




 本文介绍如何使用UIPath的Data Scraping工具从网页抓取表格数据,并将其保存为CSV文件的过程。通过实例演示了从打开目标网址、选择抓取范围到最终导出数据的具体步骤。
本文介绍如何使用UIPath的Data Scraping工具从网页抓取表格数据,并将其保存为CSV文件的过程。通过实例演示了从打开目标网址、选择抓取范围到最终导出数据的具体步骤。
作为uipath的初学者,同时也因为uipath在国内资料相对较少,希望可以通过记录自己的学习过程,给大家带来一些探讨,如如有不足,请积极佐证。谢谢!
在这里,我将演示一个简单的通过datascraping工具录入表格到csv的实例。整个过程非常简单,但是却有着非常理想的效果,这也是我认同uipath的地方,我相信在不久的将来,uipath会在国内越来越流行。开始吧。
我们使用IE11浏览器首先打开我们所需要爬数据的网站,其实uipath可以实现全自动化,即自己打开网站,只需要给它一个URL即可,以为这是简单实例。我 用IE11打开这个http://quotes.money.163.com/;
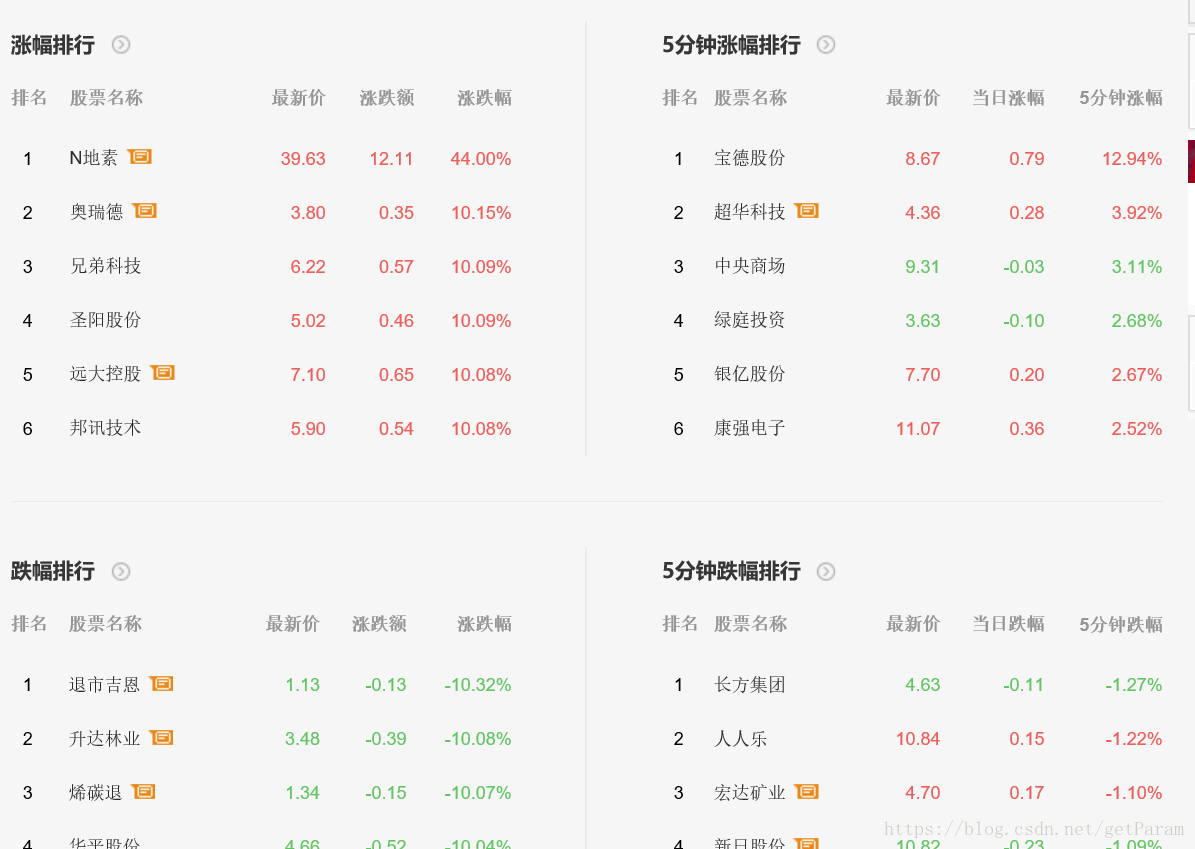
我们就要获取这里的表格信息,然后单击uipath的datascraping
选择next,开始选择所要获取的数据
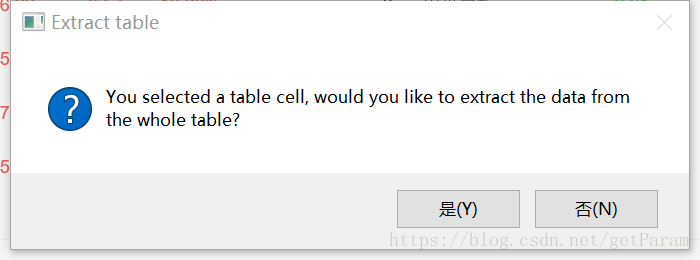
因为我们本身选择的这个网页就是一个table样式,uipath的强大功能,自行判断并会提示是否要获取整个表格数据。
我在这里选择"是".

这样我们就得到了这个表格的数据了,然后finish,这里uipath会提示
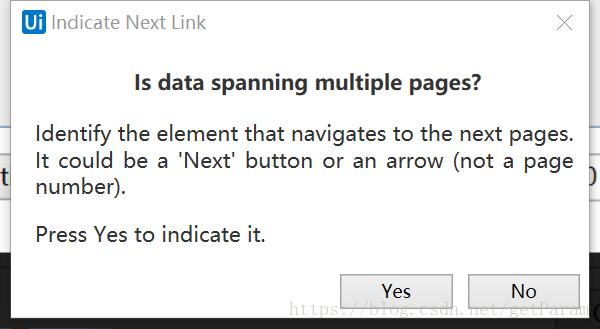
是否是要记录这一页的数据,如果no,就自动生成数据,如果yes就会选择点击下一页的button,然后就开始记录新的数据。
这里我选择no,得到
我们可以进入方法,可以看到刚才做的许多操作。这是我们获取数据的方法。
那么我们怎么写到csv呢。
uipath拥有自己的数据基本类型,这里不做详述,我们通过data scraping保存的是datatable类型,这是uipath自行封装的一中数据库类型(笔者推测)。
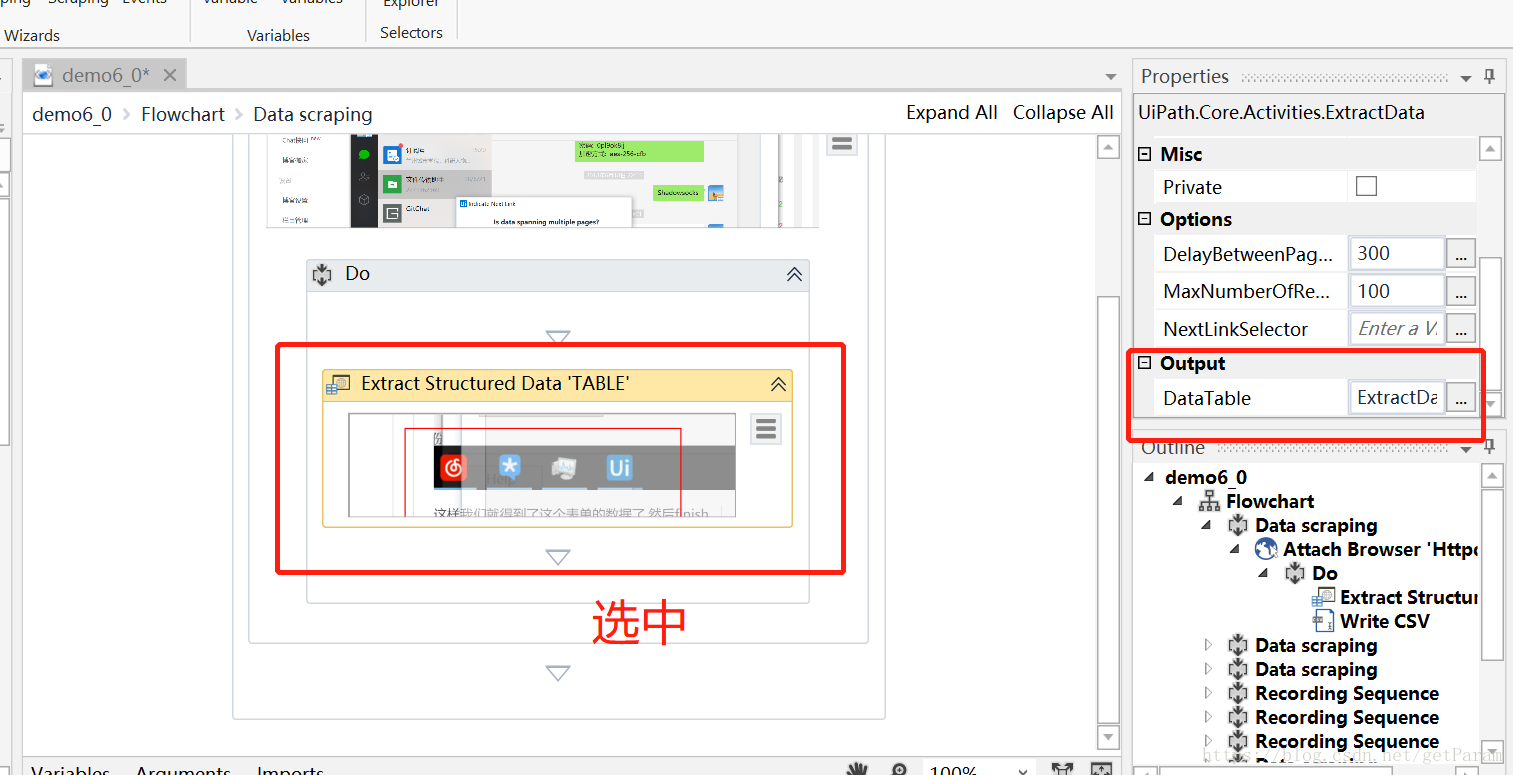
我们将他的输出变量命名为ExtractDataTable,然后通过write csv输出
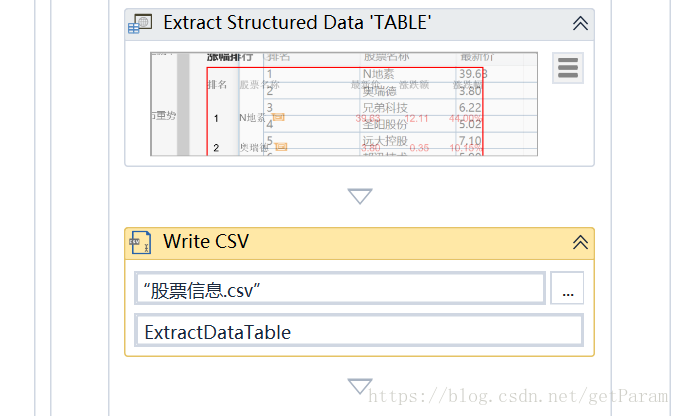
就可以得到csv格式的数据啦。
整个过程非常简单,uipath号称可以让不懂代码的人也可以实现全自动化操作。看好它!
目前是在uipath.com看他的官方视频,英文的内容有许多还是不太理解,或者理解有偏差,希望大家多多指正,我们一起学习和讨论。

















 3098
3098




 到【灌水乐园】发言
到【灌水乐园】发言







