




 本文介绍了Pandas中处理时间序列的关键操作,包括pd.to_datetime转换日期字符串,pd.date_range生成日期序列,Series.dt对象获取日期信息,strftime函数格式化日期,以及dt.timedelta计算时间差。重点掌握了pd.to_datetime、Series.dt对象和strftime函数的应用。
本文介绍了Pandas中处理时间序列的关键操作,包括pd.to_datetime转换日期字符串,pd.date_range生成日期序列,Series.dt对象获取日期信息,strftime函数格式化日期,以及dt.timedelta计算时间差。重点掌握了pd.to_datetime、Series.dt对象和strftime函数的应用。
文章目录
本节我们介绍在处理日期时间时的一些常用的处理方法,以一份酒店入住数据为例进行讲解。pandas 用 Timestamp 表示时点数,在大多数情况下和 python 的 datetime 类型的使用方法是通用的。
首先读入数据:
data=pd.read_csv('data/hotel.csv')
data.head()
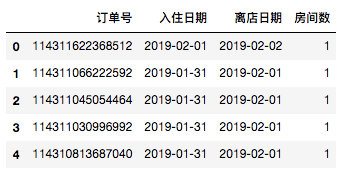
一、pd.to_datetime实现日期字符串转日期
- api:pd.to_datetime(str) 字符串类型对象转换成日期类型对象
In[]:data['入住日期'].dtype #查看'入住日期'列的类型 为object类型,即字符串对象
Out[]:dtype('O')
In[]:data.loc[:,'入住日期']=pd.to_datetime(data['入住日期'])#将'入住日期'列抓换成日期型后赋给'入住日期'列
data['入住日期'].dtype#再次输出'入住日期'列的类型 为日期型
Out[]:dtype('<M8[ns]')#日期类型
二、pd.date_range生成日期序列
- api:pd.date_range(start=None, end=None, periods=None, freq=‘D’)
- start:起始日期,字符串
- end:终止日期,字符串
- periods:期数,取值为整数或None
- freq:频率或日期偏移量,取值为string或DateOffset,默认为’D’
该函数主要用于生成一个固定频率的时间索引,在调用构造方法时,必须指定start、end、periods中的两个参数值,否则报错。
In [12]: pd.date_range(start='20170101',end='20170110')
Out[12]:
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07', '2017-01-08',
'2017-01-09', '2017-01-10'],
dtype='datetime64[ns]', freq='D')
In [13]: pd.date_range(start='20170101',periods=10)
Out[13]:
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07', '2017-01-08',
'2017-01-09', '2017-01-10'],
dtype='datetime64[ns]', freq='D')
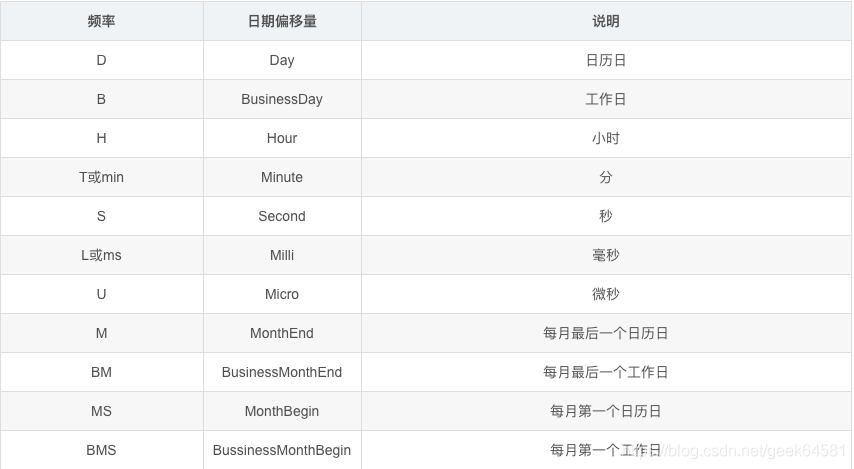
常用频率和日期偏移量:
三、Series.dt对象
- pandas 的 pandas.Series.dt 可以获得日期/时间类型的相关信息,返回值均为int型。比如:
data['入住日期'].dt.year #获取年份
data['入住日期'].dt.month #获取月份
data['入住日期'].dt.quarter #获取季度
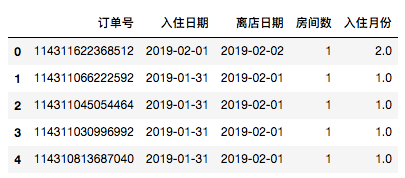
- 为数据表添加新列’入住月份’:
#提取data['入住日期']的月份信息并存到新的一列中
data.loc[:,'入住月份']=data['入住日期'].dt.month
data.head()
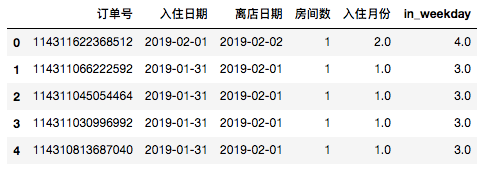
- 为数据表添加新列’in_weekday’:
#提取data['入住日期']的weekday信息并存到新的一列中
data.loc[:,'in_weekday']=data['入住日期'].dt.weekday
data.head()
- pandas.Series.dt对象能够返回的信息有:
| 类别 | 解释 |
|---|---|
| year | 年 |
| month | 月 |
| day | 日 |
| hour | 时 |
| minute | 分钟 |
| second | 秒 |
| date | 返回日期 |
| time | 返回时间 |
| dayofyear | 年序日 |
| weekofyear | 年序周 |
| week | 周 |
| dayofweek | 周中的星期几,ex: Friday |
| quarter | 季度 |
| days_in_month | 一个月中有多少天 |
| is_month_start | 是否月初第一天 |
| is_month_end | 是否月末最后一天 |
| is_quarter_start | 是否季度的最开始 |
| is_quarter_end | 是否季度的最后一个 |
| is_year_start | 是否年初第一天 |
| is_year_end | 是否年末第一天 |
四、strftime函数格式化日期
- strftime函数实际上是datetime模块中的函数,并不是pandas中的成员,在实际工作中我们常用这种方式对日期进行格式化
- api:datetime.strftime(date,format_str)
- date:需要格式化的日期
- format_str:格式化字符串
- 例如:我们需要提取’入住日期’的年份和月份组成一个新的列:
- api:datetime.strftime(date,format_str)
#首先需要引入datetime模块
from datetime import datetime
#配合apply函数
data.loc[:,'入住年月']=data['入住日期'].apply(lambda x:datetime.strftime(x,"%Y-%m"))
data.head()
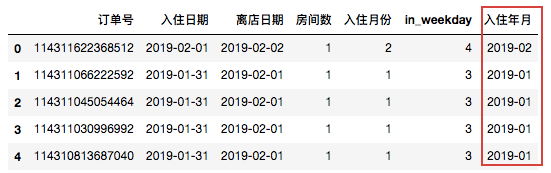
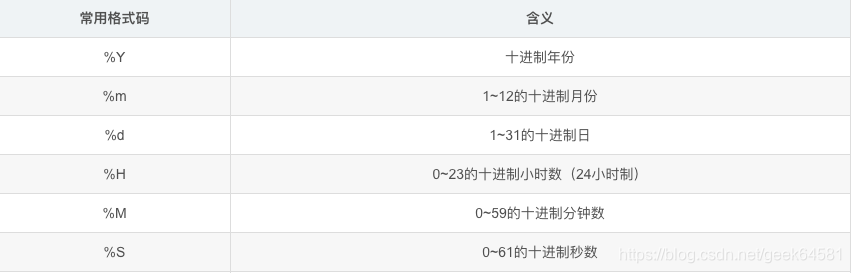
常用格式字符串介绍:
- Series.dt.to_period 另一种方法
data.loc[:,'入住年月2']= data['入住日期'].dt.to_period('M')
data.head()
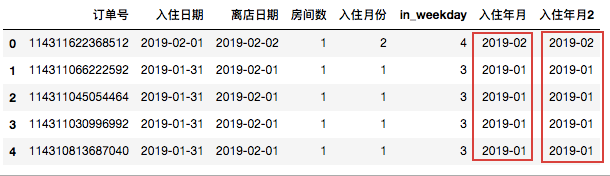
第二种方法使用起来更加简单,参数 M 表示月份,Q 表示季度,A 表示年度,D 表示按天,这几个参数比较常用。
五、 时间差(dt.timedelta)
时间差(dt.timedelta)是时间上的差异,以不同的单位来表示。例如:日,小时,分钟,秒。它们可以是正值,可正可负;大多数情况下可与datetime.timedelta互换,一般用来表示两个日期之间的差距。
例如:我们想获取客人的入住天数:
data.loc[:,'离店日期']=pd.to_datetime(data['离店日期']) #将'离店日期'列转换成日期格式
data['离店日期']-data['入住日期']#离店日期-入住日期
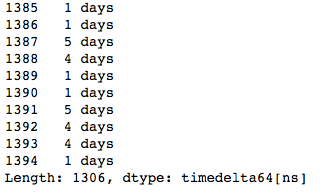
结果是一个timedelta类型的Series,并不是我们希望得到的天数,我们还需要访问timedelta对象的属性来提取天数
time=data['离店日期']-data['入住日期']
data.loc[:,'入住天数']=time.dt.days#通过访问timedelta.dt对象的days属性拿到天数
data.head()
timedelta对象有属性:days、seconds、microseconds
六、总结
- pd.to_datetime(str) 【掌握】
- pd.date_range(start=None, end=None, periods=None, freq=‘D’)【知道】
- start:起始日期 字符串
- end:终止日期,字符串
- periods:期数,取值为整数或None
- freq:频率或日期偏移量,取值为string或DateOffset,默认为’D’
- 必须指定start、end、periods中的两个参数值,否则报错
- Series.dt对象【掌握】
- data[‘入住日期’].dt.year #获取年份
- data[‘入住日期’].dt.month #获取月份
- data[‘入住日期’].dt.quarter #获取季度
- datetime.strftime(date,format_str)【掌握】
- date:需要格式化的日期
- format_str:格式化字符串
- (data[‘离店日期’]-data[‘入住日期’]).dt.days【知道】

















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









