 MIT 6.S081页表实验解析
MIT 6.S081页表实验解析





目录
Detecting which pages have been accessed
知识学习
页表
页表,顾名思义的话就是“页”的表格。页是一种特殊的内存机制,大概的说就是把4KB的大小称为一页,那为什么会有页表呢?
当初在学习时也想不通为什么操作系统设计为什么要加这么多的限制等,虚拟内存,分页啥的。但仔细想想如果所有的进程都直接操作真实的物理地址,这就太容易乱套了。完全可以让某个进程去直接纂改另一个进程的数据,这不就乱套了吗?
所以需要引入一个抽象层,所有关于地址的操作都需要经过他的管理,保证各个进程都只能操作自己的地址空间。这里的抽象层引入的就是MMU(内存管理单元),这是计算机硬件重要的一部分。他要做的就是虚拟地址和物理地址的转换。这里为什么要引入虚拟地址呢?为了实现进程之间的隔离。在虚拟地址中,每个进程都有独属于自己的从0开始的地址空间,并且不同进程之间的地址空间相互独立,这样就实现了进程之间的强隔离性了。虚拟地址不能直接参与运作,虚拟地址需要经过MMU才能转换为实际的物理地址。注意这里的MMU并不存储页表,每个进程都有都属于自己的页表,MMU要做的仅仅是读取该页表然后为其进行虚拟地址和实际地址的转换。具体做法是CPU有个SATP的寄存器,他存储的信息负责页表的切换,用来管理MMU。
地址空间
理论上,对于64位的计算机,寻址空间是2^64。所以不可能为每个地址都分配一个表格项去记录。这里还是以“页”为单位(4KB)。对于虚拟地址而言前25位是不是用的,之后的27位是索引号,也就是说在页表中,最多有2^27个表项。再然后的12位为偏移量,也就是4KB对应的位数。在RISC-V处理器中,对应的物理地址是56位(设计师设计的),其中前44位是页号(在页表中而对应前44位),后12位是页内偏移。整个流程就是MMU取出虚拟地址中的中间27位的索引,在页表中进行查询,查询到实际的页表号,再加上虚拟地址中最后的12位的偏移量就得到了实际的物理地址。
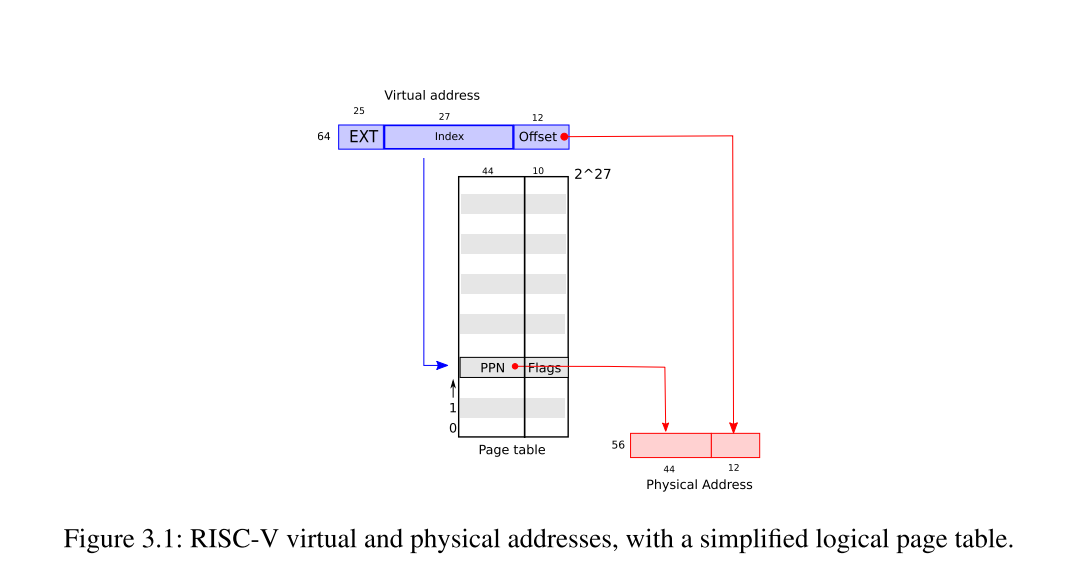
实际的RISC-V页表结构和硬件实现
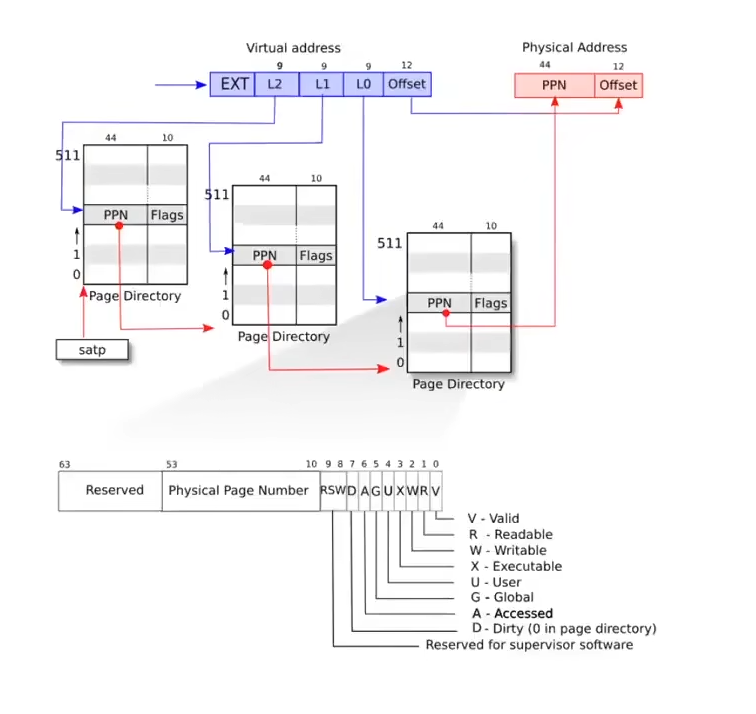
页表中的每个条目被称为PTE(Page Table Entry),64位,具体含义见下图。其中前10位当作保留字,以便后续开发扩展。之后的44位位PPN(实际物理页号),最后的10位为标志位,起到对当前PTE权限控制等功能。
实际的RISC-V页表采用了三级页表的实现,即将虚拟地址中27位的索引号分成三个9位的索引号,分别在三级页表中进行索引,由于索引号只有9位,所以每级页表都有2^9=512个PTE。注意这里每级页表中的PPN,指的是实际的物理地址,和下级页表的数量无关。
整体流程如下,拿到虚拟地址之后,首先查看satp寄存器,找到第一级页表的物理地址,同时取出前9位,L2的索引(EXT忽略),确定特定的PPN后,根据此PPN的信息,找到第二级页表的物理地址同时取出L1索引,查找到特定的PPN之后,根据此PPN信息,找到第三级页表同时取出L0索引,最后在第三级页表中超出特定的PPN,加上虚拟地址的业内偏移唯一确定实际的物理地址。
实际的RISC-V采用三级页表的主要目的是节省空间。考虑只有一个虚拟地址和实际地址的转换,只有三个页表就可以完成,也就是512*3个PTE,倘若采用以及页表则要初始化2^27个PTE,这大大节省了空间,至于为什么是三级页表,相比是设计师在平衡空间利用率和效率之间的选择。
注意这里都是硬件MMU自动完成的。
快表(TLB)
这个概念就比较熟悉了,是一种缓存技术,在三级页表中可以发现,翻译一个虚拟地址需要访问三次内存,这个开销是巨大的。所以TLB会将一些访问的结果[虚拟地址,物理地址]的映射结果存储起来。每次需要翻译时,需要先查找快表,如果没有再实际的去页表中查找,有的话直接使用即可。同时采用一些快表替换策略去替换缓存。
内核页的分布情况
每个进程都是需要有自己的虚拟空间,同时,内核也不例外。
从实际地址空间看起,地址最下方的是未被使用的空间,之后0x1000处存的是boot的相关内容,ROM只读不可修改。接下来向上还有一些其他的IO设备,PLIC是中断控制器,CLINT也是中断的一部分,UART负责console和显示器交互,VIRTIO disk负责和磁盘进行交互。随后0x80000000往上的地址,就属于DRAM的范畴了,操作系统的启动是放在0x80000000处的。
接下来我们回到虚拟地址和实际地址的映射情况,为了使XV6足够简单,内核页的情况大部分都是平等映射,即在虚拟地址空间中的地址同时也是实际地址空间中的地址。这里可以注意下虚拟地址空间中的高地址处,有很多内核栈和Guard page。内核栈的作用是用户进程从用户态切换到内核态保存临时数据方便返回,每个进程都有自己的内核栈空间。可以发现Guard page没有映射到实际的物理地址。它实际上起到了一个边界作用,当内核栈扩增超出规定的空间时,会跑到Guard page处,但Guard page由于没有分配物理地址,所以一定会缺页,这样就方便操作系统对内核栈进行管
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









