 实现TCP字节流重组
实现TCP字节流重组





该实验就是在上个实验Byte Stram基础上实现TCP字节流的重组。
在网络中,TCP建立的连接,其发送过来的数据可能丢失,乱序等,我们要根据其首个字节的序号,将这些乱序等字节流重组,使得他们恢复成有序的字节流供应用层或者网络栈进一步分析或使用。而这个实验我们就是随机收到若干个乱序的字节流,有他们的字节流(字符串形式表示)、首字节的序号以及是否是当前流的结束等信息。我们需要维护一个可靠字节流作为输出,而这个输出正是lab 0 中实现的可靠字节流Byte Stream。
StreamReassembler
在实现这个类之前,有几个问题需要明确一下。
1.容量capacity具体指的是什么?
如lab1文档所说一样,实际上我们维护的是两个容器,一个容器维护我们接收到的乱序字节流,一个容器维护我们已经排好序可以直接使用的有序字节流(实际上就是我们lab0实现的ByteStream)。这里容量指的是这两个容器容量的总和,即这两个容器存储字节总和不能超过capacity,同时这两个容器也都是动态更新的。具体如下图所示:
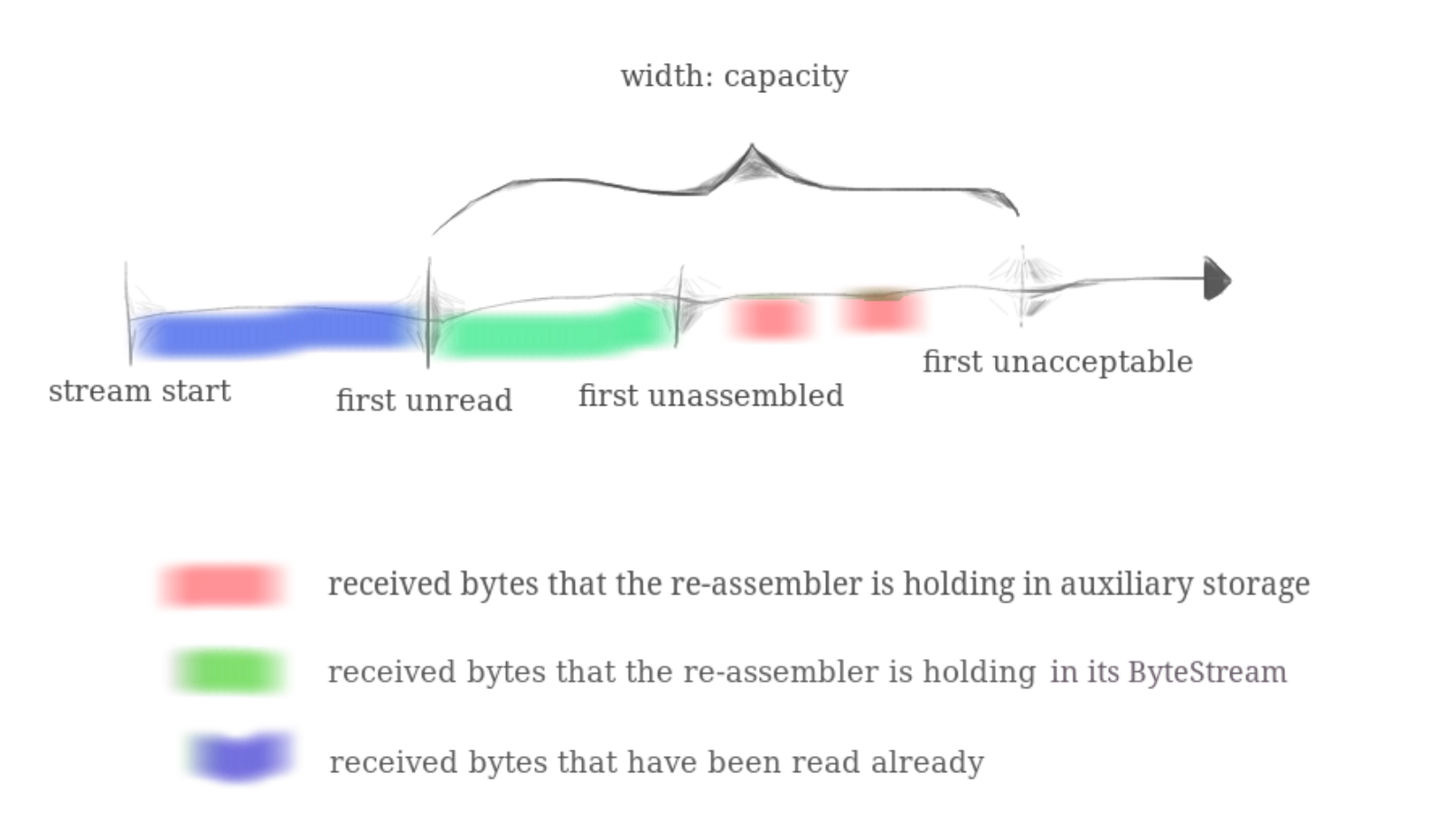
2.维护乱序字节流的容器具体应该接收哪些字节流?
我最初的想法是只要没超过capacity的限制,那就直接接收。
考虑例子,当capacity=8时,先来字节流“abc”,序号是0,此时他们直接就是有序的,则有序容器容量为3。此时再来字节流“ghijk”,序号是5,但此时有序我们需要的是序号为3的字节,他们并不满足条件,倘若仅考虑容量限制那我们照单全收,此时有序容器容量为3,无需容器容量为5,此时容器满了。再来字节流“def”,序号为3,但由于我们容器满了装不下,并且更糟糕的是由于容器已满并且乱序容器中存放的事靠后的字节流无法支持我们排序,所以程序就在这卡死了,再来多少字节流都只能丢弃,这个策略是糟糕的!
新的策略是考虑乱序字节流容器仅接收在能力范围内的字节流,什么意思,考虑当前乱序字节流需要的序号是index,且乱序字节流容器剩余容量为m,则只考虑字节序号为[index,index+m)之间的字节,因为超出这个范围目前我们这个容器无法处理,既然无法处理,那就直接丢弃。
3.最后具体用什么数据结构实现?
我这里采用了map<size_t,char>实现的,最初想的是每个字节一个序号会不会太浪费了,但考虑用map<size_t,string>后引发复杂的重叠问题,所以为了简单其间,还是采用了map<size_t,char>,对每个字节制定独特的序号。
最后实现代码如下:
StreamReassembler类仅添加了私有成员_buffer(map容器),_index(目前处理到哪个字节序了),_last_index(最后结束的字节序)和_eof(当前流是否结束)。
class StreamReassembler {
private:
// Your code here -- add private members as necessary.
std::map<uint64_t, char> _buffer{}; //用map存储所有未排序到字节
uint64_t _index{}; //目前处理到哪个字节了
uint64_t _last_index{};
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
bool _eof{}; //是否已经结束了
public:
//! \brief Construct a `StreamReassembler` that will store up to `capacity` bytes.
//! \note This capacity limits both the bytes that have been reassembled,
//! and those that have not yet been reassembled.
StreamReassembler(const size_t capacity);
//! \brief Receive a substring and write any newly contiguous bytes into the stream.
//!
//! The StreamReassembler will stay within the memory limits of the `capacity`.
//! Bytes that would exceed the capacity are silently discarded.
//!
//! \param data the substring
//! \param index indicates the index (place in sequence) of the first byte in `data`
//! \param eof the last byte of `data` will be the last byte in the entire stream
void push_substring(const std::string &data, const uint64_t index, const bool eof);
//! \name Access the reassembled byte stream
//!@{
const ByteStream &stream_out() const { return _output; }
ByteStream &stream_out() { return _output; }
//!@}
//! The number of bytes in the substrings stored but not yet reassembled
//!
//! \note If the byte at a particular index has been pushed more than once, it
//! should only be counted once for the purpose of this function.
size_t unassembled_bytes() const;
//! \brief Is the internal state empty (other than the output stream)?
//! \returns `true` if no substrings are waiting to be assembled
bool empty() const;
};
类中主要函数方法实现如下:
其中,最重要的部分就是之前讨论的哪些乱序字节流缓存的问题。
void StreamReassembler::push_substring(const string &data, const size_t index, const bool eof) {
//已经收到结束的字节信号并且字节序已经写到结束信号了,就不允许继续插入了。
if(_eof && _index == _last_index) return;
if(eof)
{
_eof = eof;
_last_index = index + data.length(); //这里记录最后的字节
}
//首先尽可能的将字节存入map中,首先计算能接受的窗口区间
size_t window_l = _index;
size_t window_r = _index + _capacity - _output.buffer_size() - 1;
for(size_t i = 0; i < data.length(); i++) {
if(index + i < window_l) continue;
if(index + i > window_r) break;
_buffer[index + i] = data[i];
}
//由于有新插入的,所以可以更新_buffer到有序的字节流中
while(_buffer.find(_index) != _buffer.end()) {
std::string st(1, _buffer[_index]);
_buffer.erase(_index);
_index += _output.write(st);
}
//如果收到结束信号且已经写完了,关闭ByteStream
if(_eof && _index == _last_index) {
_output.end_input();
}
}
//返回目前还没有排序的字节数
size_t StreamReassembler::unassembled_bytes() const {
return _buffer.size();
}
bool StreamReassembler::empty() const {
return _buffer.empty();
}
最后贴一张成功截图,完结撒花!

















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









