






Dinky项目中的CDCSOURCE整库同步技术解析
 项目地址: https://gitcode.com/gh_mirrors/di/dinky
项目地址: https://gitcode.com/gh_mirrors/di/dinky 概述
在现代数据架构中,实时数据同步是构建数据仓库和数据湖的关键环节。Dinky项目提供的CDCSOURCE整库同步功能,通过创新的技术手段解决了传统FlinkCDC实现中的诸多痛点,为数据集成提供了高效可靠的解决方案。
传统方案的局限性
在传统使用FlinkCDC进行数据同步时,通常会遇到以下问题:
- 资源消耗大:每个表都需要独立的CDC连接,导致数据库连接数激增
- 开发效率低:需要为每张表编写大量DDL和INSERT语句
- 维护成本高:表结构变更时需要同步修改大量代码
- 网络压力大:重复读取Binlog造成不必要的网络带宽消耗
Dinky CDCSOURCE的核心优势
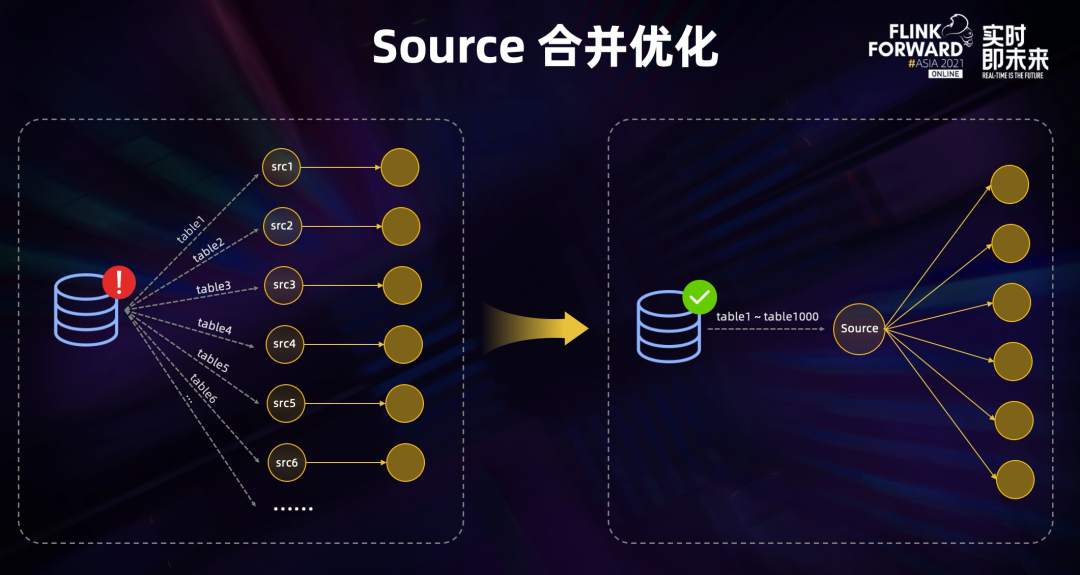
1. 源表合并技术
Dinky采用智能的source合并策略,将同一数据源的所有表合并为一个source节点。这种设计带来了显著优势:
- 大幅减少数据库连接数,降低源库压力
- 避免重复读取Binlog,节省网络带宽
- 统一管理数据流,提高任务稳定性
2. 元数据自动映射
Dinky利用内置的元数据管理功能,自动捕获源库表结构并生成对应的Flink DDL。这一特性:
- 简化开发流程,无需手动编写DDL
- 自动适应表结构变更
- 支持复杂数据类型映射
3. 灵活的Sink支持
Dinky提供了多样化的数据输出方式:
- 多种Sink类型:支持Kafka、Doris、Hudi、JDBC等多种目标
- 两种实现方式:
- 基于DataStream API的扩展实现(以datastream-前缀标识)
- 基于FlinkSQL的原生实现
- 表名转换:支持前缀、后缀、大小写转换等灵活配置
实战指南
基本语法结构
EXECUTE CDCSOURCE jobname
WITH ( key1=val1, key2=val2, ...)
关键配置参数
| 分类 | 重要参数 | 说明 | |------|---------|------| | 源配置 | connector | 数据源类型(mysql-cdc/oracle-cdc) | | | hostname | 数据库服务器地址 | | | table-name | 支持正则表达式的表名匹配 | | 任务配置 | checkpoint | 检查点间隔(毫秒) | | | parallelism | 任务并行度 | | Sink配置 | sink.connector | Sink类型标识 | | | sink.table.prefix | 目标表名前缀 | | | sink.* | 目标数据源特有配置 |
典型应用场景示例
场景1:全库同步到Kafka单一Topic
EXECUTE CDCSOURCE kafka_sync WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql-prod',
'port' = '3306',
'username' = 'sync_user',
'password' = 'secure_pwd',
'table-name' = 'db1\..*', -- 同步db1下所有表
'sink.connector'='datastream-kafka',
'sink.topic'='cdc_events',
'sink.brokers'='kafka:9092'
)
场景2:分表同步到Doris数据仓库
EXECUTE CDCSOURCE doris_ods WITH (
'connector' = 'mysql-cdc',
'hostname' = 'mysql-prod',
'scan.startup.mode' = 'initial', -- 全量+增量
'table-name' = 'order_db\.orders,user_db\.customers',
'sink.connector' = 'datastream-doris',
'sink.fenodes' = 'doris-fe:8030',
'sink.sink.db' = 'ods_layer',
'sink.table.prefix' = 'ODS_',
'sink.sink.enable-delete' = 'true' -- 支持删除操作同步
)
场景3:实时入湖到Hudi
EXECUTE CDCSOURCE hudi_sync WITH (
'connector' = 'mysql-cdc',
'database-name' = 'operational_db',
'sink.connector'='hudi',
'sink.path'='hdfs://ns1/data/hudi/${tableName}',
'sink.hive_sync.enable'='true', -- 自动同步到Hive
'sink.hive_sync.table'='${tableName}',
'sink.table.type'='COPY_ON_WRITE' -- 写时复制模式
)
最佳实践建议
- 资源规划:根据表数量和变更频率合理设置并行度
- 检查点配置:生产环境建议设置10-30秒的检查点间隔
- 命名规范:利用prefix/suffix建立清晰的数据分层
- 监控策略:关注source合并后的延迟指标
- 异常处理:合理配置重试策略和错误处理机制
注意事项
- 当前版本不支持Application模式部署
- 配置项中的逗号前不能有空格
- 每个任务只能包含一个CDCSOURCE语句
- 复杂正则表达式需要正确转义
Dinky的CDCSOURCE功能通过创新的架构设计,大幅简化了实时数据同步任务的开发和维护工作,是构建现代数据管道的有力工具。随着项目的持续发展,未来将支持更多数据源和更丰富的功能特性。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











