



目录
哈希表(Hash Table,也叫散列表)是一种用于存储和查找数据的数据结构,它能在理想情况下实现快速的插入、删除和查找操作,其原理如下:
哈希函数
哈希表的核心是哈希函数。
哈希函数是一种将任意长度的数据(比如字符串、整数等各种类型的数据)映射为固定长度的数值的函数。例如,对于一个将字符串映射为整数哈希值的简单哈希函数,输入字符串 “apple”,经过哈希函数的计算后,可能会输出一个固定长度的整数值,比如 156.
构造哈希函数最常用的方法是除留余数法:f(key)%m(m不大于表长)
它有以下四个特征:
1.int f(string) 输入域无穷大,输出域有限
2.有可能不同的输入,对应相同的输出(哈希冲突)
3.如果输入的参数是一样的,输出一定是相同的,没有任何随机成分(查找,删除,修改)
4.均匀性:类似的输入,通过打乱,然后得到均匀
哈希冲突
由于通过哈希函数产生的哈希值是有限的(数组的大小有限),而数据可能比较多,导致经过哈希函数处理后有不同的学号对应相同的索引值。这时候就产生了哈希冲突(两个值都需要经过同一个地址索引位置)。
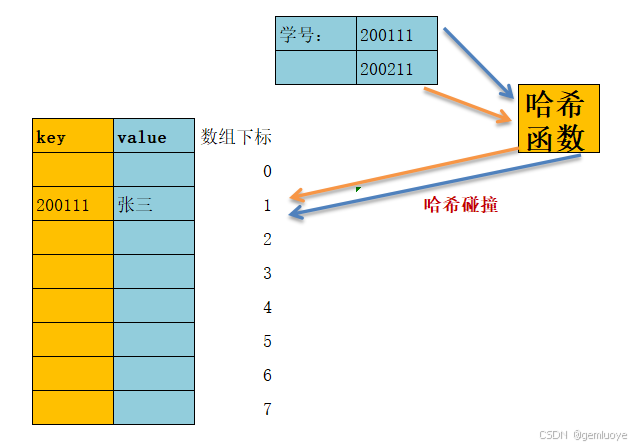
解决哈希冲突的办法
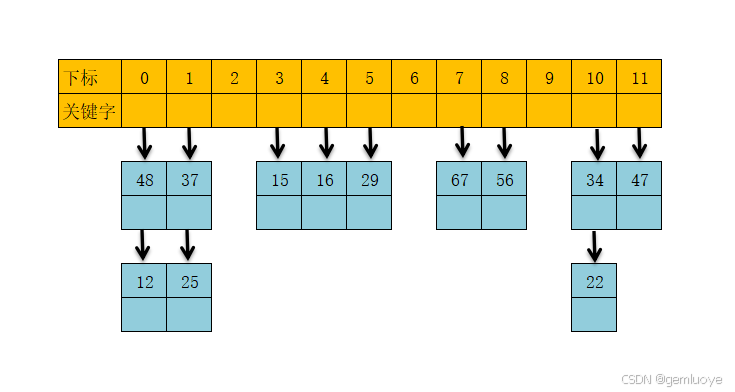
1.线性探测再散列
fi(key)=(f(key)+di)%m(di=1,2,3.....)
假设我们有键值集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12.当没有冲突时,直接放到对应的位置,如果有冲突,就放到它的下一个没有放置元素的位置。

2.再哈希法
用同一个哈希函数有冲突,就换一个哈希函数,知道没有冲突为止
3.链地址法
在原地处理冲突的值,相当于在该处建立一个链表
4.建立一个公共溢出区
新建一块内存用来存储发生冲突的数据
map与unordered_map的区别
底层实现原理
map:
map的底层实现是基于红黑树(Red-Black Tree)这种平衡二叉搜索树结构。红黑树具有自平衡的特性,能保证树的高度始终维持在一个相对较低的水平,以避免出现最坏情况下查找、插入和删除操作的时间复杂度退化。
例如,在不断插入或删除元素的过程中,红黑树会通过调整节点的颜色以及旋转等操作来保持自身的平衡。每一个节点存储了一个键值对,并且按照键的大小顺序进行排列,左子树的键值小于根节点的键值,右子树的键值大于根节点的键值,这种有序性使得map在遍历的时候会按照键的顺序依次输出元素。
unordered_map:
unordered_map的底层实现依靠哈希表(Hash Table)。它通过哈希函数将键映射为一个哈希值,然后利用这个哈希值来确定元素在内存中的存储位置。
由于哈希表的存储特性,元素在内存中的存放位置是由哈希值决定的,并没有像map那样按照键的大小顺序排列,所以遍历unordered_map时元素的顺序是无序的,取决于哈希函数的计算结果以及冲突处理等情况。
元素查找效率
map:
因为基于红黑树的结构,查找操作的时间复杂度平均为O(logn) ,在最坏情况下也是O(logn) ,其中n是元素的个数。
unordered_map:
在理想情况下,也就是没有或者很少有哈希冲突发生时,查找操作的时间复杂度可以达到O(1) ,也就是能够在常数时间内完成查找。
插入和删除操作效率
map:
插入和删除操作的时间复杂度同样平均为O(logn) ,最坏情况下也是O(logn) 。插入一个新元素时,需要按照红黑树的规则找到合适的插入位置,并调整树的结构来维持平衡;删除元素时,要先找到元素所在位置,然后通过调整节点关系来保证树依然平衡,这些操作涉及到节点的大小比较、旋转等一系列操作,时间复杂度和树的高度有关,也就是和元素个数呈现对数关系。
unordered_map:
插入操作在理想情况下,即不考虑哈希冲突时,时间复杂度接近 O(1),只需要计算哈希值并将元素放入对应的位置即可。删除操作也是类似,找到对应的哈希位置,移除元素即可,理想时间复杂度同样接近 O(1)。但如果遇到哈希冲突,尤其是处理冲突的链表很长或者开放定址法中连续的冲突位置较多等情况时,操作的时间复杂度也会有所增加。
内存占用情况
map:
由于红黑树每个节点除了存储键值对数据本身外,还需要额外存储用于维持树结构的指针(比如指向父节点、左右子节点的指针)以及表示节点颜色等信息,相对来说会占用更多的内存空间,特别是当存储的数据量较大时,这些额外的指针开销不容忽视。
unordered_map:
unordered_map除了存储键值对本身外,需要有空间来维护哈希表的结构,比如存储哈希函数相关的信息、处理冲突的链表(如果采用链地址法解决冲突)等结构占用的空间。不过整体而言,在元素个数较多时,对比map,它的内存开销可能并不会因为额外的树结构指针等而变得过大,具体还取决于哈希函数、冲突解决机制等因素的实现情况。
元素遍历顺序
map:
如前面所述,按照键的大小顺序进行遍历,是有序的。例如,统计一个数组中元素出现的次数。
#include <iostream>
#include <map>
using namespace std;
int main() {
map<int, int> m;
int a[] = { 8, 6, 9, 7, 8, 3, 7, 2};
for (int i = 0; i < 8; i++)
m[a[i]]++;
cout << m.size() << endl;
for (auto i : m)
cout << i.first << " " << i.second << endl;;
return 0;
}运行结果为:
unordered_map:
遍历顺序是无序的,每次遍历元素出现的顺序可能都不一样,取决于哈希函数计算结果以及冲突处理情况等,所以如果对元素顺序有严格要求的场景,使用unordered_map时需要额外考虑这一点。
#include <iostream>
#include <unordered_map>
using namespace std;
int main() {
unordered_map<int, int> m;
int a[] = { 8, 6, 9, 7, 8, 3, 7, 2};
for (int i = 0; i < 8; i++)
m[a[i]]++;
cout << m.size() << endl;
for (auto i : m)
cout << i.first << " " << i.second << endl;;
return 0;
}可以看出输出的顺序是无序的

使用场景
map:
适用于需要元素有序存储并且频繁进行范围查找、遍历等操作的场景。比如对一个字典数据进行存储,按照字母顺序有序地存储单词及其释义,并且可能需要查找某个区间内的单词等情况时,map就比较合适。
unordered_map:
更适合那些对查找、插入和删除速度要求极高,对元素顺序没有要求,并且能够合理设计哈希函数尽量避免或减少哈希冲突的场景。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









