




 本文详细介绍了RabbitMQ集群的搭建过程,包括节点间的通信配置、队列复制、Quorum队列的使用,以及通过HAProxy和KeepAlived实现的高可用方案。
本文详细介绍了RabbitMQ集群的搭建过程,包括节点间的通信配置、队列复制、Quorum队列的使用,以及通过HAProxy和KeepAlived实现的高可用方案。
安装
准备工作
这里我们使用三个RabbitMQ节点:
192.168.7.41 rabbit1
192.168.7.42 rabbit2
192.168.7.43 rabbit3
开通端口(具体见官方文档):
firewall-cmd --zone=public --add-port=4369/tcp --permanent
firewall-cmd --zone=public --add-port=5672-5673/tcp --permanent
firewall-cmd --zone=public --add-port=15692/tcp --permanent
firewall-cmd --zone=public --add-port=15672/tcp --permanent
firewall-cmd --zone=public --add-port=25672/tcp --permanent
firewall-cmd --zone=public --add-port=35672-35682/tcp --permanent
firewall-cmd --reload
firewall-cmd --zone=public --list-port
安装ErLang和RabbitMQ Server
安装文档见:https://www.rabbitmq.com/install-rpm.html。
采用RPM包而不是Repo的安装命令如下(以下的版本号可根据实际情况修改):
# 安装ErLang
yum install https://bintray.com/rabbitmq-erlang/rpm/download_file\?file_path\=erlang%2F23%2Fel%2F7%2Fx86_64%2Ferlang-23.0.2-1.el7.x86_64.rpm
# 安装RabbitMQ Server
yum install https://dl.bintray.com/rabbitmq/rpm/rabbitmq-server/v3.8.x/el/7/noarch/rabbitmq-server-3.8.5-1.el7.noarch.rpm
# 启动服务
systemctl enable rabbitmq-server
systemctl start rabbitmq-server
安装管理插件
安装文档见:https://www.rabbitmq.com/management.html
安装命令:rabbitmq-plugins enable rabbitmq-management
基本配置
添加用户
rabbitmqctl add_user admin admin
rabbitmqctl set_user_tags admin administrator
配置集群与高可用
功能和原理
设计集群的目的
- 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行
- 通过增加更多的节点来扩展消息通信的吞吐量
集群配置方式
RabbitMQ可以通过三种方法来部署分布式集群系统,分别是:cluster,federation,shovel。
- cluster:
- 不支持跨网段,用于同一个网段内的局域网
- 可以随意的动态增加或者减少
- 节点之间需要运行相同版本的RabbitMQ和Erlang
- **federation:**应用于广域网,允许单台服务器上的交换机或队列接收发布到另一台服务器上交换机或队列的消息,可以是单独机器或集群。federation队列类似于单向点对点连接,消息会在联盟队列之间转发任意次,直到被消费者接受。通常使用federation来连接internet上的中间服务器,用作订阅分发消息或工作队列。
- **shovel:**连接方式与federation的连接方式类似,但它工作在更低层次。可以应用于广域网。
节点类型
- RAM node:内存节点将所有的队列、交换机、绑定、用户、权限和vhost的元数据定义存储在内存中,好处是可以使得像交换机和队列声明等操作更加的快速。
- Disk node: 将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启RabbitMQ的时候,丢失系统的配置信息。
问题说明: RabbitMQ要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。
**解决方案:**设置两个磁盘节点,至少有一个是可用的,可以保存元数据的更改。
Erlang Cookie
Erlang Cookie是保证不同节点可以相互通信的密钥,要保证集群中的不同节点相互通信必须共享相同的Erlang Cookie。具体的目录存放在/var/lib/rabbitmq/.erlang.cookie。
说明: 这就要从rabbitmqctl命令的工作原理说起,RabbitMQ底层是通过Erlang架构来实现的,所以rabbitmqctl会启动Erlang节点,并基于Erlang节点来使用Erlang系统连接RabbitMQ节点,在连接过程中需要正确的Erlang Cookie和节点名称,Erlang节点通过交换Erlang Cookie以获得认证。
队列复制
以前对于HA有一种镜像队列(Classic Mirrored Queues),即将队列内容复制到所有节点。3.8.0版本后,更加推荐Quorum队列。
部署集群
配置Erlang Cookie
为了保证这三台机器的 Erlang cookie 相同,将rabbit1 上面的 Erlang cookie 文件复制到另外两台机器上面。Erlang cookie 文件的路径是/var/lib/rabbitmq/.erlang.cookie。
如果有$HOME/.erlang.cookie,会优先使用,因此也可以把三个节点的$HOME/.erlang.cookie的内容保持统一。
加入集群
在rabbit1查看集群状态
> rabbitmqctl cluster_status root@rabbit1 15:50:14
Cluster status of node rabbit@rabbit1 ...
Basics
Cluster name: rabbit@rabbit1
Disk Nodes
rabbit@rabbit1
Running Nodes
rabbit@rabbit1
Versions
rabbit@rabbit1: RabbitMQ 3.8.5 on Erlang 23.0.2
...
其中,Cluster name: rabbit@rabbit1,这是集群名字,其他节点可以加入这个集群中。
对其他两个节点停止RabbitMQ服务,然后执行加入集群命令:
# 停止RabbitMQ
rabbitmqctl stop_app
# 加入集群
rabbitmqctl join_cluster rabbit@rabbit1
# 启动RabbitMQ
rabbitmqctl start_app
在任意节点查看集群状态:
> rabbitmqctl cluster_status root@rabbit3 16:01:55
Cluster status of node rabbit@rabbit3 ...
Basics
Cluster name: rabbit@rabbit1
Disk Nodes
rabbit@rabbit1
rabbit@rabbit2
rabbit@rabbit3
Running Nodes
rabbit@rabbit1
rabbit@rabbit2
rabbit@rabbit3
Versions
rabbit@rabbit1: RabbitMQ 3.8.5 on Erlang 23.0.2
rabbit@rabbit2: RabbitMQ 3.8.5 on Erlang 23.0.2
rabbit@rabbit3: RabbitMQ 3.8.5 on Erlang 23.0.2
可以看到三个节点已经构建成了一个集群,但是有一个小问题,所有的节点都是磁盘节点,我们并不需要所有节点都是磁盘节点。假设这里需要rabbit@rabbit1为磁盘节点,另外两个都是内存节点,这样我们在保证可用性的同时,还能提高集群的整体性能。
下面将两台磁盘节点改成内存节点。
移除节点
对于rabbit2和rabbit3进行如下操作:
rabbitmqctl stop_app
rabbitmqctl reset
这里关键的命令是 rabbitmqctl reset。reset 命令在节点为单机状态和是集群的一部分时行为有点不太一样。
节点单机状态时,reset 命令将清空节点的状态,并将其恢复到空白状态。当节点是集群的一部分时,该命令也会和集群中的磁盘节点通信,告诉他们该节点正在离开集群。
这很重要,不然,集群会认为该节点出了故障,并期望其最终能够恢复回来,在该节点回来之前,集群禁止新的节点加入。
作为内存节点加入集群
对其他两个节点停止RabbitMQ服务,然后执行加入集群命令:
# 停止RabbitMQ
rabbitmqctl stop_app
# 加入集群
rabbitmqctl join_cluster --ram rabbit@rabbit1
# 启动RabbitMQ
rabbitmqctl start_app
配置高可用
HAProxy
首先安装HAProxy:
yum install -y haproxy
配置HAProxy,/etc/haproxy/haproxy.cfg:
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 2s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 1s
maxconn 3000
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend rabbitmq_15672
bind 0.0.0.0:15672
mode http
log global
option httplog
option forwardfor except 127.0.0.0/8
default_backend rabbitmq_management
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend rabbitmq_management
balance roundrobin
server rabbit1 192.168.7.41:15672 check
server rabbit2 192.168.7.42:15672 check
server rabbit3 192.168.7.43:15672 check
listen rabbitcluster 0.0.0.0:5672
mode tcp
option tcplog
timeout client 3h
timeout server 3h
server rabbit1 192.168.7.41:5672 check fall 3 rise 2
server rabbit1 192.168.7.42:5672 check fall 3 rise 2
server rabbit1 192.168.7.43:5672 check fall 3 rise 2
KeepAlived
利用keepalived配置高可用。
安装keepalived:
yum install keepalived
# 备份配置文件
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
编辑配置文件/etc/keepalived/keepalived.conf
# MASTER节点
global_defs {
router_id MYSQL_ROUTER # 各节点统一ID
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script check_mysqlrouter {
script "ps -C haproxy | grep haproxy" # 检测HAProxy是否在运行
interval 2
weight 2
fall 2
}
vrrp_instance VI_1 {
state MASTER # 主节点
interface ens192 # VIP绑定的网卡
virtual_router_id 33 # 各节点统一的虚拟ID
priority 102 # 数越高优先级越高
advert_int 1 # 检测间隔 1s
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.7.33 # VIP
}
track_script {
check_mysqlrouter # 检测脚本
}
}
# BACKUP节点(不同的配置)
state BACKUP # 备节点
priority 101 # 数值低于MASTER
配置防火墙:
firewall-cmd --add-rich-rule='rule protocol value="vrrp" accept' --permanent
firewall-cmd --reload
重启keepalived:systemctl restart keepalived,然后ip a查看VIP绑定情况。
Quorum队列
集群实现高可用之后,队列也要配置为多节点才行,目前官方文档推荐配置为Quorum Queue。队列只能在客户端创建的时候设置为Quorum。
- 在RabbitMQ管理界面创建的时候,下拉框选择“Quorum”:
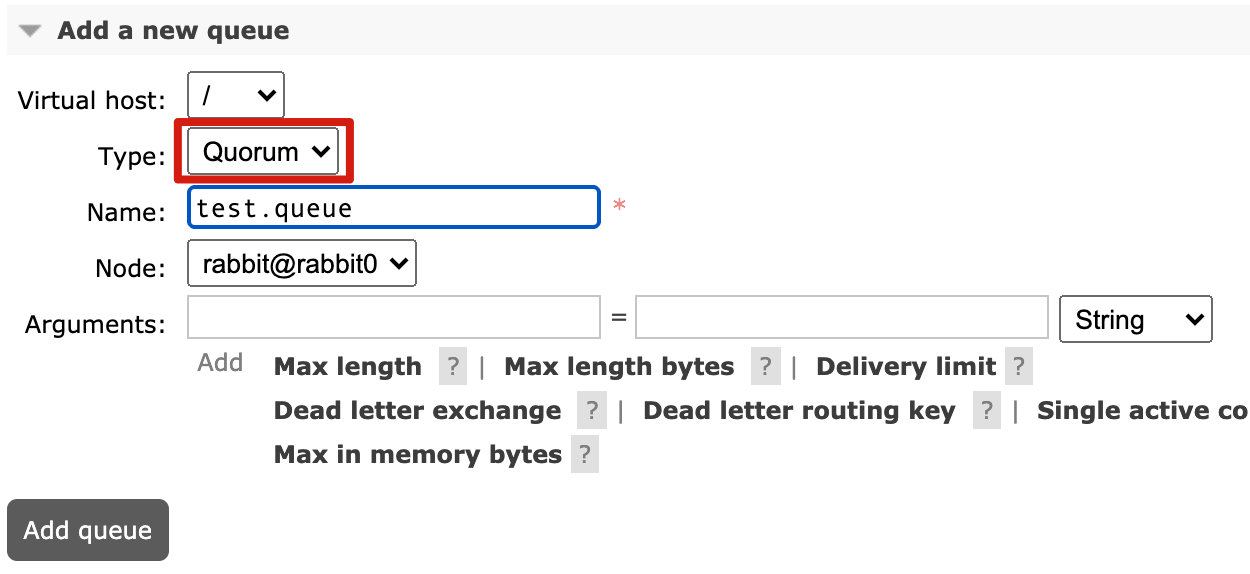
效果如下:
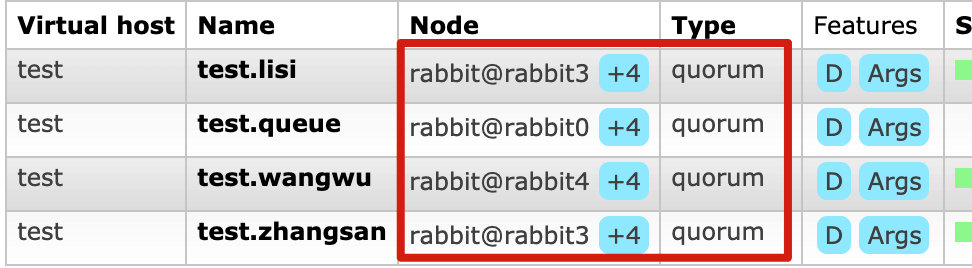
- 编程方面以Java为例,创建
Queue的时候需要指定x-queue-type参数:
Map<String, Object> args = new HashMap<>();
// // set the queue with a dead letter feature
args.put("x-queue-type", "queue");
return new Queue(MY_QUEUE_NAME, NON_DURABLE, false, false, args);

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









