



 这篇博客介绍了如何批量下载刘良云全球30米地表覆盖精细分类产品的步骤,包括注册登录网站、安装downthemall插件、使用Python爬取tif文件网址并写入TXT文档,最后通过downthemall批量下载数据。内容详细解释了每个步骤,并感谢了代码灵感来源。
这篇博客介绍了如何批量下载刘良云全球30米地表覆盖精细分类产品的步骤,包括注册登录网站、安装downthemall插件、使用Python爬取tif文件网址并写入TXT文档,最后通过downthemall批量下载数据。内容详细解释了每个步骤,并感谢了代码灵感来源。

网址:https://data.casearth.cn/sdo/detail/6123651428a58f70c2a51e49
一、需要准备的事项
1.网站需要注册并且登陆。
2.下载 downthemall 网页批量下载插件,作者科学上网下载的,可以去搜一下下载教程,这里不多做介绍。
3.有python编辑器
下载的思路是将所有tif的网址爬下来,然后再进行批量下载。
二、爬取网址
首先需要获得API号 ,将网页(https://data.casearth.cn/sdo/detail/6123651428a58f70c2a51e49 )拉到底端,评论的右边

打开这个网址
访问“通过ID获取文件列表 ”的url

url = 'https://data.casearth.cn/api/getAllFileListBySdoId?sdoId=6123651428a58f70c2a51e48'#下载的网址
resp = requests.get(url)
html = eval(resp.content.decode('utf-8'))
data = html['文件信息列表']
三、建立TXT文档储存爬下来的网址
f = open(r'C:\Users\Ray\Desktop\downrun.txt', 'w') # 运行代码前新建一个txt用来存放链接
四、获取文件路径 并写入txt
点击 元数据 可以获取文件路径
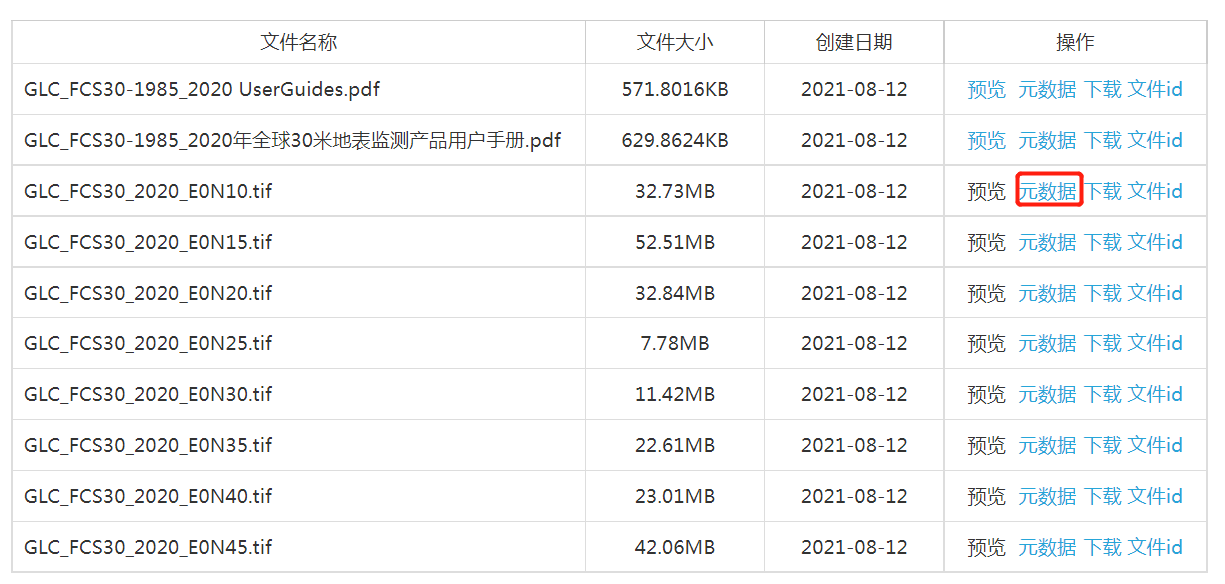
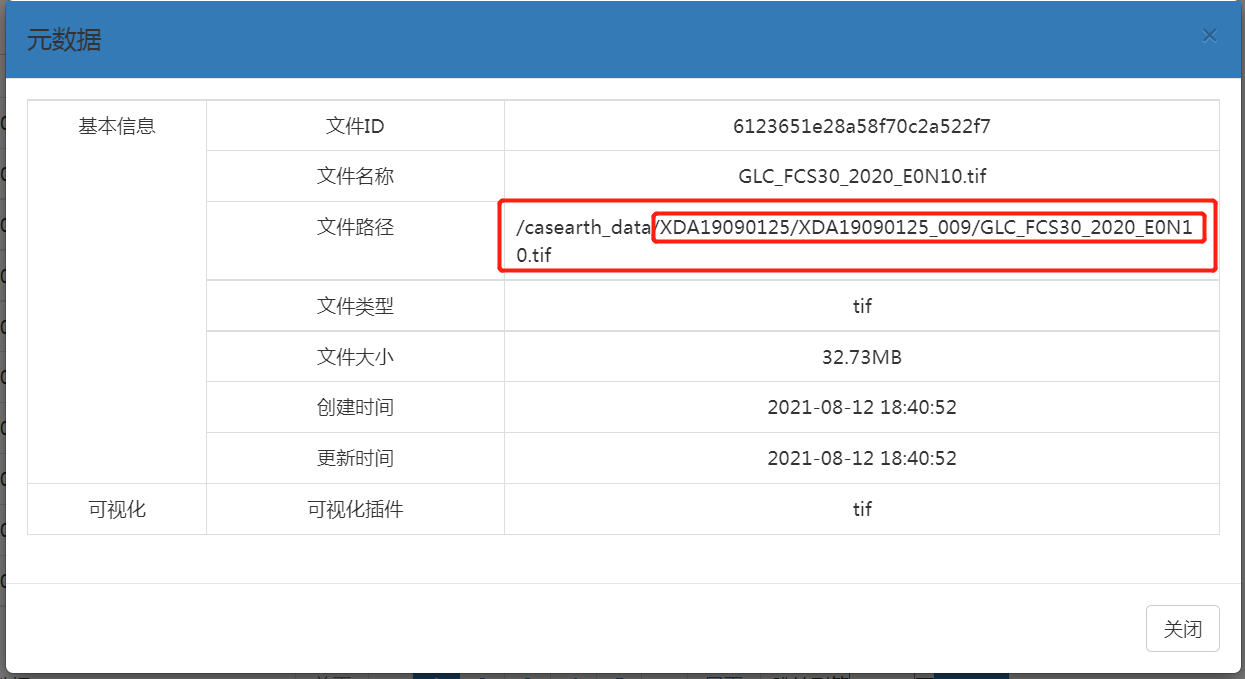
所以 url1 = 'http://data.casearth.cn/casearth_data/XDA19090125/XDA19090125_009/'
可以看到http://data.casearth.cn/casearth_data/从自己那里复制/从自己那里复制_001/是固定的,只是每个数据的名字“GLCFCS30_E0N30.tif”部分不一样
然后把链接写到txt里
f.write(url1 + '\n') # 写入下载链接到txt文档中
最后 完整代码
import requests
import time
url = 'https://data.casearth.cn/api/getAllFileListBySdoId?sdoId=6123651428a58f70c2a51e49'
resp = requests.get(url)
html = eval(resp.content.decode('utf-8'))
data = html['文件信息列表']
f = open(r'C:\Users\Ray\Desktop\downrun.txt', 'w') # 运行代码前新建一个txt用来存放链接
for i in range(len(data)):
filename = data[i]['filename']
url1 = 'http://data.casearth.cn/casearth_data/XDA19090125/XDA19090125_009/' + filename
f.write(url1 + '\n') # 写入下载链接到txt文档中
print('down')
f.close() 得到
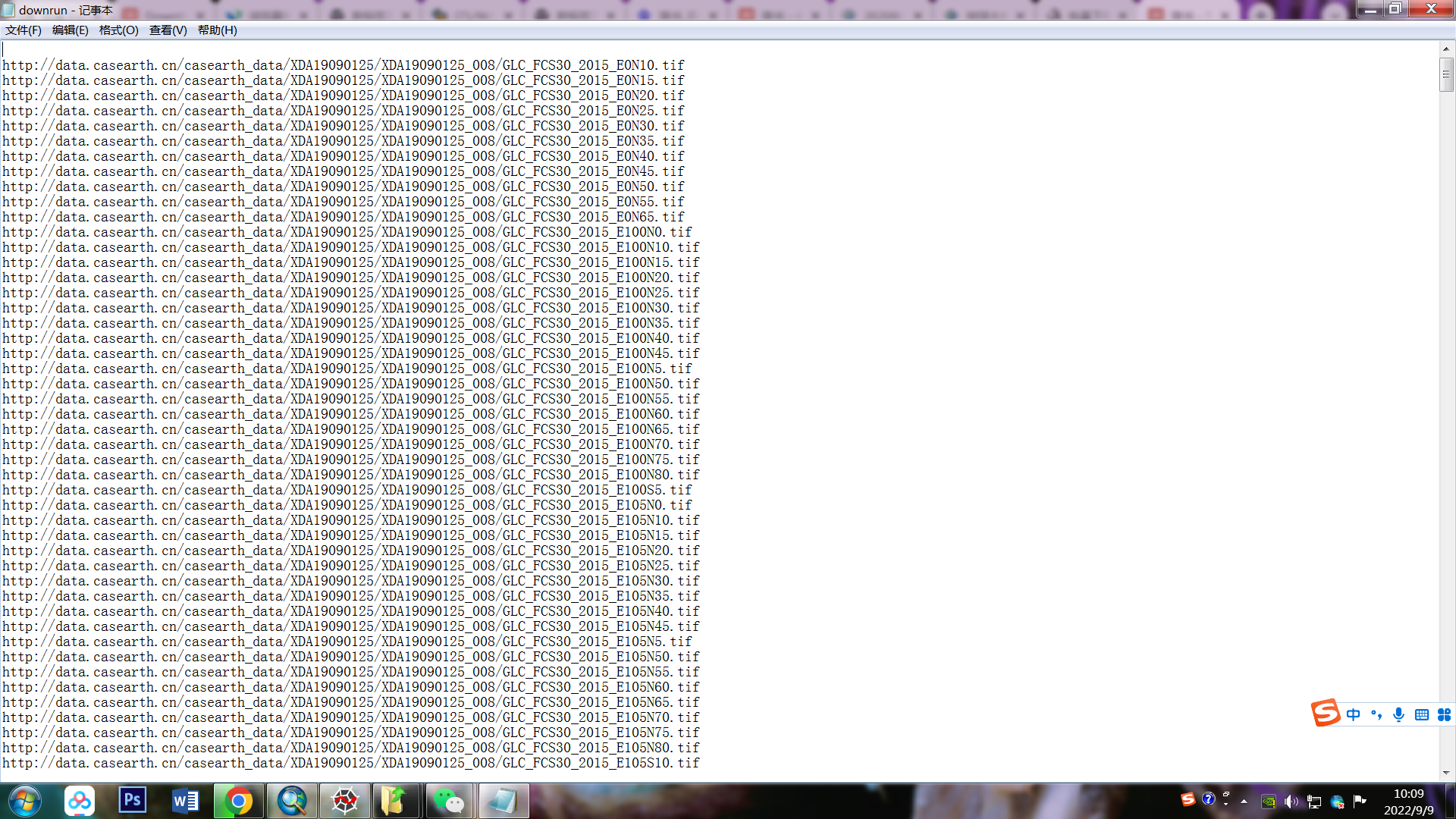
(这里用的2015年的截图 )
五、打开downthenall
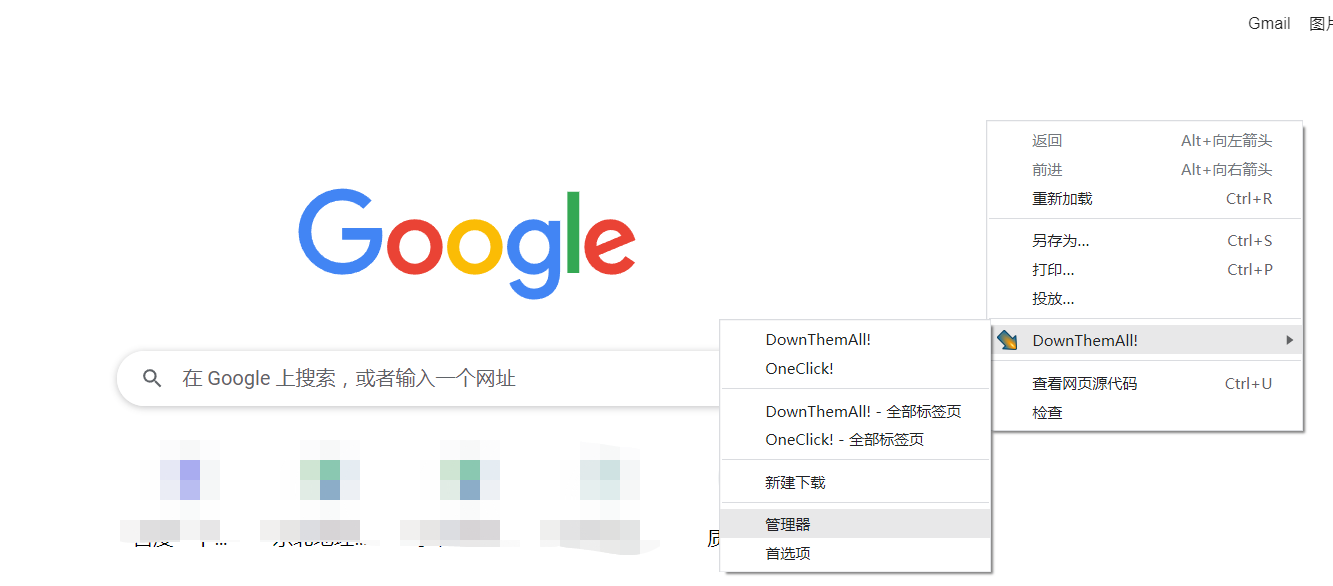
点击管理器,这里用的谷歌浏览器
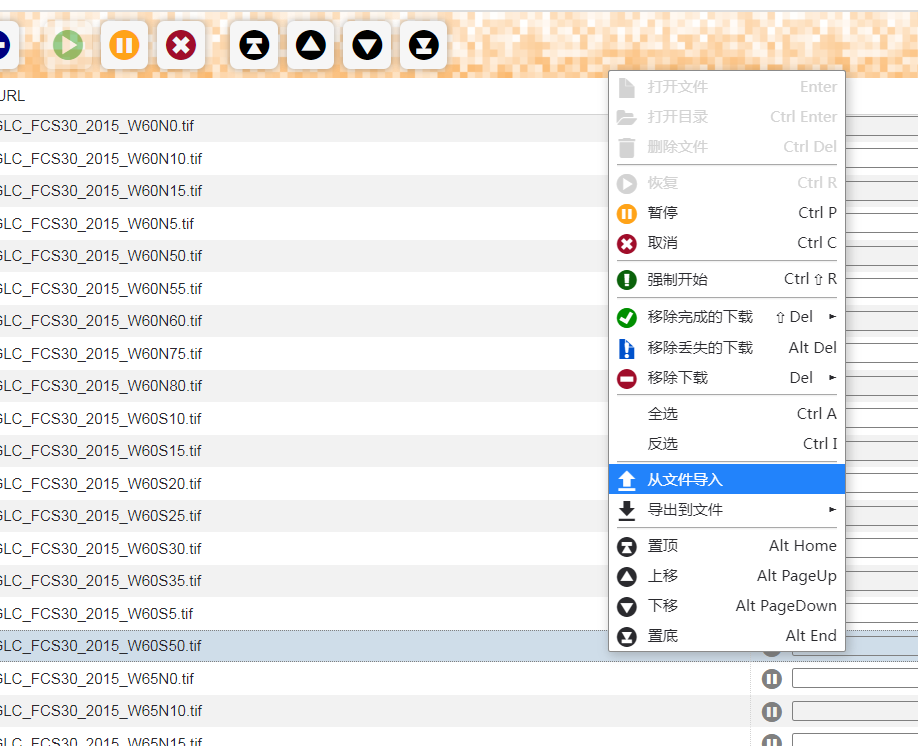
点击从文件导入
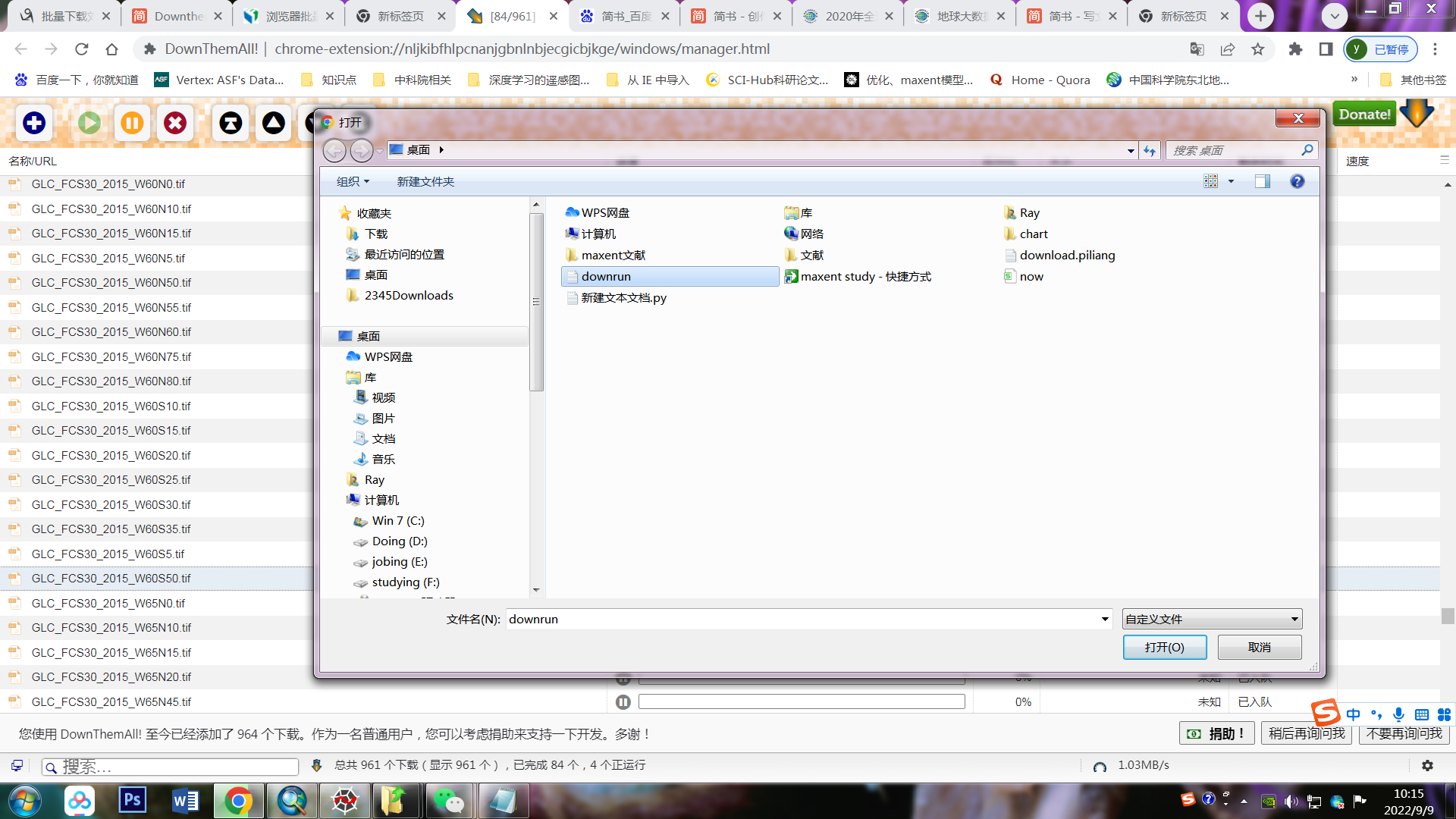
导入刚才的txt文档
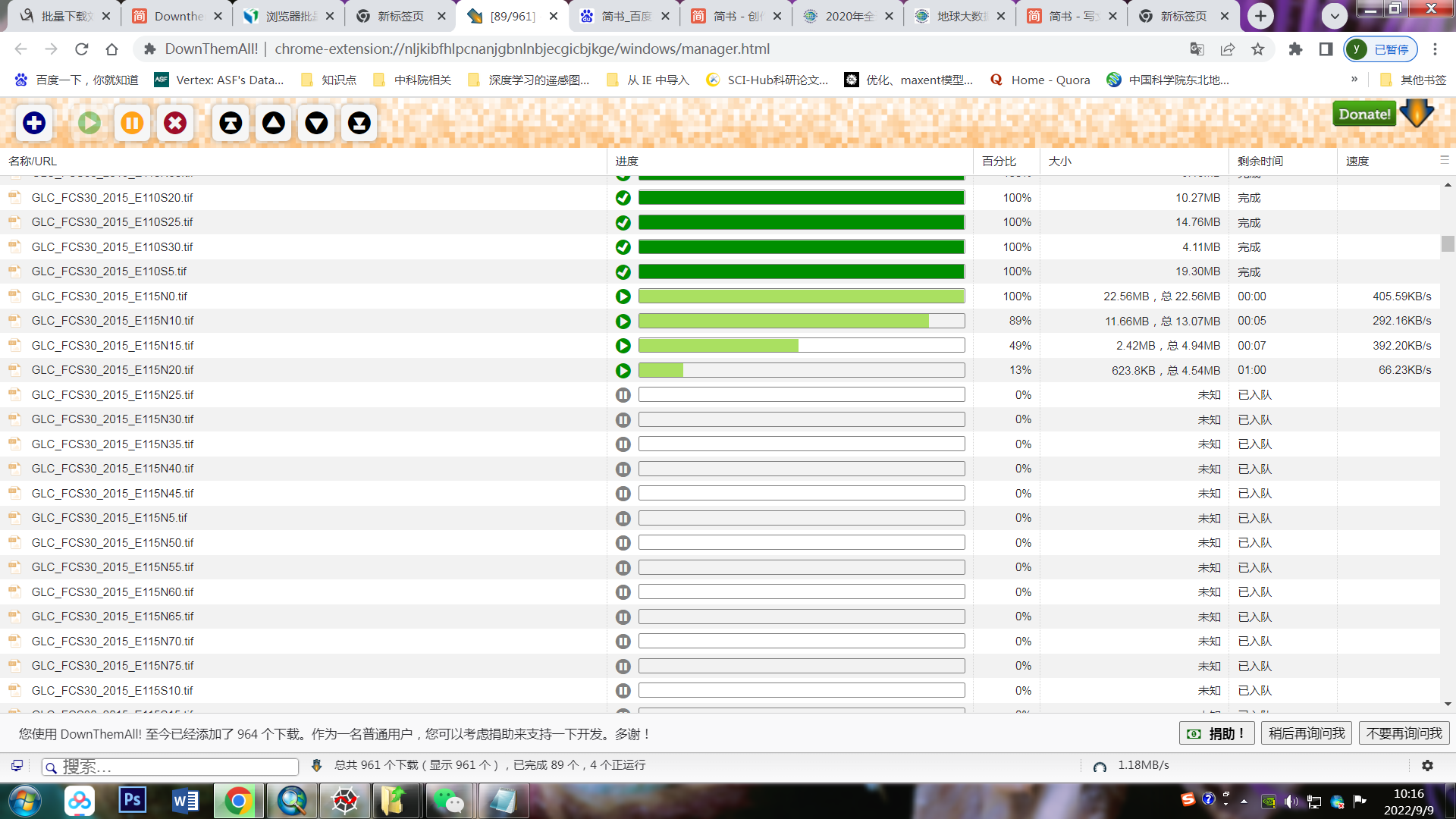
开始下载啦 !!
特别鸣谢我师妹和批量下载刘良云团队 2015年全球30米精细地表覆盖产品数据集 - icydengyw - 博客园
的作者 Hywel 代码是在他的代码基础上改的
本文仅用于学习,禁止转载。


















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









