



运行时代码多态性作为对侧信道攻击的保护
1 引言
侧信道攻击是一种通过观察与安全活动相关的物理现象来恢复秘密的有效手段。根据对被攻击程序的了解(例如高级加密标准密码),攻击者将尝试在观测轨迹与关于秘密计算过程中使用的中间值假设(例如第一次S盒计算的输出)之间建立相关性。然后,利用提供最佳相关值的假设来恢复秘密(例如AES密钥的值)。通常,在观测轨迹中的少数几个点会显示出与假设较高的相关值,这些点对应于leakagepoint,即秘密在计算过程中可被观察到的时间点。
两种主要的防护方案可有效抵御侧信道攻击:隐藏和掩码。掩码的核心思想是将安全计算中的敏感值拆分为多个份额,以打破观测结果与假设中间值之间的相关性。要从掩码实现中恢复密钥,且在各份额于不同时刻计算的前提下,攻击者需要进行高阶相关性分析,即同时涉及多个观测点的分析。然而,高阶攻击的计算复杂度随攻击阶数呈指数增长,因此在实际中更难实施。隐藏则是通过在时间上(在安全操作期间)和空间上(芯片上的操作位置)移动信息泄露点,并减小可观测泄露的幅度来实现防护。实际上,侧信道相关性分析依赖于对目标精确的空间和时间控制,而攻击的有效性与观测信号中空间和时间变化的程度密切相关[13]。将泄露点分散到多次执行的不同时间和位置,将显著降低攻击的有效性,需要更多的观测轨迹和/或更强大的分析手段才能恢复密钥。在实践中,针对侧信道攻击的鲁棒性通常通过结合隐藏和掩码两种防护措施来实现。
我们将多态性定义为在运行时定期改变安全组件的行为而不改变其功能属性的能力。通过修改被攻击目标观测的时间和空间特性,多态性增加了在侧信道攻击中执行相关性分析的难度。因此,它可以被视为一种隐藏类防护措施。
非确定性处理器[15]实现了我们称之为多态执行的功能,即从程序内存中的静态二进制输入对程序进行混洗执行。May等人实现了动态指令混洗[15]和随机寄存器重命名[14]。Bayrak等人[6]描述了一种指令混洗器:一种位于处理器与程序内存(指令缓存)之间的专用IP。如今,许多安全元件集成了类似功能,以去同步化观测轨迹并降低信噪比。专用硬件设计在提高安全性与性能比方面表现更优,但成本更高。随着物联网市场的快速增长,纯软件解决方案具有吸引力,因为它们可以更容易地适配各种产品架构,并且具备可升级性。
仅通过软件手段,[1,10]提出编译一个包含多个功能等效执行路径的程序,其中在运行时随机选择一条执行路径。该方法以增加程序大小为代价,降低了执行时间的开销。据我们所知,Amarilli等人[3]是首次利用代码变体编译来防御侧信道攻击的研究者。借助修改后的静态编译器,在每次执行前生成一个新的程序版本,以在运行时打乱指令和基本块。他们的方法被证明可使AES上的差分功率分析所需跟踪数量增加20倍。Agosta等人[2]的工作是与我们的研究最接近的
他们提出了一种代码变形运行时框架,该框架涉及寄存器重命名、指令混排以及生成语义等价代码片段。
本文中,多态性通过由随机数据驱动的运行时代码生成来实现。其核心思想是在目标设备上定期生成受保护二进制代码的新版本。每个程序版本在功能上等价,但其实现方式不同,从而使得每次执行都会导致不同的观察结果。该多态代码生成器由一个针对嵌入式系统约束条件优化的运行时代码生成框架生成(第2节)。我们详细描述了用于在生成代码中引入可变性的机制,包括随机选择寄存器、随机选取语义等价的指令、指令重排序以及插入噪声指令。我们对所提出方法在AES软件实现上抵御相关性功耗分析(CPA)的有效性进行了实验评估,并表明其执行时间和代码大小开销与资源受限的嵌入式目标的内存和计算能力相兼容(第3节)。我们在第4节介绍了相关工作,并在第5节给出结论。
2 面向嵌入式系统的运行时代码多态性
2.1 deGoal 概述
deGoal 是一个用于运行时代码生成的框架。其最初的动机是利用运行时代码特化来提升程序性能,例如执行时间、能耗或内存占用。在本节中,我们首先概述 deGoal 的特性,然后介绍我们如何将其扩展以用于安全性目的。
在传统的运行时代码生成框架(如解释器和动态编译器)中,目标是提供一个受编程语言语法和语义定义约束的通用代码生成基础设施。这类解决方案的通用性带来了较高的运行时代码生成开销,体现在内存占用、计算时间和计算能耗方面。在deGoal中,采用了一种不同的方法:代码段(此后称为内核)由专用运行时代码生成器(称为编译单元)在运行时生成并调优。每个编译单元专门用于生成一个内核的机器代码。语法和语义分析在静态编译阶段完成,而编译单元仅嵌入所选运行时优化所需的处理知识。因此,编译单元能够实现极快的代码生成速度(比典型的运行时代码解释或动态编译框架快10到100倍),具有低内存占用,可在小型微控制器架构(如8/16位微控制器)[5],上运行,并且可移植[8]。
应用程序的构建与执行使用deGoal包含以下步骤,如图1所示:使用混合方式编写
C源代码和专用的cdg语言;编译应用程序的二进制代码和编译单元的二进制代码;在运行时,通过编译单元生成内核的二进制代码,最后运行内核。
Cdg是一种类似汇编的领域特定语言。从程序员的角度来看,它代表了一种主要的范式转变:Cdg表达式描述的是将在运行时生成的机器代码,而不是待执行的指令。编译单元通过结合ANSIC和Cdg表达式来实现。C语言用于描述编译单元中的控制部分,该部分将驱动代码生成,而Cdg表达式则执行代码生成。Cdg指令集包含一个变长寄存器集,可由程序员进行扩展。基于这一高级指令集,编译单元会根据以下因素将Cdg表达式映射为机器代码:(1)待处理数据的特性,(2)代码生成时的执行环境特性,(3)目标处理器的硬件能力,(4)执行时间和/或能耗性能指标。在所有情况下,代码生成速度快,生成的代码高效,并适用于微控制器等低资源嵌入式系统[5]。
2.2 一个多态SubBytes函数
本节通过高级加密标准的SubBytes函数的实现作为deGoal的教程介绍deGoal,随后详细介绍运行时代码生成的内部机制。这也是我们在实验中使用的受保护的实现(第3节)。
代码生成器使用Cdg实现,与任何在deGoal中设计的代码生成器一样。在此阶段,多态代码生成是代码生成框架提供的功能,无需程序员显式控制。在清单1.1中,函数gensubBytes是一个标准C函数,其实现会在静态编译前从 Cdg翻译为普通C源代码。
1 void gen_subBytes ( cdg_insn_t * code ,
2 uint8_t * sbox_addr , uint8_t * state_addr )
3 {
4 #[
5 前奏
6 类型 uint32 int 32
7 分配 uint32 state , sbox , i , x , y
8 mv state , #( state_addr )
9 mv sbox , #( sbox_addr )
10 mv i , #(0)
11 循环 :
12 lb x, @( state +i) // x := state [i]
13 lb y, @( sbox +x) // y := sbox [x]
14 sb @(state+ i), y // state [i]:=y
15 add i , i , #(1)
16 bneq 循环 , i , #(16)
17 返回
18 结束
19 ]#;
20 }
deGoal允许在#[和]#分隔符之间混合用于代码生成的Cdg表达式和C代码。此外,C表达式可以使用#( )括起来插入到Cdg表达式中;这些表达式将在代码生成时(即编译单元执行时)进行求值。SubBytes例程的程序代码被写入变量 code所包含地址的内存缓冲区中(第1行和第5行)。第6–7行声明了类型化变量的实例化,这些变量将在运行时代码生成期间映射到物理寄存器。变量 state和sbox分别存储高级加密标准状态的地址和S盒的地址(C变量 state_addr和sbox_addr,第2行)。一个标签(loop,第11行)定义了对16 个状态字节循环的起始位置。变量i存储循环索引,它在第10行初始化,并作为加载和存储指令的偏移值使用(分别在第12行和第14行),其中@(a+k)的表示法(第12至14行)表示对存储在变量a中的地址进行间接内存访问,并由地址变量k进行偏移。S盒替换在第14行生成,其中临时变量y被加载为地址sbox偏移 x处的内存内容。Cdg指令rtn(第17行)生成SubBytes例程的终止代码,而 Cdg指令End(第18行)终止代码生成:它刷新指令调度器中剩余的活动指令(第2.3节),并发出向后分支的机器代码,这些分支的目标地址无法在第一次代码生成过程中计算得出(本文未详细说明)。
2.3 使用deGoal实现代码多态性
在这项工作中,我们重新调整了deGoal的原始目标,以专注于安全性方面:我们利用deGoal在运行时代码中提供的灵活性
输入:可用寄存器列表 free输出:更新后的可用寄存器列表 free输出:分配的物理寄存器的id reg从可用寄存器列表中获取一个随机寄存器l ←Length(free)i ← Rand(0, l − 1)reg ← free[i]从空闲寄存器列表中移除寄存器 ifree ← Delete(free, i)算法1. 随机寄存器分配
生成以实现运行时代码多态性。由多态代码生成器生成的程序代码此后称为多态实例。
寄存器分配。 在动态编译器中,指令选择和指令调度通常在寄存器分配之前执行[12]。尽管动态编译器中使用的分配技术(如线性扫描)[17],与静态编译器中常用的图着色相比具有较低的计算开销,但它们仍然超出了我们目标平台可用计算能力的范围。因此,在一个编译单元中,寄存器分配首先通过贪心算法(算法 1)在指令调度之前完成。我们的目的是减轻指令选择和指令调度的压力:如果先进行寄存器分配,就可以从更简单的中间表示进行指令调度:我们的分配器只需维护一份可用空闲寄存器的列表即可。
Instruction Selection. 指令选择在寄存器分配之后进行,原因如前所述。指令选择在Cdg表达式级别上执行:根据目标处理器架构和代码生成选项(例如,倾向于代码紧凑性或代码执行时间),每个表达式可以映射到一个或多个机器指令。指令选择通过由随机值驱动的switch … case段来实现。为了实现代码多态性,我们引入了额外的变体,以提供更多的多态性机会。本文实验中使用的、可能由指令选择选取的语义等价形式如下所述(r表示一个随机值):
c := a异或b <=> c :=((a异或r)异或b)异或r
c := a异或b <=> c :=(a或b)异或(a与b)
c := a减b <=>k := 1; c:=(a + k)+非b
c := a减b <=>c :=((a + r)减b)减r
我们强调,尽管在当前实验中为随机指令选择引入的语义变体数量较少,但添加
指令缓冲区 B(一个循环缓冲区) 输入:要插入的指令 I 输出: B 从缓冲区最后一条指令开始查找插入槽位 pos ← Tail(B) 当 I has no data dependence with B[pos]成立时执行 pos ← Prev( B[pos]) 结束 随机插入新指令 i ← Rand(pos, Tail(B)) B ← 将 I 插入到 B 的位置 i 如果 B 已满,则刷新第一条指令 如果 Prev(Head(B)) is equal to Tail(B)则 发出Head(B)处的指令 Head(B) ←Next(Head(B)) 结束 算法2. 指令混排
新的指令变体只会对嵌入到目标平台上的代码生成库的内存占用产生影响,而不会影响代码生成的执行时间。换句话说,增加选择变体将增大指令选择中使用的switch … case段的大小,但不会影响从switch表达式分支到其中一个case的性能。
指令调度。 上述的指令选择过程会在一个有界有序指令缓冲区中生成指令,该缓冲区的行为类似于先进先出队列。在此阶段,指令缓冲区包含机器指令编码以及对defs和uses寄存器(即被修改和被读取的寄存器)的描述。该指令缓冲区采用双向链表实现。这显然会增加数据结构的操作开销,但我们选择这种实现在于最大化插入机会,而非执行效率。实验部分表明,多态代码生成的性能仍然良好。
在传统编译器中,指令调度旨在提高代码执行的性能:通过在程序内存中对机器指令进行排序,以最小化执行时间,特别是处理器空闲周期的数量。调度的难点在于,在不破坏原始源程序语义的前提下,找到机器指令的可能最优排序。为实现这一点,需要考虑资源约束、控制依赖和数据依赖。
在代码多态性的情况下,我们的目标是利用调度机会生成同一源程序的多个变体,所有变体均功能等价且语义正确。因此,代码性能只是次要考虑因素,我们关注的是影响代码正确性的资源约束,但
而不是那些仅影响程序性能的。指令调度通过一次完成(算法2):每次将新指令插入指令缓冲区时,首先通过比较该插入指令与已存储在缓冲区中指令的定义与使用,计算出可能的插入槽位列表。接着,在先前确定的插入槽位列表中随机选择插入位置。如果未找到插入槽位,则将新指令追加到指令缓冲区的结束处。如果指令缓冲区已满,则将其第一个指令发射到程序内存中,以释放一个指令槽位。
流水线冲突[16],仅影响程序性能而不影响程序正确性,在我们的调度策略中未予考虑。我们主要目的是减轻调度的计算开销,但这一选择还带来了另一个有趣的效果:处理器停顿——作为流水线冲突在程序执行过程中的一种可观测效应——可能会在程序执行的观察中增加额外的时间变化来源。为了实现快速代码生成,控制依赖约束通过将控制指令视为调度屏障来简单处理:当遇到控制指令时,整个指令缓冲区将被清空。
插入噪声指令。 在插入新指令之前(第2.3节),噪声指令被追加到指令缓冲区的结束位置。n以概率 p插入噪声指令,其中 n来自可配置的均匀离散分布[1; N]。如有需要,将从空闲寄存器列表中随机选择额外寄存器。若无可用寄存器,则随机选择寄存器,并在使用前后将其压入和弹出栈。可插入多种类型的指令:在单个处理器周期内执行的核心算术指令(例如整数运算add或sub),或在多个处理器周期内执行的指令(例如在ARM Cortex‐M核心上执行的乘加运算 mla),以及对数据表的内存访问(例如用户可能提供的S盒查找表)。
代码生成间隔。 它与相对于执行次数的新的多态实例的生成频率相关(公式1)。ω是一个无单位的值,位于[1;+∞[。当 ω= 1时,在每次执行前都会生成一个新的多态实例;如果 ω →+∞,则仅在启动时生成一次多态实例,这等同于使用静态生成的代码。我们的假设是, ω越接近1,物理攻击就越困难,因为两次执行的观察结果相关的概率更低。另一方面,代码生成所带来的开销随着 ω的减小而增加。
$$
ω= \frac{\text{nb. executions}}{\text{nb. code generations}} \tag{1}
$$
而不是那些仅影响程序性能的。指令调度通过一次完成(算法2):每次将新指令插入指令缓冲区时,首先通过比较该插入指令与已存储在缓冲区中指令的定义与使用,计算出可能的插入槽位列表。接着,在先前确定的插入槽位列表中随机选择插入位置。如果未找到插入槽位,则将新指令追加到指令缓冲区的结束处。如果指令缓冲区已满,则将其第一个指令发射到程序内存中,以释放一个指令槽位。
流水线冲突[16],仅影响程序性能而不影响程序正确性,在我们的调度策略中未予考虑。我们主要目的是减轻调度的计算开销,但这一选择还带来了另一个有趣的效果:处理器停顿——作为流水线冲突在程序执行过程中的一种可观测效应——可能会在程序执行的观察中增加额外的时间变化来源。为了实现快速代码生成,控制依赖约束通过将控制指令视为调度屏障来简单处理:当遇到控制指令时,整个指令缓冲区将被清空。
插入噪声指令。 在插入新指令之前(第2.3节),噪声指令被追加到指令缓冲区的结束位置。n以概率 p插入噪声指令,其中 n来自可配置的均匀离散分布[1; N]。如有需要,将从空闲寄存器列表中随机选择额外寄存器。若无可用寄存器,则随机选择寄存器,并在使用前后将其压入和弹出栈。可插入多种类型的指令:在单个处理器周期内执行的核心算术指令(例如整数运算add或sub),或在多个处理器周期内执行的指令(例如在ARM Cortex‐M核心上执行的乘加运算 mla),以及对数据表的内存访问(例如用户可能提供的S盒查找表)。
代码生成间隔。 它与相对于执行次数的新的多态实例的生成频率相关(公式1)。ω是一个无单位的值,位于[1;+∞[。当 ω= 1时,在每次执行前都会生成一个新的多态实例;如果 ω →+∞,则仅在启动时生成一次多态实例,这等同于使用静态生成的代码。我们的假设是, ω越接近1,物理攻击就越困难,因为两次执行的观察结果相关的概率更低。另一方面,代码生成所带来的开销随着 ω的减小而增加。
$$
ω= \frac{\text{nb. executions}}{\text{nb. code generations}} \tag{1}
$$
3 实验评估
3.1 实验设置
我们使用了意法半导体的STM32VLDISCOVERY评估套件。该开发板配备了一个运行频率为24兆赫兹的Cortex‐M3内核,仅有128千字节闪存和8千字节内存,并且未配备硬件安全保护。所有二进制程序均由Code Sourcery提供的版本 4.8.1的arm‐none‐eabi GNU/gcc工具链生成,编译选项为‐O3 ‐static ‐ mthumb ‐mcpu=cortex‐m3。因此,我们将我们的实现与从目标编译器获得的最快的参考实现进行了比较。
旁道追踪使用2208A PicoScope获取,其具有200兆赫兹带宽和8位的垂直分辨率。我们使用Langer的电磁探头RF‐B 3‐2和Langer的PA 303前置放大器。采样采集以5亿样本/秒的速度在10000个样本的窗口内进行。
我们的参考实现是一个遵循NIST规范的无保护的8位AES实现,并且所有轮函数均由第2节中介绍的专门针对该AES实现的多态代码生成器在运行时于内存中生成。上述所有多态机制在代码生成器中均被激活。插入噪声指令的概率设置为 p= 1/8,插入的指令数量 n从均匀离散分布[1; 8]中选择。每执行 ω={1, 10, 100, 1000, 10000}次AES后可以生成一个新的多态实例,但在旁道攻击中我们使用最短的代码生成间隔 ω= 1。
3.2 攻击模型
我们在第一轮AES的SubBytes函数输出上执行攻击。与大多数将同步点设置在 AES加密开始处的一阶CPA分析不同,我们考虑的是攻击者能够在SubBytes函数开始时创建同步点的情况。为了便于测量轨迹的时间对齐,在板子上的 GPIO引脚生成一个触发信号,在SubBytes函数执行期间保持高电平。使用此设置进行安全性评估时条件更为严格,因为多态AddRoundKey函数的执行变异性不会对观测轨迹的变化产生影响。
代码生成器本身也可能成为攻击目标,即使它无法访问密钥的值。然而,此类攻击超出了本文的范围,留待未来工作研究。
3.3 相关性功耗分析
我们对未保护版本和受保护的实现都进行了首次阶数CPA攻击。我们使用汉明重量来建模电磁辐射
第一个SubBytes函数输出的一个字节。该分析针对所涉及密钥部分的每个可能的假设值,计算每条轨迹与模型之间的皮尔逊相关系数 ρ的样本估计 r。
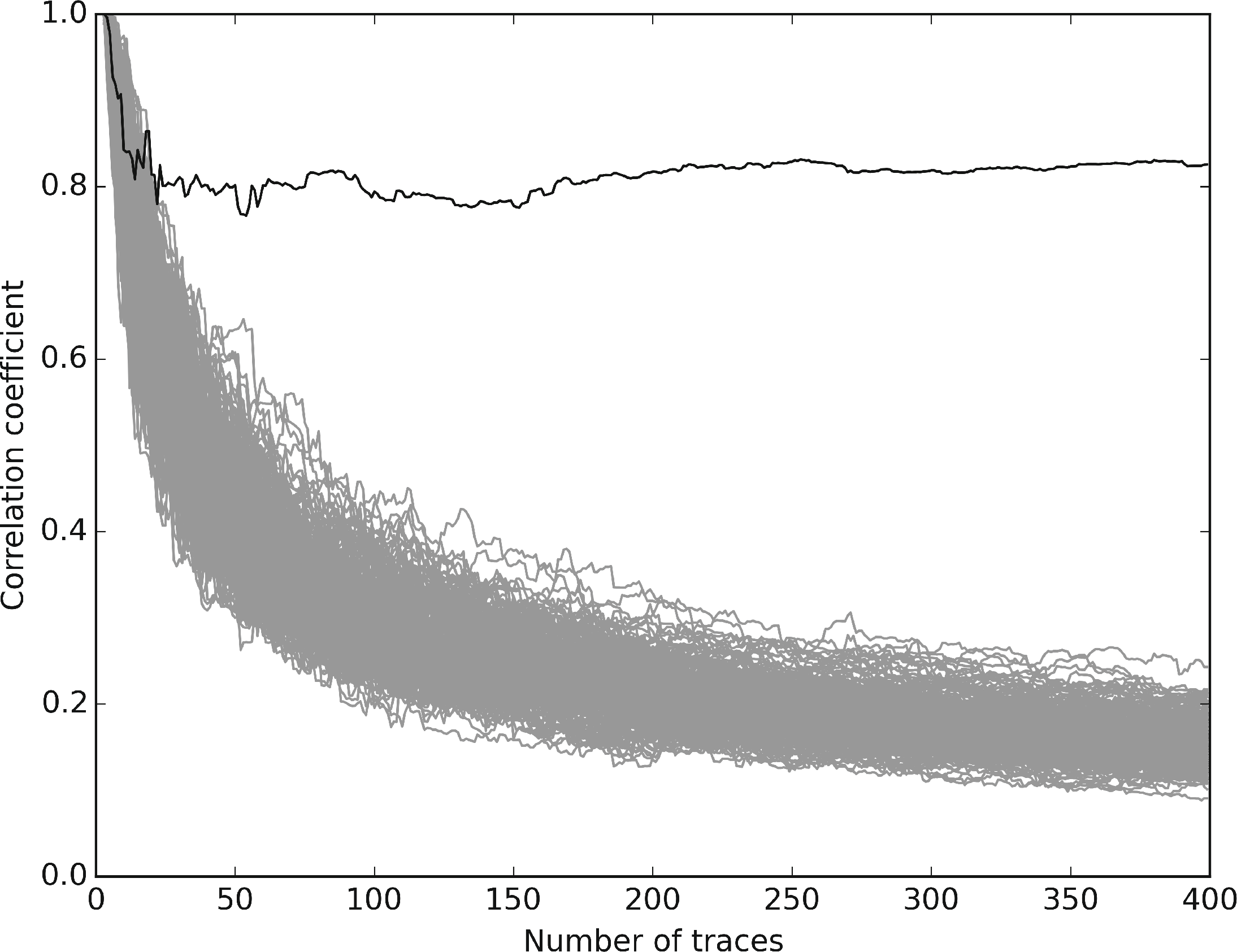
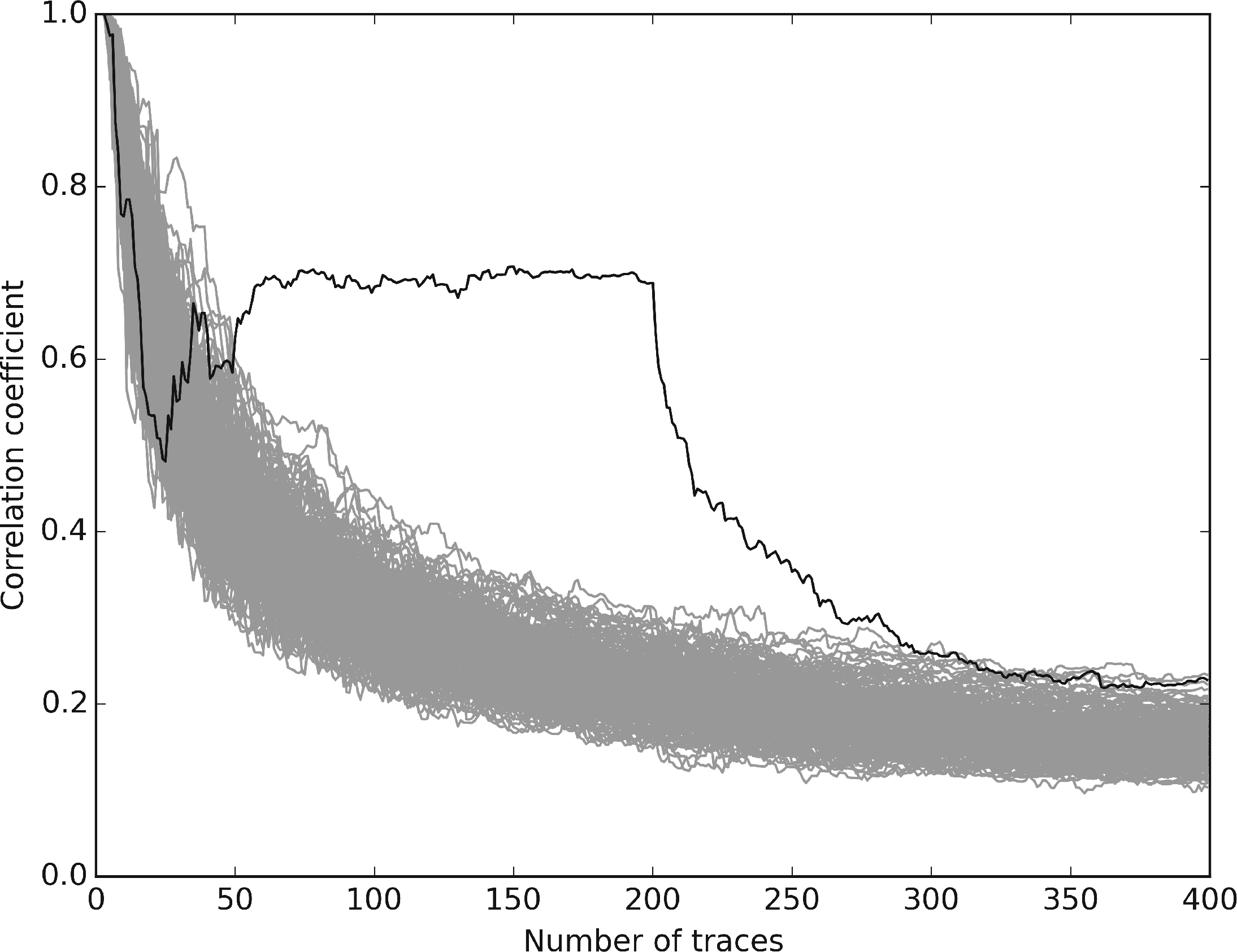
图2展示了我们对无保护的实现进行CPA攻击的结果。在获取35条轨迹后,正确密钥即与其他所有密钥假设区分开来,相关值高于0.8。该结果验证了实验设置以及相关性分析中所采用的汉明重量模型的合理性。作为多态性影响的一个示例说明,我们在图3中展示了针对我们的多态性实现进行CPA攻击的结果,其代码生成间隔为 ω= 200,即远高于从无保护的实现中恢复AES密钥所需的轨迹数量。在此情况下,前200条轨迹来自同一AES多态实例的执行,因此正确密钥假设的相关值明显区别于其他密钥假设。在200次执行之后,生成并执行一个新的多态实例,用于接下来的200次执行。多态性对相关轨迹的影响显而易见:在200条轨迹之后,正确密钥假设的相关性突然下降。在300条轨迹之后,正确密钥假设已无法与其他密钥假设区分,因为相关性分析混合了两个行为不同的 AES实例的执行轨迹。这也说明了在实际中,代码生成间隔 ω必须严格小于从未保护的实现中恢复密钥所需的轨迹数量。然而,该设置在很大程度上取决于目标的性质以及对无保护实现实施攻击的可行性。
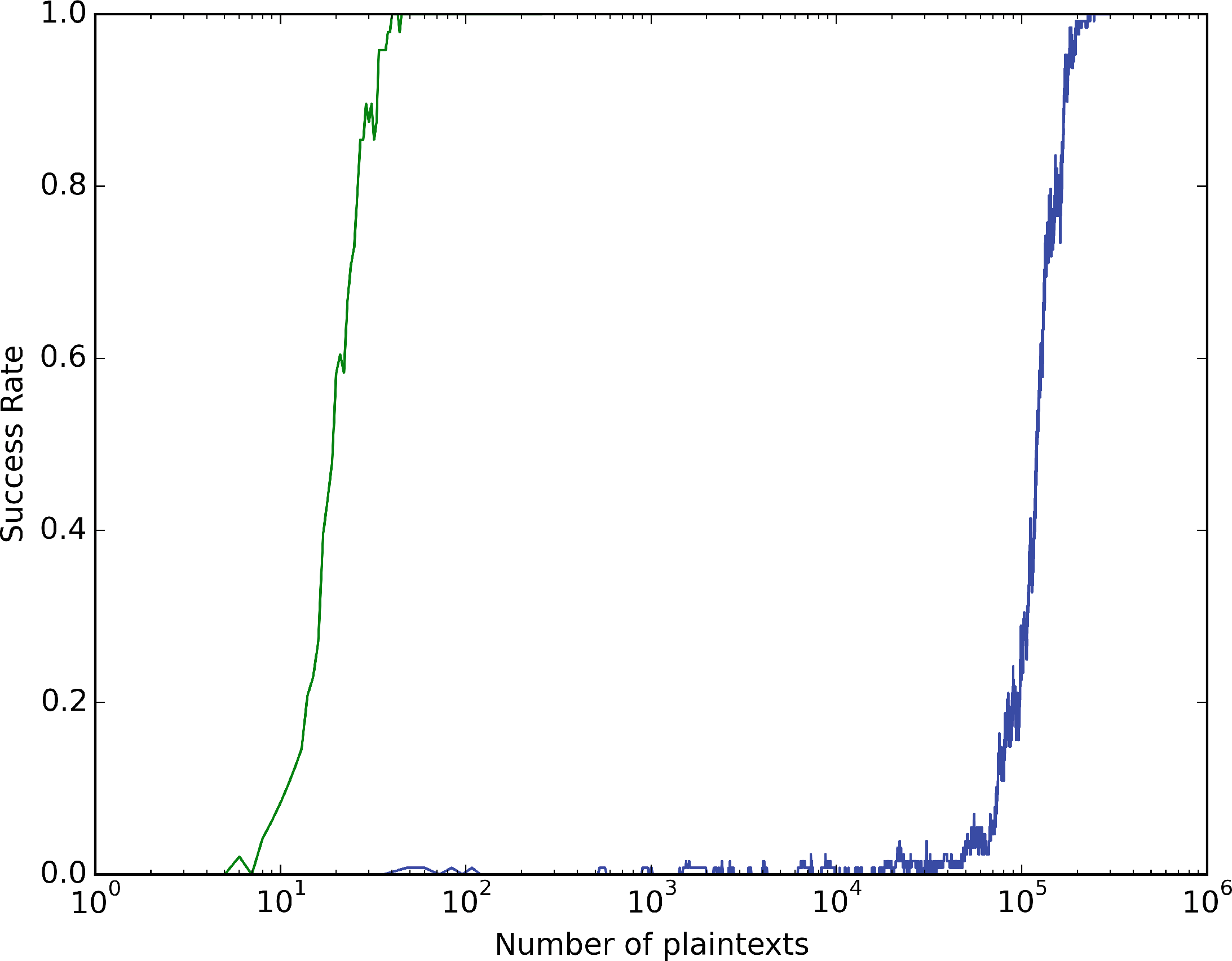
每次执行后生成新的多态实例(ω= 1)时,需要100000条迹才能以50%的成功率恢复密钥(图 4)。在120000条迹后达到100%成功率。
3.4 执行时间开销
为了估算我们的保护机制为参考实现增加的成本,我们测量了执行时间开销 k(公式2),其中 tref、 tgen和 tpoly分别表示参考的无保护实现、多态运行时代码生成以及多态实例的平均执行时间。我们对执行时间开销的度量考虑了由于执行多态实例(其代码相较于参考的无保护实现为次优代码)以及由于运行时代码生成所导致的执行时间增加。在此测量中,我们认为代码生成所产生的开销分布在 ω次运行中。
$$
k= \frac{t_{gen} + ω × t_{poly}}{ω × t_{ref}} \tag{2}
$$
表1比较了无保护的高级加密标准和多态高级加密标准若干变体的执行时间。在本节中,我们将所有轮函数均通过多态性进行保护的实现称为完整多态AES。未保护版本的执行时间为5320个处理器周期。我们观察了多态版本在 1024次运行中的执行时间。完整多态高级加密标准的执行时间为10487到 13696个处理器周期(平均12211 周期)。表1还说明了这样一个事实:如果仅对一个轮函数( AddRoundKey 或 SubBytes)使用多态性进行保护,则执行时间开销会降低。由于我们实验目标的微架构相对简单,未保护版本的执行时间在多次测量中完全稳定。然而,相比之下,多态版本的执行时间表现出显著的变化。考虑到未保护版本执行时间的稳定性,这种可变性只能归因于每个多态实例中的实现差异。
| 未保护版本 最小值 平均值 最大值 | 轮密钥加 小值 最大值 | 字节代换 小值 最大值 | 所有四个轮函数 小值 | 所有四个轮函数 小值 | 所有四个轮函数 小值 | |
|---|---|---|---|---|---|---|
| 5320 | Avg. | Avg. | Avg. | Max. | ||
| texe | 5320 5320 | 6340 10487 | 10487 15565 | 10894 205977 | 1166 2796269 | 70 2495850 |
| tgen | 0 |
表1。高级加密标准函数(texe)和代码生成器(tgen)在不同配置下1024次执行的执行时间(以周期为单位):未保护版本(未保护版本)、仅使用多态AddRoundKey函数的高级加密标准(轮密钥加)、仅使用多态SubBytes函数的高级加密标准(字节代换),以及所有四个轮函数均为多态的情况(所有四个轮函数)。
| 轮密钥加 最小值 平均值 最大值 | 字节代换 最小值 平均值 最大值 最 | 所有四个轮函数 小值 平均值 最大值 | |
|---|---|---|---|
| 20.10 22.94 26.16 | |||
| ω= 1 | 3.16 4.91 6.37 | 5.81 7.27 8.94 | |
| ω= 10 | 1.32 1.50 1.66 | 1.59 1.76 1.92 | 3.86 4.36 4.85 |
| ω= 100 | 1.09 1.16 1.22 | 1.16 1.21 1.25 | 2.17 2.50 2.78 |
| ω= 1000 | 1.09 1.13 1.18 | 1.16 1.15 1.20 | 2.17 2.32 2.59 |
| ω= 10000 | 1.05 1.12 1.18 | 1.11 1.15 1.19 | 1.99 2.30 2.58 |
表2。在与表1相同条件下高级加密标准的执行时间开销。参考对象是未保护版本,其运行时间为5320周期。
表2还说明了多态实例带来的开销 仅。对于较大的代码生成间隔(例如 ω= 10000),运行时代码生成在整个开销中的占比变得可以忽略不计,即开销仅代表执行多态实例的成本,相较于参考的无保护实现。实际上,多态实例的代码在执行时间方面效率较低,因为指令顺序被打乱,使用了次优(且更长)的代码序列,并执行了无用的指令。
3.5 内存占用
表3报告了我们工作的内存占用,包括代码生成器的大小以及为代码生成预留的内存大小。完整多态实现带来了16KB的程序大小开销,但可以通过对高级加密标准部分应用多态性来减少内存占用:如果仅轮密钥加和字节代换具有多态性,则内存开销仅为8KB。
| Text | 数据 BSS | 总计 | |
|---|---|---|---|
| 未保护版本 | 6144 40 | 772 2948 | 16956 1132 |
| 仅轮密钥加 | 8128 56 | 2948 | 10544 |
| 仅字节代换 | 7540 56 | 3980 | 15032 |
| 轮密钥加+字节代换 10964 88 | 6028 | 23100 | |
| 完整多态AES | 16984 88 |
表3. 以表1中所示相同变体运行无保护的高级加密标准和多态高级加密标准的完整程序的内存占用(单位:字节)1
4 相关工作
阿戈斯塔等人[2] 的工作与我们的研究最为接近:他们首次在一个运行时代码转换框架中整合了语义等效的代码序列、随机寄存器分配、指令混排和数组排列,以作为对抗侧信道攻击的保护措施。这些代码变换应用于基于OpenSSL的32位高级加密标准实现中的64个异或指令。由于所需跟踪数量较多
从无保护的实现中提取密钥(11600)时,可利用的代码生成间隔(介于100到 3000之间)高于我们的工作。多态性代码实例和代码生成器的执行时间分别为未保护的高级加密标准执行时间的 1.07×和 392.5×,并且报告了 ω= 100的开销为 5×。在我们的工作中,所有高级加密标准程序的指令均受到多态性保护,平均开销仅为 2.50×(针对 ω= 100);在最坏情况下( ω= 1),代码生成时间为参考未保护的高级加密标准执行时间的 23.9×。
其他研究提出了多态程序的设计,无需运行时代码生成的介入,而是通过随机选择功能等价的执行路径来实现。博莱等人[7]描述了针对Java卡的旁道逆向工程保护方法。该方法适用于虚拟机中的解释器;它描述了在虚拟机解释器中对功能等价代码进行随机关联与选择的技术。与我们的工作相比,该研究未采用随机寄存器分配以及代码段之间的指令混排。类似地,克兰等人[10]提出通过在不同程序片段副本之间随机切换执行,以保护程序免受缓存旁道攻击。这些片段变体由修改后的编译器离线生成,涉及插入空操作指令和引入随机内存访问。在程序执行期间,跳板通过基于表的随机间接分支动态选择这些片段。他们的实现在通用多核台式计算机上进行。阿戈斯塔等人使用修改后的LLVM工具链编译器,目标为基于ARM Cortex‐M4的微控制器[1]。被保护程序段中的每条指令都被替换为多个功能等价的指令序列。此外,对内存访问和寄存器溢出应用了掩码方案。他们报告称,在与我们研究相同的AES‐S密码算法下,其性能开销为 11×,但代码大小开销为 9×。
执行噪声指令(也称为伪指令)是另一种通过引入随机时间延迟来缓解旁道攻击的已知技术。在软件中,通过从预定义位置跳转到专用例程来实现伪指令的执行
在程序中(例如,在要保护的代码部分之前、期间和之后)或通过触发随机延迟中断来实现。该例程例如执行一个循环,将随机初始化的寄存器[9]的值递减至零。隐马尔可夫模型[11]或模式匹配[18]是有效的方法,可用于从观测轨迹中去除对应于执行或伪指令的部分,或在轨迹中创建同步点,以消除由随机延迟引起的错位。然而,这些分析依赖于插入的时间噪声具有明显的特征(例如 中断处理程序的头部)。安布罗斯等人[4]提出随机插入一组有限的预定义指令,这些指令类似于常规代码指令,并且也可以使用随机选择的寄存器。他们认为,这类指令会修改处理器的内部状态,其性质与程序中的其他指令相同,因此由于寄存器中的位翻转而引起更大的功耗变化。我们工作的贡献之一是将这一想法进一步推进:插入程序中的噪声指令与真实程序指令(算术操作、内存操作 等)具有相同的性质,并可针对一个或多个随机选择的空闲寄存器。此外,得益于运行时代码生成,我们能够比现有的伪指令技术更好地将噪声指令与程序其余部分交织在一起。
5 结论
我们提出了一种实现运行时代码多态性的框架,作为一种针对侧信道攻击的通用保护方法。我们的实现依赖于一个轻量级的运行时代码生成框架,适用于嵌入式系统,这类系统通常由于计算和内存资源有限,难以应用即时编译器等运行时代码生成工具。据我们所知,这是首次在如此有限的计算资源(8 kB 内存和 128 kB 闪存)下实现多态性运行时代码生成,并具有可接受的运行时开销。此外,我们的实现在密码系统中适用,也可用于其他需要抵御物理攻击保护的软件组件(例如 PIN码管理、引导加载程序等),适用于广泛的计算平台[8]。
在我们的实验平台上,我们观察到在无保护的高级加密标准上,密钥可以在不到50条轨迹内被恢复。然而,在许多实际平台中,即使是在未保护的实现上,侧信道攻击也可能需要更多的轨迹才能成功提取密文密钥:通常需要 10000条或100000条迹。这意味着在实践中,可以有效地使用更大的代码生成间隔来应用多态性,从而使我们方法的开销变得更加可控。其他设计参数,例如控制噪声指令插入的参数,将对安全裕度以及执行时间和代码大小开销产生重要影响。
最后,我们强调多态性并非目的per se,而应与其他先进的保护措施相结合(例如掩码)。鉴于我们方法的通用性以及实现的轻量性,我们认为将其集成到更全面的安全方案中是切实可行的。

















 1787
1787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









