






Ollama:你的私人AI助手
还在为云端AI服务的高昂费用和隐私问题而烦恼吗?Ollama横空出世,它是一款专为本地环境打造的大模型部署神器,让你轻松在自己的设备上运行各种强大的AI模型。无论你是开发者还是普通用户,Ollama都能让你以简单直观的方式与AI互动,享受本地化带来的速度与隐私保障。
全平台覆盖,无缝体验
Ollama的魅力之一就是它的全平台兼容性:
-
macOS:适用于所有现代版本的macOS。
-
Windows:支持Windows 10及更高版本。
-
Linux:支持多种Linux发行版,如Ubuntu、Fedora等。
-
Docker:通过Docker容器,Ollama可以在几乎任何支持Docker的环境中运行。
这种跨平台的灵活性意味着无论你使用什么设备,都能轻松加入本地AI的世界。
三步安装,即刻启动
安装Ollama简直就是小菜一碟:
-
访问官网下载:打开浏览器直奔Ollama官网
-
选择系统版本:根据你的操作系统选择合适的安装包
-
一键安装:按照提示完成安装,几分钟内就能体验AI的魅力
安装完成后,只需在命令行输入 ollama ,就能验证一切是否就绪。就这么简单!
快速上手,AI触手可及
想立即体验AI的强大?跟着这些步骤走:
-
启动服务:命令行输入 ollama 启动服务
-
部署模型:执行 ollama run gemma:2b 命令,系统会自动下载并安装Gemma模型
-
开始对话:模型加载完成后,你就可以开始与AI进行对话了
-
探索更多:随着熟悉度提升,你可以尝试更多高级功能和定制选项
即使你是AI领域的新手,这些简单步骤也能让你迅速掌握Ollama的基本操作,开启你的本地AI之旅。
Ollama的安装与配置
Windows & Mac
对于Windows和Mac用户,安装过程简直不能再简单:
-
Mac用户:访问 https://ollama.com/download/Ollama-darwin.zip 下载安装包
-
Windows用户:前往 https://ollama.com/download/OllamaSetup.exe获取安装程序
下载后双击安装,几分钟内就能完成全部设置。
Linux:服务器部署的最佳选择
对于追求性能的用户,Linux服务器是运行大模型的理想选择。以下是详细的部署步骤:
step 1: 一键安装
终端执行这行命令,一切搞定:
curl -fsSL https://ollama.com/install.sh | sh安装成功后,系统会显示配置文件位置:
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.接下来,我们采用如下命令查看下服务状态, running 就没问题了:
systemctl status ollama查看是否安装成功,出现版本号说明安装成功:
ollama -vstep 2: 服务启动
服务启动与验证
浏览器访问http://your_ip:11434/,看到"Ollama is running"就说明一切正常!

step 3:个性化配置(可选)
想要更高级的设置?编辑配置文件:/etc/systemd/system/ollama.service
开启远程访问:
[Service]
Environment="OLLAMA_HOST=0.0.0.0"自定义模型存储位置:
[Service]
Environment="OLLAMA_MODELS=/data/ollama/models"指定GPU使用:
Environment="CUDA_VISIBLE_DEVICES=0,1"修改配置后,别忘了重启服务:
systemctl daemon-reload
systemctl restart ollamaOllama实战指南
常用命令一览
Ollama的命令体系与Docker类似,简洁而强大。输入 ollama 可查看所有可用命令,包括模型管理、运行控制等核心功能。

模型库:AI的百宝箱
Ollama的模型库( https://ollama.com/library )堪比AI界的Docker Hub,提供了丰富多样的大模型选择:
明星模型 参数规模 存储大小 一键部署命令 DeepSeek-R1
| Model | Parameters | Size | Download |
| DeepSeek-R1 | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 3.3 | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 4 | 14B | 9.1GB | ollama run phi4 |
| Phi 4 Mini | 3.8B | 2.5GB | ollama run phi4-mini |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Granite-3.2 | 8B | 4.9GB | ollama run granite3.2 |
从轻量级的1B模型到庞大的671B巨兽,从通用对话到专业编程,总有一款适合你的需求。
模型安装与对话
以Llama3.2为例,安装模型只需一行命令:
ollama run Llama3.2
当看到"Send a message"提示时,你就可以开始与AI对话了!对话结束后,按 control+d 退出,下次使用同样的命令即可重新开始。

API调试:解锁无限可能
Ollama最强大的特性之一是它为每个模型自动提供了API接口,让你能将AI能力无缝集成到自己的应用中。
使用 Apifox 调试API
1. 复制以下cURL命令:
curl --location --request POST 'http://localhost:11434/api/generate' \
--header 'Content-Type: application/json' \
--data-raw '{"model": "llama3.2","prompt": "Why is the sky blue?","stream": false}'2. 在Apifox中新建HTTP项目,创建接口并粘贴上述cURL

3. 点击"发送",即可收到AI的回复
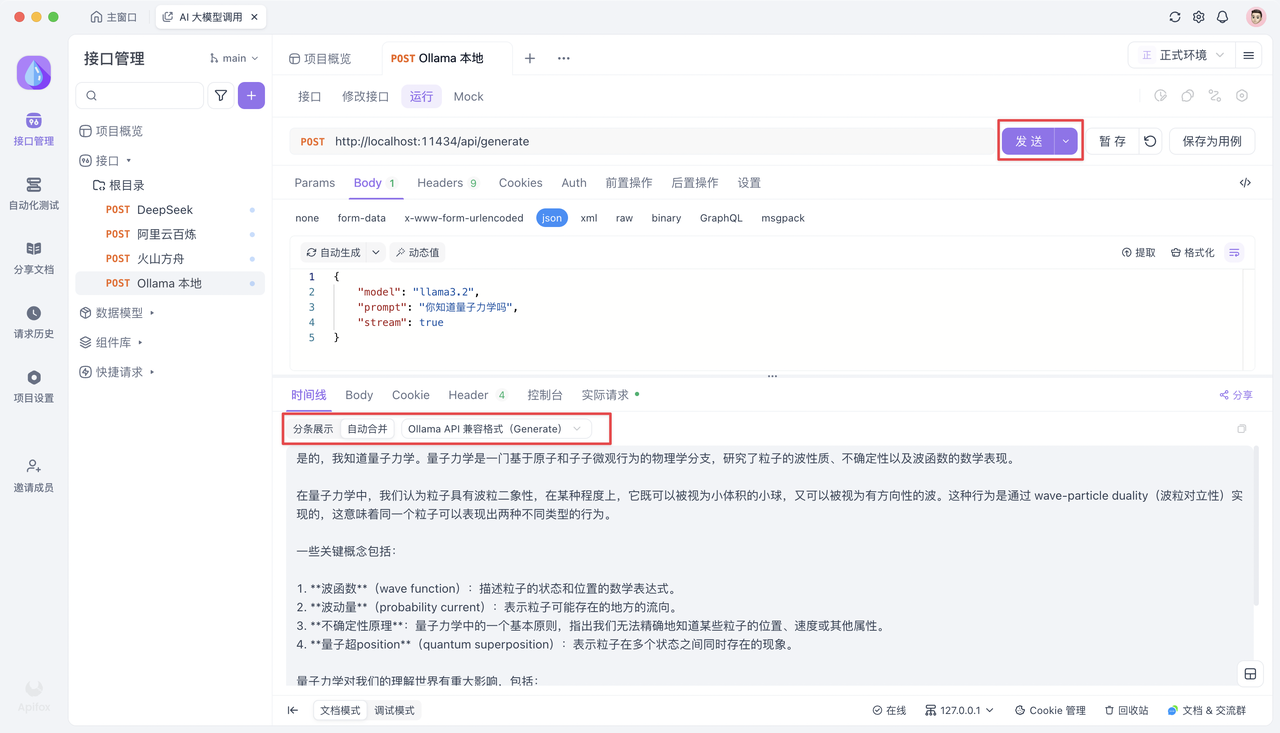
4. 想要体验流式输出?将 "stream": false 改为 "stream": true 即可

通过API接口,你可以将Ollama的AI能力集成到网站、应用程序、自动化工作流等各种场景中,创造无限可能。
未来展望:本地AI的无限潜力
随着大模型技术的快速发展和硬件性能的不断提升,本地部署AI将成为越来越多开发者和企业的首选。Ollama作为这一领域的先行者,不仅简化了部署流程,还为AI应用的普及铺平了道路。
在不久的将来,我们可以期待更多轻量级但功能强大的模型出现,让普通消费级设备也能流畅运行复杂AI任务。同时,本地部署也将解决数据隐私、网络延迟等云端AI的痛点,为特定行业应用提供更安全可靠的解决方案。
你是否已经迫不及待想尝试Ollama了?欢迎在评论区分享你的使用体验,或者有任何问题也可以留言讨论。如果这篇文章对你有帮助,别忘了转发给可能需要的朋友,让更多人了解本地AI部署的魅力!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









