



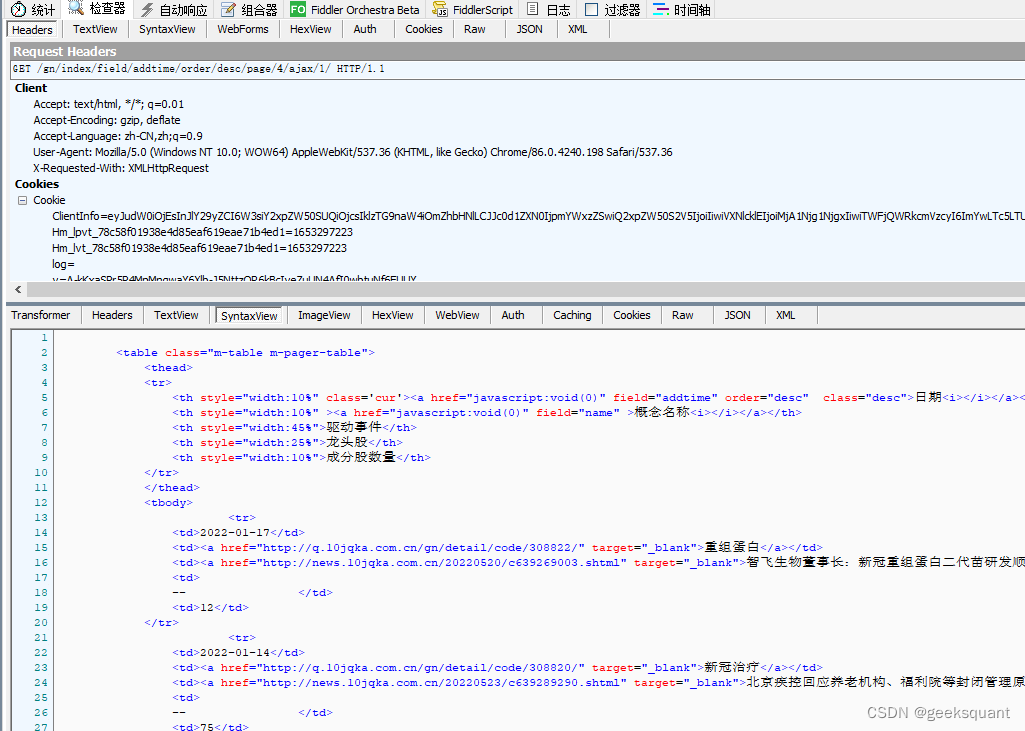
1.用Fiddler.exe抓包工具获取到动态网页的获取数据的地址:
2.常见的爬虫手段,发现网站的反爬虫非常厉害,直接屏蔽。selenium也不行。
3.最后发现pyppeteer可以,经过反复调整最后能稳定的获取到数据。最初的想法是能获取到全部的概念列表和概念成分列表,这样就能实时监控到概念的新增,然后及时提醒,
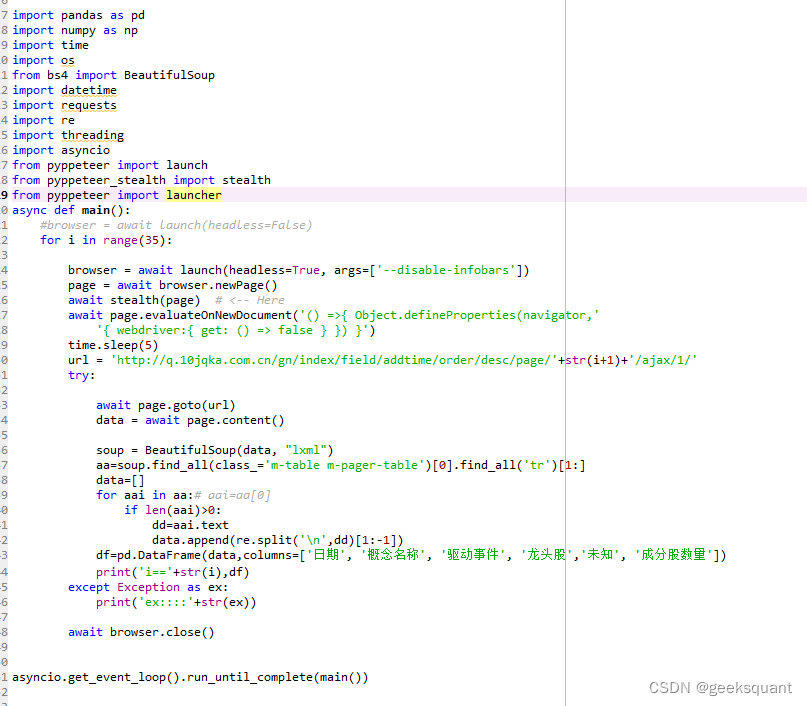
4.最后的单个网页的爬虫实现代码如下,其他同理:
 本文讲述了作者如何使用Fiddler抓包工具发现并克服网站反爬,最终通过Pyppeteer稳定获取概念列表数据,旨在实现实时监控和提醒。
本文讲述了作者如何使用Fiddler抓包工具发现并克服网站反爬,最终通过Pyppeteer稳定获取概念列表数据,旨在实现实时监控和提醒。
1.用Fiddler.exe抓包工具获取到动态网页的获取数据的地址:
2.常见的爬虫手段,发现网站的反爬虫非常厉害,直接屏蔽。selenium也不行。
3.最后发现pyppeteer可以,经过反复调整最后能稳定的获取到数据。最初的想法是能获取到全部的概念列表和概念成分列表,这样就能实时监控到概念的新增,然后及时提醒,
4.最后的单个网页的爬虫实现代码如下,其他同理:
 1928
1928





















 到【灌水乐园】发言
到【灌水乐园】发言






