






基于PaddlePaddle的长文档处理利器:Longformer模型详解
 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-DeepLearning
项目地址: https://gitcode.com/gh_mirrors/aw/awesome-DeepLearning 引言
在自然语言处理领域,Transformer架构因其强大的序列建模能力而广受欢迎。然而,传统Transformer模型在处理长文档时面临显著挑战,主要源于其自注意力机制的高计算复杂度。本文将深入解析Longformer模型,这是一种专为长文档处理而优化的Transformer变体,特别适合在PaddlePaddle深度学习框架中应用。
1. Longformer模型背景
1.1 传统Transformer的局限性
传统Transformer模型(如BERT)采用全连接的自注意力机制,其计算复杂度与序列长度呈平方关系(O(n²))。这导致:
- 输入长度受限(通常为512个token)
- 长文档需要被截断处理
- 计算资源消耗大
1.2 Longformer的创新
Longformer通过改进自注意力机制,实现了:
- 线性复杂度(O(n))
- 支持更长的输入序列(最高可达4096个token)
- 保持模型性能的同时降低计算开销
2. Longformer的核心技术
2.1 滑动窗口注意力(Sliding Window Attention)
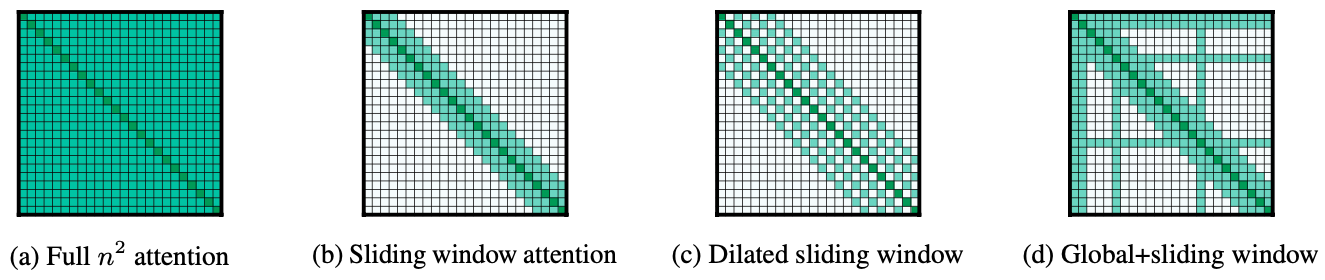
工作原理:
- 为每个token设置固定大小的注意力窗口(w)
- 每个token只能关注窗口内的其他token
- 高层网络具有更大的感受野
优势:
- 计算复杂度降至O(n×w)
- 通过多层叠加,高层网络仍能捕获全局信息
2.2 空洞滑动窗口(Dilated Sliding Window)
改进点:
- 在窗口内引入间隔(dilation)
- 扩大感受野而不增加计算量
- 混合使用不同间隔的窗口
效果:
- 感受野扩展至d×w
- 更高效地捕获长距离依赖
2.3 全局注意力(Global Attention)
设计理念:
- 为特定任务相关的token添加全局可见性
- 例如:分类任务中的[CLS]标记
- 问答任务中的问题相关token
实现方式:
- 独立计算全局和局部注意力
- 使用不同的Q、K、V投影矩阵
3. Longformer的实现优化
3.1 实现方案对比
| 实现方式 | 支持特性 | 适用场景 | 性能特点 | |---------|---------|---------|---------| | Full Self-Attention | 完整注意力 | 基准测试 | 高复杂度 | | Longformer-loop | 支持空洞窗口 | 测试阶段 | 内存高效但速度慢 | | Longformer-chunks | 基础滑动窗口 | 训练/微调 | 平衡性能 | | Longformer-cuda | 定制CUDA内核 | 生产环境 | 最优性能 |
3.2 PaddlePaddle实现建议
在PaddlePaddle中实现Longformer时,可考虑:
- 使用分组卷积优化滑动窗口计算
- 利用Paddle的灵活张量操作实现注意力掩码
- 针对长序列优化内存管理策略
4. 应用场景与优势
4.1 典型应用
- 长文档分类
- 法律文书分析
- 科研论文处理
- 长文本问答系统
4.2 性能优势
- 效率提升:相比传统Transformer,处理长文档速度显著提高
- 内存优化:线性复杂度大幅降低内存消耗
- 任务适配:灵活的注意力机制适应不同NLP任务
5. 实践建议
对于PaddlePaddle使用者:
- 输入处理:合理设置滑动窗口大小(通常w=512)
- 模型配置:根据任务需求调整全局注意力位置
- 训练技巧:
- 使用渐进式窗口大小训练
- 混合精度训练加速长序列处理
- 推理优化:利用Paddle Inference进行部署优化
结语
Longformer为长文档处理提供了高效的解决方案,特别适合在PaddlePaddle生态中应用。通过创新的注意力机制设计,它在保持模型性能的同时,显著提升了长序列处理的效率。随着NLP应用对长文本处理需求的增长,Longformer及其变体将成为重要的技术选择。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











