






JCSprout项目:深入理解Kafka消费者模式与高效消费策略
 项目地址: https://gitcode.com/gh_mirrors/jc/JCSprout
项目地址: https://gitcode.com/gh_mirrors/jc/JCSprout 前言
在现代分布式系统中,Kafka作为高性能的消息队列系统被广泛应用。本文将基于JCSprout项目中的实践经验,深入探讨Kafka消费者的不同使用模式,帮助开发者构建高效可靠的消息消费系统。
Kafka消费者基础概念
Kafka消费者负责从Kafka集群中读取数据,其核心设计理念包括:
- 消费者组(Consumer Group):一组共同消费一个或多个Topic的消费者实例
- 分区分配(Partition Assignment):Kafka确保每个分区只被组内的一个消费者消费
- 偏移量管理(Offset Management):记录消费者在每个分区的消费位置
单线程消费模式
实现原理
单线程消费是最简单的消费方式,消费者实例串行地从所有分配的分区中拉取消息。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("data-push"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("partition = %d, offset = %d, key = %s, value = %s%n",
record.partition(), record.offset(), record.key(), record.value());
}
}
} finally {
consumer.close();
}
优缺点分析
优点:
- 实现简单,适合低吞吐量场景
- 消息顺序性有保证
- 资源占用少
缺点:
- 性能瓶颈明显,无法充分利用多核CPU
- 容错性差,线程阻塞会导致整个消费过程停滞
- 无法水平扩展
多线程消费模式
独立消费者模式
独立消费者(Standalone Consumer)允许开发者精确控制消费哪些分区,适合特殊场景下的消费需求。
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 手动分配分区
TopicPartition partition0 = new TopicPartition("data-push", 0);
TopicPartition partition1 = new TopicPartition("data-push", 1);
consumer.assign(Arrays.asList(partition0, partition1));
// 消费逻辑...
适用场景:
- 需要精确控制消费特定分区
- 消费组模式不满足特殊需求
- 实现自定义的分区分配策略
架构特点: 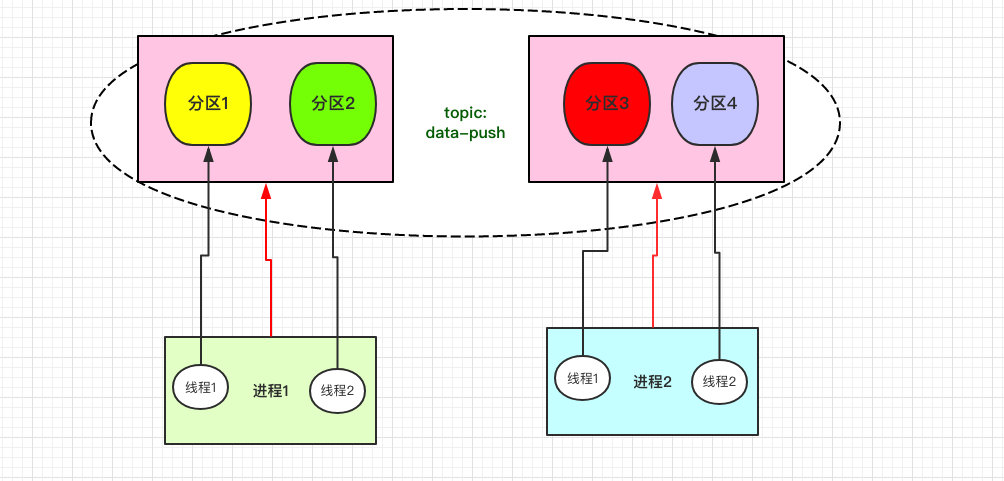
消费组模式
消费组模式是Kafka推荐的标准消费方式,提供了自动化的分区分配和故障转移能力。
核心特性:
- 自动分区分配:Kafka自动将分区分配给组内消费者
- 再平衡机制(Rebalance):消费者增减时自动重新分配分区
- 消费进度管理:自动或手动提交偏移量
多线程实现方式:
// 创建多个消费者实例,使用相同的group.id
for (int i = 0; i < threadCount; i++) {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumers.add(consumer);
new Thread(new ConsumerWorker(consumer)).start();
}
再平衡过程详解:
- 消费者加入或离开组
- 组协调器(Group Coordinator)触发再平衡
- 所有消费者停止消费
- 重新分配分区
- 消费者获取新的分区分配
- 恢复消费
性能优化实践
消费组规模与分区数的关系
| 消费者数量 | 分区数量 | 效率评估 | |------------|----------|----------| | 1 | 3 | 低效 | | 3 | 3 | 最优 | | 4 | 3 | 有闲置 | | 2 | 3 | 不均衡 |
最佳实践:
- 消费者数量应与分区数量保持一致
- 增加分区时可动态扩展消费者
- 避免消费者数量远大于分区数
消费参数调优
- fetch.min.bytes:单次拉取最小数据量
- fetch.max.wait.ms:等待拉取数据的最长时间
- max.poll.records:单次拉取最大记录数
- session.timeout.ms:消费者会话超时时间
- heartbeat.interval.ms:心跳间隔时间
高级主题
消费模式选择指南
- 严格顺序场景:单线程或单消费者单分区
- 高吞吐场景:消费组模式+多消费者
- 特殊路由需求:独立消费者模式
常见问题解决方案
问题1:消费滞后严重
- 增加消费者实例
- 优化消费逻辑处理速度
- 调整fetch参数增大吞吐量
问题2:频繁再平衡
- 调整session.timeout.ms
- 确保消费者及时发送心跳
- 避免长时间的处理阻塞
问题3:重复消费
- 确保幂等性处理
- 合理设置auto.commit.interval.ms
- 考虑手动提交偏移量
总结
Kafka消费者提供了灵活多样的消费模式,开发者应根据业务需求选择合适的方式:
- 对于简单场景,单线程消费足够使用
- 需要精确控制分区时,考虑独立消费者模式
- 大多数生产环境推荐使用消费组模式,具备良好的扩展性和容错性
理解这些消费模式的底层原理和适用场景,能够帮助开发者构建更加健壮高效的消息处理系统。JCSprout项目中的实践表明,合理的消费者设计可以显著提升系统整体的吞吐量和可靠性。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











