




 本文介绍了如何使用空间ETL工具将CSV格式的非空间数据转换为Esri的Shape数据。在转换前,需对数据进行有效性检查,排除无效数据。在ArcMap中,通过新建Spatial ETL Tool,设置数据源、转换类型和输出格式,利用2DPointAdder和PointConnect等转换工具,完成点和线数据的转换。空间ETL相比ArcToolbox在处理时间和数据完整性上具有优势。
本文介绍了如何使用空间ETL工具将CSV格式的非空间数据转换为Esri的Shape数据。在转换前,需对数据进行有效性检查,排除无效数据。在ArcMap中,通过新建Spatial ETL Tool,设置数据源、转换类型和输出格式,利用2DPointAdder和PointConnect等转换工具,完成点和线数据的转换。空间ETL相比ArcToolbox在处理时间和数据完整性上具有优势。
首发地址:https://www.cnblogs.com/esrichina/archive/2013/03/27/2985329.html
对于我们的客户来说,他们可能有大量包含有空间信息的非空间数据。如果要在GIS项目中使用的话,就不得不进行相应的转换处理。下面我们来看一下如何使用空间ETL完成CSV格式的文本数据到Esri的Shape数据的转换。
数据检查
在进行数据转换之前,我们需要对数据的有效性进行检查,剔除无效的数据。比如,在客户提供的数据中存在坐标字段为空值的情况,对于需要转线的数据存在起点和终点相同的数据,以及从数据库中导出数据存在非法字符的情况等,我们都应该在进行数据转换之前检查出错误数据并进行处理。
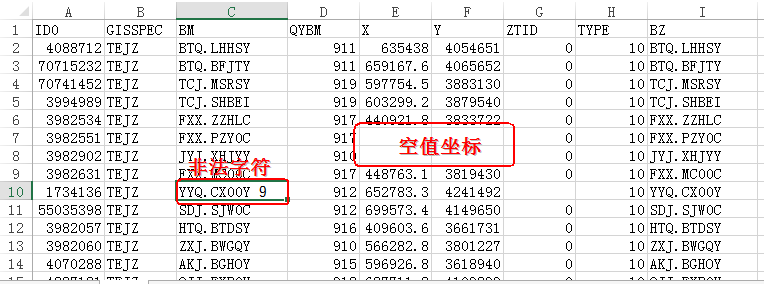
图1.待转换的点数据
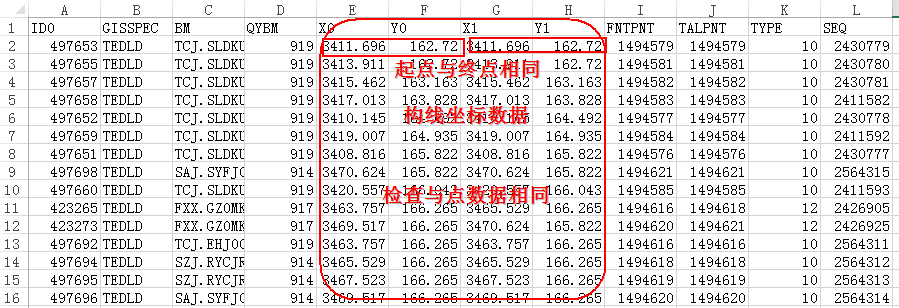
图2.待转换的线数据
空间ETL使用的流程
在确保数据已经符合转换要求的情况下,开始进行数据转换。使用空间ETL的一般流程是提取——转换——加载三个过程,如图3
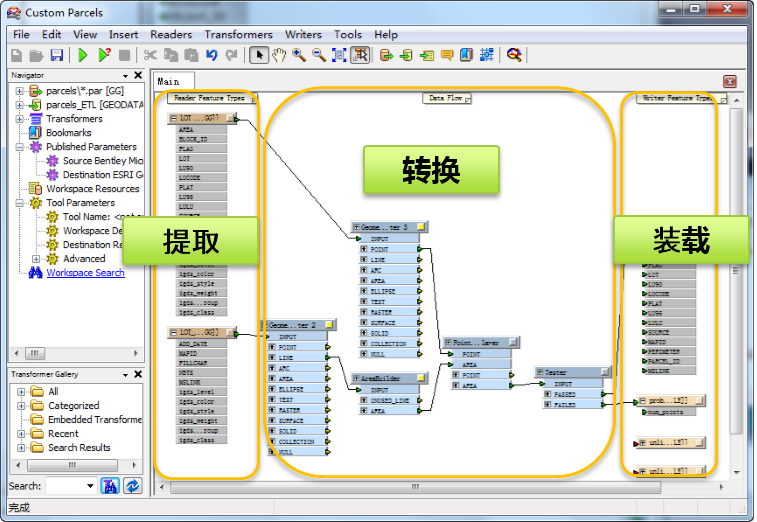
图3.空间ETL使用流程
下面我们来看一下在ArcMap里面进行CSV到Shape数据转换的具体操作流程:
- 首先,我们需要新建一个工具箱,并在工具箱中新建Spatial ETL Tool工具,如图4接下来会打开创建转换工作空间的向导,如图5
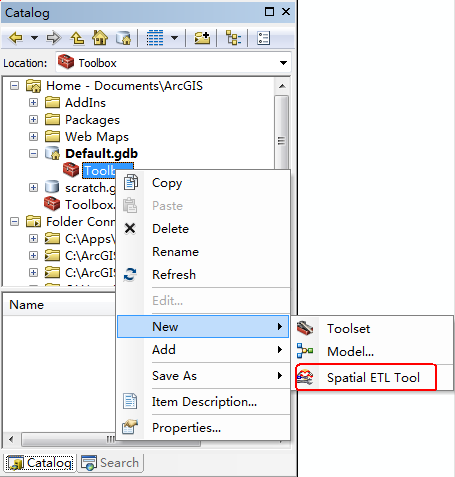
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









