






 本文深入解析了一致性哈希算法,介绍了如何通过该算法解决在分布式系统中动态增删节点时的数据分布问题。通过虚拟节点的引入,进一步优化了数据分布的均匀性,解决了环的偏斜问题。
本文深入解析了一致性哈希算法,介绍了如何通过该算法解决在分布式系统中动态增删节点时的数据分布问题。通过虚拟节点的引入,进一步优化了数据分布的均匀性,解决了环的偏斜问题。
苦敲代码千万行,算法不清,原理不明,霾蒙双眼碍前行。
1.问题
假如我想存储10万条信息,此时有4台应用服务ip1、ip2、ip3、ip4。我们应该怎么做均匀存储呢?当然我们直观想到的是hash:取模大法,如此,便可理论上均匀散落了。那检索的时候再次使用大法,然后根据key获取具体信息。甚好甚好~~
我相信这一定没问题的。但是如果哪天我有钱了,服务器感觉4台不高大上,再加一台ip5,那么在使用大法的时候,发现除数发生了变化,空气突然安静了,一时无法适应,这可急死小可了,肿么办呢?

不要慌,轰隆隆一声响,一套一致性哈希算法掌法此时从天而降。
2.什么是一致性哈希?
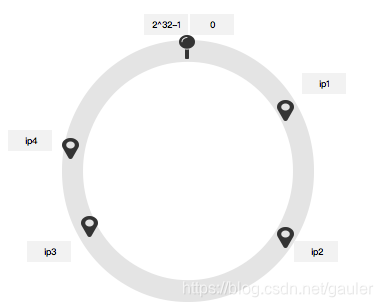
一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

关于服务器列表的操作:使用服务器ip取hash后,定位到这个环上:
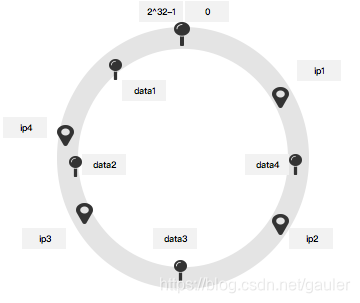
接下来,将数据根据key也同样做hash,使其也散落到这个环上。
如此还不够high,我们让数据动起来,为新的纪录喝采,动起来,就拥有精采未来。。。等等怎么动呢?那就让data顺时针动呗~
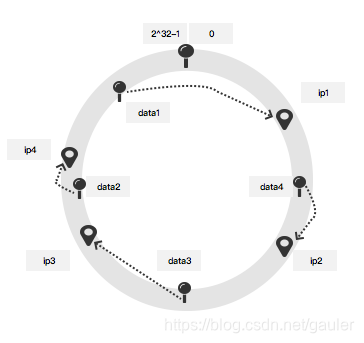
动完了之后呢,data1就存储在ip1,data2存储在ip4,data3存储在ip3,data4存储在ip2上了,好开森的说,终于不担心增减服务器了。一旦出现服务器的增减,数据项就动起来就好。
3.那这会不会有问题呢?
答案是:会的,这就是环的偏斜。
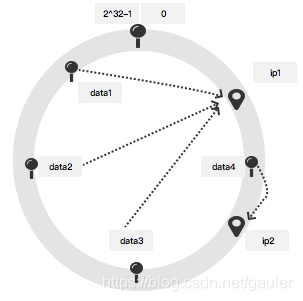
假如数据都落在了ip1的左侧,与ip4之间,则根据我们的动起来法则,数据都会落在ip1上,这就叫环的偏斜。
那怎么解决呢?传说中的终极大法:虚拟节点 娓娓走来
废话不多说,语言太过于苍白,上图:
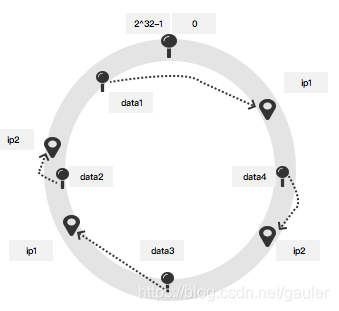
从图上就可以看出,左侧多了两个节点ip2,ip1,而这就是所谓的虚拟节点,而使数据分布均匀许多。
至此呢,一致性hash算法就基本打完收工了。
4.那是否还有其他疑问呢?
首先,某个节点失效了,缓存都漂到下个节点了;然后一会它又恢复了,这时候它就有脏数据了。
解决方案:每个节点引入集群。
其次,一致性哈希解决的是某节点宕机后缓存失效的问题,只会导致相邻节点负载增加。但是因为宕机后需要重新从数据库读取,会导致此时缓存命中率下降及db压力增加。
解决方案:每个节点主备或主主集群。
辛苦手敲,有问题欢迎拍砖,共同进步。

















 5160
5160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









