







 本文介绍了Python中多线程环境下因共享变量导致的转账问题,通过实例展示了当多个线程同时修改同一变量时,可能会出现预期外的结果。通过改造代码,将共享变量改为每个线程独立的参数,从而解决了并发修改导致的错误。最终实现无论运行多少次,都能得到正确的账户余额。
本文介绍了Python中多线程环境下因共享变量导致的转账问题,通过实例展示了当多个线程同时修改同一变量时,可能会出现预期外的结果。通过改造代码,将共享变量改为每个线程独立的参数,从而解决了并发修改导致的错误。最终实现无论运行多少次,都能得到正确的账户余额。
正式的Python专栏第43篇,同学站住,别错过这个从0开始的文章!
前面学委分享了几篇多线程的文章,前面提到了银行转账这个场景,展示了一个比较耗时的转账操作。
这篇继续转帐,下面展示一段程序,多个线程的操作都更改了amount变量导致运行结果不对的问题。
前文说了转账问题
下面展示另一种转账的方式:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/11/24 12:02 上午
# @Author : LeiXueWei
# @优快云/Juejin/Wechat: 雷学委
# @XueWeiTag: CodingDemo
# @File : __init__.py.py
# @Project : hello
import random
import threading
import datetime
import time
xuewei = {'balance': 157}
# amount为负数即是转出金额
def transfer(money):
name = threading.current_thread().getName()
print("%s 给xuewei转账 %s " % (name, money))
xuewei['balance'] += money
print("xuewei账户余额:", xuewei['balance'])
lists = [-7, 20, -20, 7] # 4次转账的数额,负数为学委的账户转出,正数为他人转入。
# 创建4个任务给学委转账上面lists的金额
threads = []
for i in range(4):
amount = lists[i]
name = "t-" + str(i)
print("%s 计划转账 %s" % (name, amount))
mythread = threading.Thread(name=name, target=lambda: transfer(amount))
threads.append(mythread)
# 开始转账
for t in threads:
t.start()
# 等待3秒让上面的转账任务都完成,我们在看看账户余额
time.sleep(3)
print("-" * 16)
print("学委账户余额:", xuewei['balance'])
这里启动了4个线程,每个线程内有个lambda表达式,分别于学委的账户进行转账,但是最后结果是185. 而不是157.
下面是运行结果:
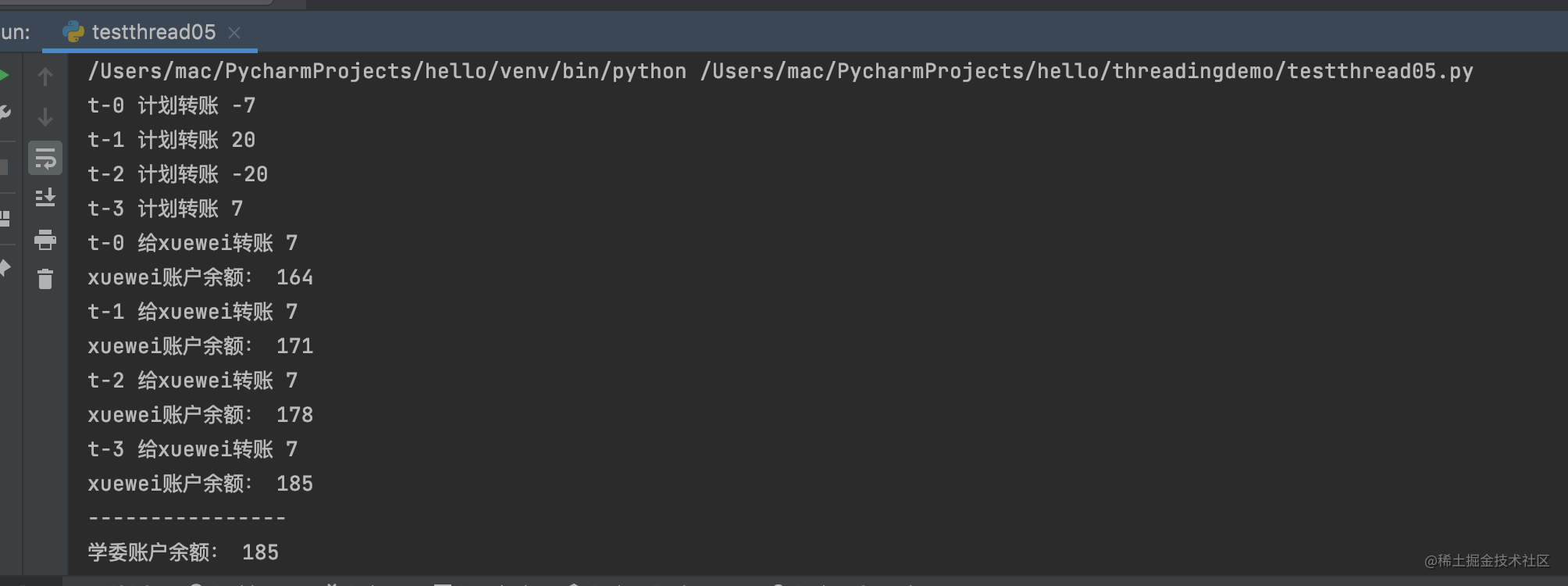
PS: 这只是一种运行结果。多线程的运行结果不是永远一样的。
如何解决这个问题?
根据观测结果我们发先amount只保留了最后一个值。
好,下面改造一下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/11/24 12:02 上午
# @Author : LeiXueWei
# @优快云/Juejin/Wechat: 雷学委
# @XueWeiTag: CodingDemo
# @File : __init__.py.py
# @Project : hello
import random
import threading
import datetime
import time
xuewei = {'balance': 157}
lists = [-7, 20, -20, 7] # 4次转账的数额,负数为学委的账户转出,正数为他人转入。
def transfer(amount):
name = threading.current_thread().getName()
print("%s 给xuewei转账 %s " % (name,amount))
xuewei['balance'] += amount
print("xuewei账户余额:", xuewei['balance'])
# 创建4个任务给学委转账上面lists的金额
for i in range(4):
amount = lists[i]
name = str(i)
# mythread = threading.Thread(name=name, target=lambda: transfer(amount))
def event():
print("%s 计划转账 %s" % (name, amount))
transfer(amount)
mythread = threading.Thread(name=name, target=event)
mythread.start()
# 等待3秒让上面的转账任务都完成,我们在看看账户余额
time.sleep(3)
print("-" * 16)
print("学委账户余额:", xuewei['balance'])
学委这里加了一个event函数,把转账计划打印出来。
从下面的一次运行结果看,event函数的输出结果没错,所有”计划转账“金额都如预期[-7, 20, -20 7]。 问题是transfer函数再多线程执行的时候,我们发现amount被多线程竞争修改了:
用户0转账金额变成20
用户1转账金额变成-20
用户2转账金额变成7
用户3转账金额变成7
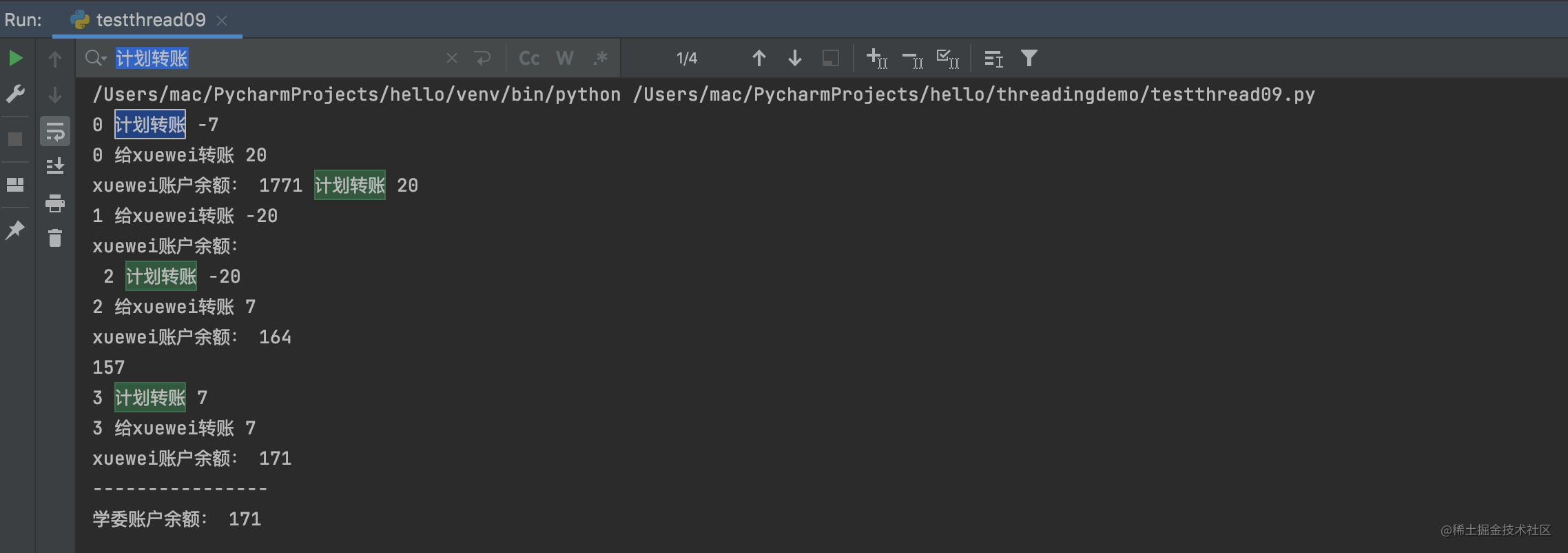
也就是说,amount被后面的线程修改了,但是前面线程还没有执行完。
用户0应该转账-7的,中间还没有执行完毕,结果被线程1修改了amount为20,用户0继续执行转账,余额变成177. 其他依次推理。
amount这个变量被多个线程竞争修改了,这个就是程序的共享变量。
到底如何解决?
方法非常简单:直接干掉共享变量。
下面就是消除共享变量的方法: 让共享变成每个线程访问独立运行空间
所以代码改动如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/11/24 12:02 上午
# @Author : LeiXueWei
# @优快云/Juejin/Wechat: 雷学委
# @XueWeiTag: CodingDemo
# @File : __init__.py.py
# @Project : hello
import random
import threading
import datetime
import time
xuewei = {'balance': 157}
lists = [-7, 20, -20, 7] # 4次转账的数额,负数为学委的账户转出,正数为他人转入。
# 我们不要依赖amount变量了
def transfer():
name = threading.current_thread().getName()
xuewei['balance'] += lists[int(name)] #通过线程名字来获取对应金额
print("xuewei账户余额:", xuewei['balance'])
# 创建4个任务给学委转账上面lists的金额
threads = []
for i in range(4):
amount = lists[i]
name = str(i)
print("%s 计划转账 %s" % (name, amount))
# mythread = threading.Thread(name=name, target=lambda: transfer())
def event():
transfer()
mythread = threading.Thread(name=name, target=event)
threads.append(mythread)
# 开始转账
for t in threads:
t.start()
# 等待3秒让上面的转账任务都完成,我们在看看账户余额
time.sleep(3)
print("-" * 16)
print("学委账户余额:", xuewei['balance'])
运行结果如下:
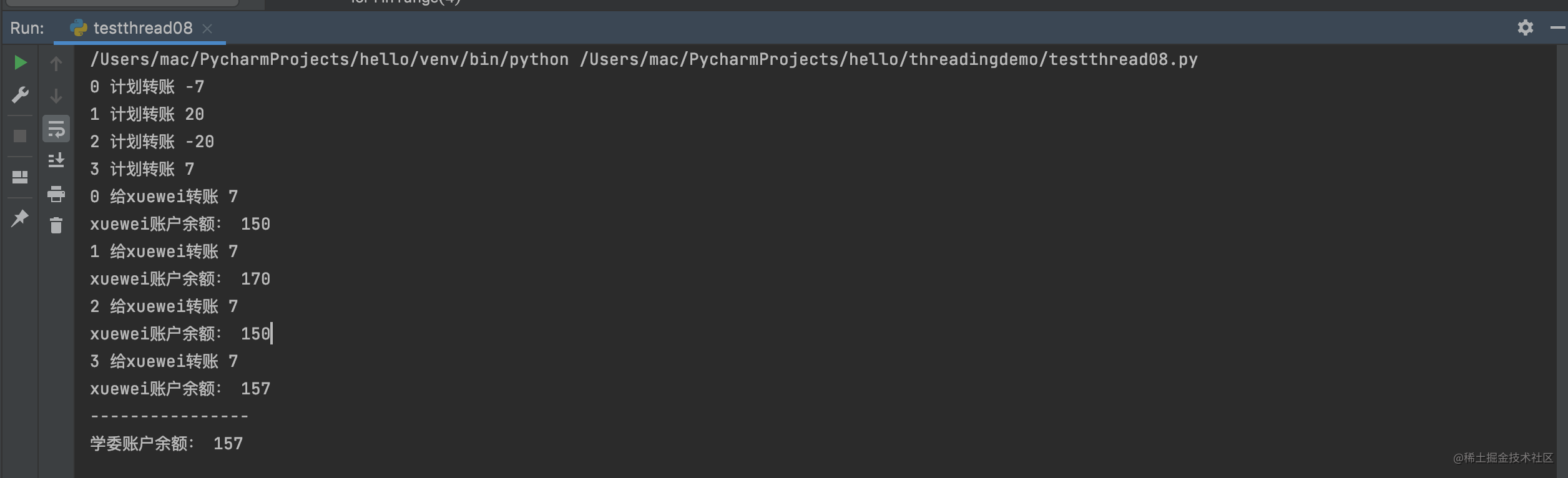
上面的代码不管怎么运行,运行多少次最后学委的账户都是157.(PS:学委不会联系读者转账的,这个特别注意)。
这次展示的另一种方式来避开多线程出现bug的方法,使用一个list下标跟线程名字一一对应,这样只要是对应名字的线程拿到的数值不错错乱。
对了,喜欢Python的朋友,请关注学委的 Python基础专栏 or Python入门到精通大专栏
持续学习持续开发,我是雷学委!
编程很有趣,关键是把技术搞透彻讲明白。
欢迎关注微信,点赞支持收藏!



















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











