follower架构:每个分区有一个Leader和多个Follower
- 数据同步机制:生产者只与Leader交互,Follower从Leader拉取数据同步
- 故障转移:当Leader失效时,从ISR(In-Sync Replica)列表选举新Leader
四、消息顺序性与可靠性保障
4.1 消息顺序性保证
Kafka保证分区(Partition)内消息有序,全局有序需特殊处理:
- 单分区方案:整个Topic只设置一个Partition(牺牲并发性能)
- Key路由方案:相同Key的消息路由到同一Partition(推荐方案)
4.2 消息不丢失配置
确保消息不丢失需要多方配合:
生产者端配置:
acks=all // 等待所有副本确认
retries=MAX_INT // 无限重试
max.in.flight.requests.per.connection=1 // 保证顺序
Broker端配置:
replication.factor>=3 // 副本数≥3
min.insync.replicas>1 // 最小同步副本数>1
unclean.leader.election.enable=false // 禁止非同步副本成为Leader
消费者端配置:
enable.auto.commit=false // 关闭自动提交
手动提交offset // 确保消息处理完成后再提交
4.3 重复消费问题解决
重复消费的根本原因是消费后offset提交失败,解决方案:
- 幂等设计:利用Redis SETNX或数据库唯一键
- 事务机制:将消费与业务处理放在同一事务
- 去重表:记录已处理消息ID
五、Kafka重试机制深度解析
5.1 默认重试行为
Spring Kafka默认重试配置:
- 最大重试次数:10次
- 重试间隔:0毫秒(立即重试)
- 重试失败后:跳过当前消息继续消费
5.2 自定义重试策略
通过自定义ErrorHandler实现灵活控制:
@Bean
public KafkaListenerContainerFactory kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
FixedBackOff backOff = new FixedBackOff(1000L, 3); // 间隔1秒,最多3次
factory.setCommonErrorHandler(new DefaultErrorHandler(backOff));
return factory;
}
5.3 高级重试方案
对于复杂场景,推荐使用@RetryableTopic:
@RetryableTopic(
attempts = "4",
backoff = @Backoff(delay = 1000, multiplier = 2),
dltTopicSuffix = "-dlt"
)
@KafkaListener(topics = "orders")
public void processOrder(Order order) {
// 业务处理
}
此方案会自动创建死信队列(DLT)处理重试失败的消息。
六、Zookeeper与KRaft模式
6.1 Zookeeper的核心作用
Zookeeper在Kafka中主要负责:
- Broker注册与发现
- Topic配置管理
- 分区状态维护
- 消费者offset记录(旧版本)
6.2 KRaft模式演进
Kafka 2.8+开始支持KRaft模式:
- 去除Zookeeper依赖
- 使用Raft共识算法
- 简化架构,提升稳定性
- 生产环境建议使用Kafka 3.3.1+版本
七、最佳实践建议
- 分区设计:根据吞吐量需求合理设置分区数
- 副本配置:生产环境建议replication.factor=3
- 监控告警:密切监控ISR集合大小
- 容量规划:预留20%-30%的磁盘空间
- 版本选择:生产环境建议使用LTS版本
通过深入理解这些核心原理和配置要点,开发者可以构建出高性能、高可靠的Kafka消息系统。在实际应用中,还需要根据具体业务场景进行针对性调优。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











