




 本文详细介绍了如何在FastChat框架上利用A40和4090GPU进行LLaMA2-7B的全量微调和PEFT方式微调,涉及数据准备、环境配置、训练脚本编辑以及单卡和多卡训练的过程。
本文详细介绍了如何在FastChat框架上利用A40和4090GPU进行LLaMA2-7B的全量微调和PEFT方式微调,涉及数据准备、环境配置、训练脚本编辑以及单卡和多卡训练的过程。
FastChat 框架在 AutoDL 平台上全量微调和 PEFT 方式微调 LLMs
选择机器
暂且选择 A40 和 4090,支持 BF16 浮点格式,有两个地方需要注意:
- 硬盘可扩容空间,因为下载大模型很费空间需要额外扩容,免费空间根本不够用
- 最高 CUDA 优先选择 12.0,Pytorch 选择 2.0.0
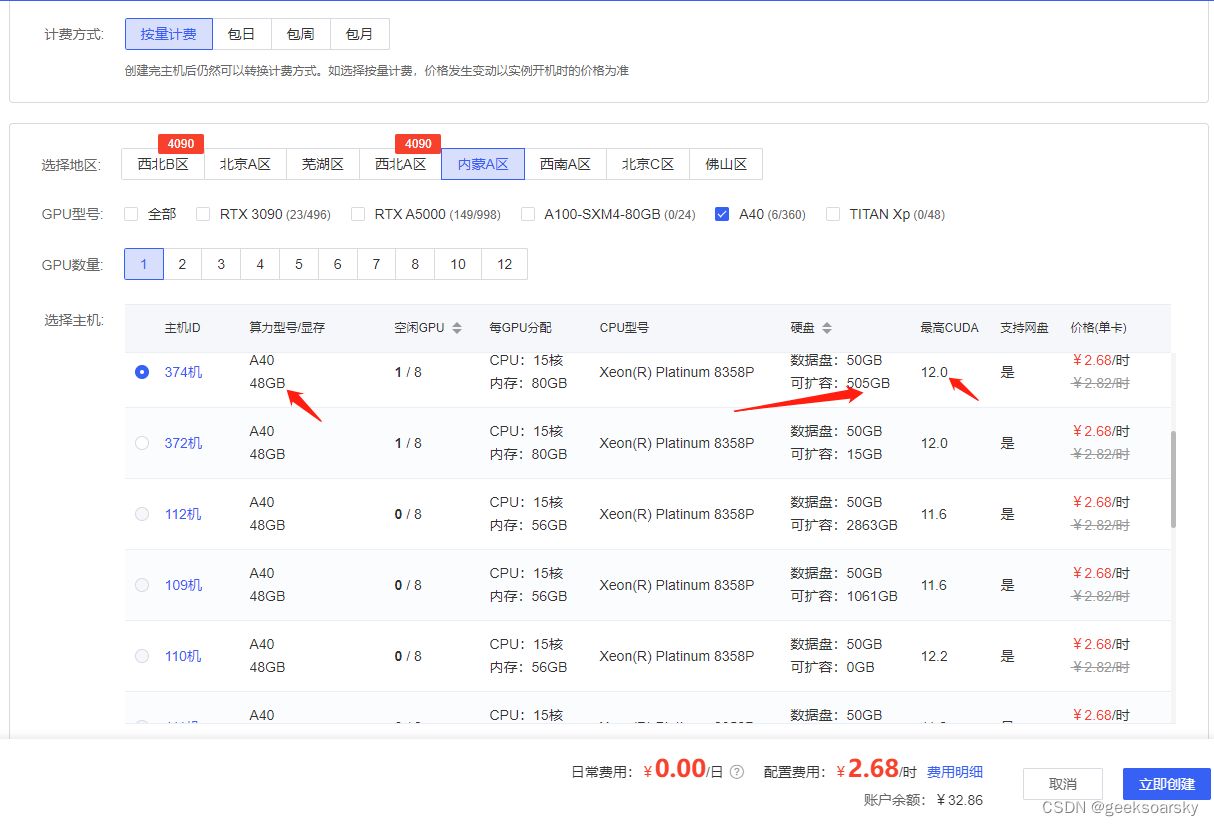
记得扩容数据盘 100-400G
打开 jupyter lab,进入 autodl-tmp 工作目录
配置环境
打开终端,进入工作目录,开启学术加速
cd autodl-tmp
# 机器重启后需要再次配置
source /etc/network_turbo
# 安装 Git-LFS
apt update && apt install git-lfs -y
下载 Llama-2-7b 大模型, 如果更换机器可以通过 scp 命令在机器之间互传免下载。
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/NousResearch/Llama-2-7b-hf
克隆我的微调仓库,本仓库基于 FastChat 框架,对数据模块和参数模块进行了拓展,除了 FastChat 官方的 Vicuna 的数据格式,额外支持 Alpaca 等数据格式指令微调。
git clone https://github.com/Aipura/Vicuna.git
安装依赖
cd Aipura
pip3 install -r requirements.txt
单机单卡 A40 (Q)LoRA 微调 LLaMA2-7B
准备数据
数据选择 alpaca_data_cleaned,Git 仓库提交时候只截取了 1000 条减少体积,数据格式如下:

编辑训练脚本
编辑训练脚本./scripts/train_llama2_7b_lora.sh,根据具体情况配置下 Base 模型,Batch_Size, Epoch 等超参数,对部分超参数不理解可以参考 Transformers 官方的 Docs。
即使单卡情况下 deepspeed 也能为我们优化一下显存,比如优化显存碎片等。
根据 FastChat 仓库[微调文档],(https://github.com/lm-sys/FastChat/blob/main/docs/training.md),我们可以使用使用 ZeRO2 使用 QLoRA 来训练。请注意,QLoRA 目前不支持 ZeRO3,但 ZeRO3 确实支持 LoRA,playground/deepspeed_config_s3.json 下有一个参考配置。要使用 QLoRA,必须安装 bitsandbytes>=0.39.0 和 transformers>=4.30.0。
如果使用 Q-LoRA 将对应超参数改为 True 就行。
deepspeed --include localhost:0 --master_port 62000 train_lora.py \
--model_name_or_path /root/autodl-tmp/Llama-2-7b-hf \
--dataset "data/alpaca_data_cleaned_1000.json" \
--dataset_format "alpaca" \
--output_dir checkpoint \
--num_train_epochs 10 \
--fp16 False \
--bf16 True \
--tf32 True \
--gradient_checkpointing True \
--flash_attn False \
--xformers True \
--per_device_train_batch_size 60 \
--per_device_eval_batch_size 60 \
--gradient_accumulation_steps 2 \
--evaluation_strategy "steps" \
--eval_steps 20 \
--save_strategy "steps" \
--save_steps 40 \
--save_total_limit 1 \
--load_best_model_at_end False \
--logging_strategy "steps" \
--logging_steps 1 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--q_lora False \
--data_seed 42 \
--train_on_source False \
--do_train \
--model_max_length 2048 \
--source_max_len 2048 \
--target_max_len 512 \
--do_eval \
--eval_dataset_size 300 \
--dataloader_num_workers 3 \
--remove_unused_columns False \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--adam_beta2 0.999 \
--max_grad_norm 0.3 \
--seed 3407 \
--disable_tqdm False \
--report_to wandb \
--lora_target_modules q_proj v_proj o_proj gate_proj down_proj up_proj \
--deepspeed playground/deepspeed_config_s2.json
开始单机单卡训练
bash scripts/train_llama2_7b_lora.sh
期间如果使用 wandb 记录训练日志,需要注册一个 wandb 账号,获取下 token, 如果不需要,删掉 report_to wandb 超参。

点开链接可以看到训练过程中的重要参数比如 loss, 学习率的变化,还能看到系统资源比如显存,CPU占用情况。

单机四卡 4090 全量微调 LLaMA2-7B
编辑训练脚本./scripts/train_llama2_13b_lora.sh,可能要配置下 Base 模型,Batch_Size, Epoch 等超参数,可以开启 Zero 2 或者 Zero 3,脚本中使用了 Zero 2, 如果想使用 Zero 3 将 deepspeed 超参数 改为 playground/deepspeed_config_s3.json,来大幅度降低显存占用。
deepspeed --include localhost:0,1,2,3 --master_port 62000 train.py \
--model_name_or_path /root/autodl-tmp/Llama-2-7b-hf \
--dataset "data/alpaca_data_cleaned_1000.json" \
--dataset_format "alpaca" \
--output_dir checkpoint \
--num_train_epochs 1 \
--fp16 False \
--bf16 True \
--tf32 True \
--gradient_checkpointing True \
--flash_attn False \
--xformers True \
--per_device_train_batch_size 24 \
--per_device_eval_batch_size 24 \
--gradient_accumulation_steps 2 \
--evaluation_strategy "steps" \
--eval_steps 20 \
--save_strategy "steps" \
--save_steps 40 \
--save_total_limit 1 \
--load_best_model_at_end False \
--logging_strategy "steps" \
--logging_steps 1 \
--data_seed 42 \
--train_on_source False \
--do_train \
--model_max_length 2048 \
--source_max_len 2048 \
--target_max_len 512 \
--do_eval \
--eval_dataset_size 300 \
--dataloader_num_workers 3 \
--remove_unused_columns False \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--adam_beta2 0.999 \
--max_grad_norm 0.3 \
--seed 3407 \
--disable_tqdm False \
--report_to wandb \
--deepspeed playground/deepspeed_config_s2.json
开始单机多卡训练
bash scripts/train_llama2_7b.sh
调整合适的batch_size,尽量把 GPU 运行时显存占满。

新开启一个终端,键入 nvitop命令监控实时显存占用情况。

推理测试
训练好模型可以使用 FastChat 从终端加载训练好的 checkpoints 测试,还可以以 WebUI Gradio 的形式加载模型测试,参考:https://github.com/lm-sys/FastChat#serving-with-web-gui



















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











