






MMPose混合数据集训练指南:高效融合COCO与AIC数据集
 项目地址: https://gitcode.com/gh_mirrors/mm/mmpose
项目地址: https://gitcode.com/gh_mirrors/mm/mmpose 混合数据集训练概述
在计算机视觉领域,姿态估计模型的性能往往依赖于训练数据的多样性和规模。MMPose作为先进的姿态估计框架,提供了强大的混合数据集训练功能,允许开发者将多个不同来源的数据集合并使用,从而提升模型的泛化能力和鲁棒性。
混合数据集的核心机制
MMPose通过CombinedDataset这一精巧设计的工具实现混合数据集训练。其核心工作原理如下:
- 数据格式统一化:将不同来源的数据集转换为统一的内部格式
- 关键点映射转换:处理不同数据集间关键点定义和顺序的差异
- 采样策略控制:灵活调整各数据集的采样比例
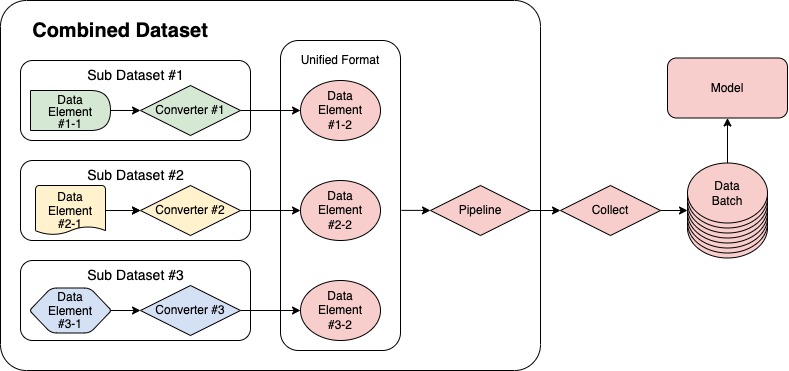
典型应用场景:COCO与AIC数据集融合
数据集差异分析
COCO和AIC都是广泛使用的人体2D姿态数据集,但存在显著差异:
- 关键点数量:COCO定义17个关键点,AIC定义14个关键点
- 关键点顺序:相同部位的关键点在不同数据集中的索引不同
- 特有标注:COCO包含面部关键点,AIC包含头顶和颈部关键点

融合方案一:AIC合并到COCO(保留COCO格式)
适用场景
当开发者希望增强模型在COCO数据集上的表现时,可采用此方案。AIC数据集作为辅助数据源,仅保留与COCO共有的关键点。
实现步骤
- COCO数据集配置:保持原始格式不变
dataset_coco = dict(
type='CocoDataset',
data_root='data/coco/',
ann_file='annotations/person_keypoints_train2017.json',
data_prefix=dict(img='train2017/'),
pipeline=[], # 保持空管道
)
- AIC数据集转换:使用KeypointConverter转换关键点索引
dataset_aic = dict(
type='AicDataset',
pipeline=[
dict(
type='KeypointConverter',
num_keypoints=17, # 与COCO一致
mapping=[ # AIC索引到COCO索引的映射
(0, 6), (1, 8), (2, 10), (3, 5),
(4, 7), (5, 9), (6, 12), (7, 14),
(8, 16), (9, 11), (10, 13), (11, 15)
])
],
)
- 组合数据集配置:设置采样比例和元信息
dataset = dict(
type='CombinedDataset',
metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
datasets=[dataset_coco, dataset_aic],
pipeline=train_pipeline,
sample_ratio_factor=[1.0, 0.5] # COCO全量,AIC采样50%
)
融合方案二:COCO与AIC完全合并(创建新格式)
适用场景
当开发者希望充分利用两个数据集的所有标注信息时,可采用此方案。合并后的数据集包含19个关键点。
实现步骤
-
关键点集合并:创建包含两个数据集所有关键点的统一集合

-
数据集转换配置
# COCO转换配置
dataset_coco = dict(
type='CocoDataset',
pipeline=[
dict(
type='KeypointConverter',
num_keypoints=19, # 合并后的关键点总数
mapping=[(0,0), (1,1), ..., (16,16)] # 保持原有顺序
)
])
# AIC转换配置
dataset_aic = dict(
type='AicDataset',
pipeline=[
dict(
type='KeypointConverter',
num_keypoints=19,
mapping=[
(0,6), ..., (12,17), (13,18) # 映射到新索引
])
],
)
- 创建新的元信息文件:定义合并后的关键点信息
# coco_aic.py
keypoint_info = [
# 包含COCO原有17个关键点
dict(name='head_top', id=17, color=[255,128,0], type='upper', swap=''),
dict(name='neck', id=18, color=[255,128,0], type='upper', swap='')
]
- 组合数据集配置
dataset = dict(
type='CombinedDataset',
metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
datasets=[dataset_coco, dataset_aic],
pipeline=train_pipeline
)
高级技巧:采样策略优化
混合数据集训练中,合理的采样策略对模型性能至关重要。MMPose提供两种采样控制方式:
1. 数据集级采样控制
通过sample_ratio_factor参数调整:
sample_ratio_factor=[1.0, 0.5] # 第一个数据集全量,第二个采样50%
2. 批次级采样控制
使用MultiSourceSampler实现更精细的控制:
train_dataloader = dict(
sampler=dict(
type='MultiSourceSampler',
source_ratio=[1.0, 0.5], # 批次中数据比例
shuffle=True
)
)
实践建议
- 评估目标优先:根据最终评估的数据集选择合并策略
- 渐进式实验:从小比例混合开始,逐步调整
- 监控关键指标:分别跟踪模型在各数据集验证集上的表现
- 资源优化:大数据集可采用较低采样率,平衡训练效率
通过合理利用MMPose的混合数据集功能,开发者可以显著提升姿态估计模型的泛化能力,特别是在目标场景数据不足的情况下,这一技术显得尤为重要。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











