






Mobile-Deep-Learning项目C++推理开发全流程指南
Paddle-Lite  项目地址: https://gitcode.com/gh_mirrors/pad/Paddle-Lite
项目地址: https://gitcode.com/gh_mirrors/pad/Paddle-Lite
项目概述
Mobile-Deep-Learning是一个面向移动端优化的深度学习推理框架,它提供了高效的C++ API接口,能够在移动设备上快速部署和运行深度学习模型。本文将详细介绍如何使用该框架的C++接口完成从模型准备到实际推理的全流程开发。
核心推理流程
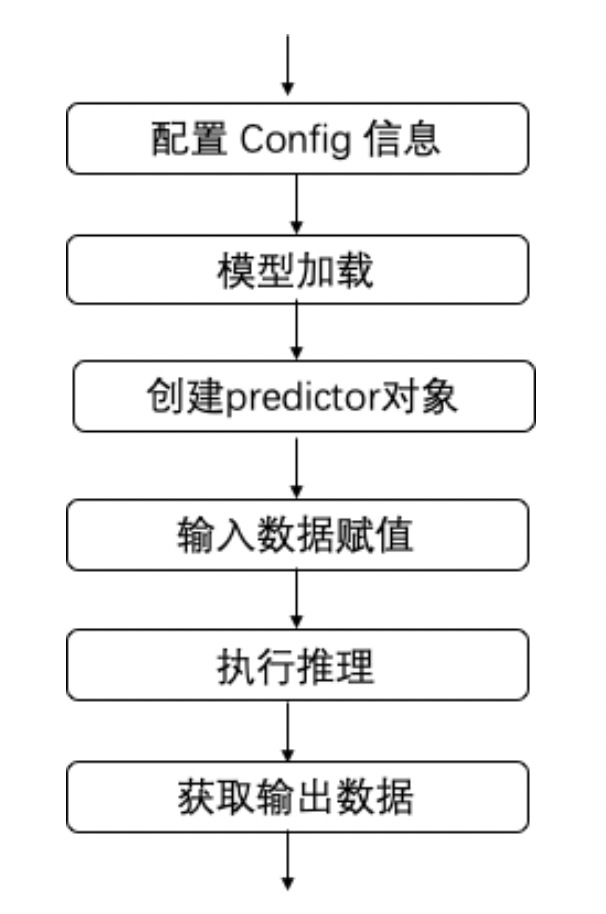
Mobile-Deep-Learning的C++推理流程包含以下关键步骤:
- 配置阶段:创建并设置MobileConfig对象,指定模型路径和设备环境参数
- 预测器创建:基于配置创建PaddlePredictor对象,完成模型加载和初始化
- 输入处理:获取输入Tensor并填充预处理后的数据
- 执行推理:调用Run方法执行模型计算
- 输出解析:获取输出Tensor并解析推理结果
详细开发指南
1. 环境准备
开发前需要准备:
- 配置好的开发环境(推荐使用Docker容器)
- Android设备及ADB调试工具
- 交叉编译工具链(针对移动端开发)
2. 基础API使用
2.1 头文件引入
#include "paddle_api.h" // 核心头文件
using namespace paddle::lite_api; // 命名空间
2.2 预测器创建
// 配置对象
MobileConfig config;
config.set_model_from_file("model.nb"); // 设置模型路径
// 创建预测器
std::shared_ptr<PaddlePredictor> predictor =
CreatePaddlePredictor<MobileConfig>(config);
2.3 输入输出处理
// 输入处理
auto input_tensor = predictor->GetInput(0);
input_tensor->Resize({1, 3, 224, 224}); // 设置输入维度
auto* data = input_tensor->mutable_data<float>(); // 获取数据指针
// 填充输入数据...
// 执行推理
predictor->Run();
// 输出获取
auto output_tensor = predictor->GetOutput(0);
const float* result = output_tensor->data<float>(); // 获取输出数据
3. 完整示例:MobileNet分类模型
3.1 模型准备
- 下载原始模型:
wget http://paddle-inference-dist.bj.bcebos.com/mobilenet_v1.tar.gz
tar zxf mobilenet_v1.tar.gz
- 模型转换(使用opt工具):
./opt --model_dir=./mobilenet_v1 \
--optimize_out_type=naive_buffer \
--optimize_out=./mobilenet_v1_opt
3.2 编译部署
- 编译可执行文件:
cd mobile_light
make # 生成mobilenetv1_light_api
- 推送文件到设备:
adb push mobilenet_v1_opt.nb /data/local/tmp
adb push libpaddle_light_api_shared.so /data/local/tmp
adb push mobilenetv1_light_api /data/local/tmp
3.3 执行推理
adb shell 'cd /data/local/tmp && \
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data/local/tmp && \
./mobilenetv1_light_api mobilenet_v1_opt.nb'
典型输出示例:
======= benchmark summary =======
input_shape(NCHW):1 3 224 224
model_dir:mobilenet_v1_opt.nb
avg_duration:33.7388ms
====== output summary ======
output tensor 0 mean value:0.001
4. 进阶应用示例
4.1 图像分类完整流程
// 图像预处理
cv::Mat image = cv::imread("test.jpg");
cv::resize(image, image, cv::Size(224, 224));
image.convertTo(image, CV_32FC3, 1.0/255.0);
// 填充Tensor
auto input_tensor = predictor->GetInput(0);
float* data = input_tensor->mutable_data<float>();
for (int i = 0; i < image.total(); ++i) {
data[i] = image.at<cv::Vec3f>(i)[0]; // B
data[i+image.total()] = image.at<cv::Vec3f>(i)[1]; // G
data[i+2*image.total()] = image.at<cv::Vec3f>(i)[2]; // R
}
4.2 目标检测应用
目标检测模型的输出解析示例:
auto output_tensor = predictor->GetOutput(0);
const float* result = output_tensor->data<float>();
// 解析检测结果
for (int i = 0; i < num_detections; ++i) {
float score = result[i*6 + 1];
if (score > threshold) {
int class_id = static_cast<int>(result[i*6]);
float xmin = result[i*6 + 2];
float ymin = result[i*6 + 3];
float xmax = result[i*6 + 4];
float ymax = result[i*6 + 5];
// 绘制检测框...
}
}
性能优化建议
-
模型优化:
- 使用最新的opt工具进行模型优化
- 根据目标硬件选择合适的数据精度(FP32/FP16/INT8)
-
预处理优化:
- 使用多线程进行图像预处理
- 尽量在Native层完成预处理,避免数据拷贝
-
推理优化:
- 合理设置线程数(MobileConfig::set_threads)
- 使用Warmup机制消除首次推理延迟
常见问题排查
-
模型加载失败:
- 检查模型路径是否正确
- 确认模型是否经过正确的优化转换
-
输入输出不匹配:
- 检查输入Tensor的shape是否与模型要求一致
- 验证输入数据范围是否符合模型要求
-
性能问题:
- 使用性能分析工具定位瓶颈
- 检查是否启用了硬件加速(如GPU/NPU)
通过本文的详细指南,开发者可以快速掌握Mobile-Deep-Learning框架的C++接口使用方法,并在移动设备上高效部署深度学习模型。
Paddle-Lite 项目地址: https://gitcode.com/gh_mirrors/pad/Paddle-Lite
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考




















 4657
4657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











