







 本教程介绍如何结合大型语言模型(如OpenAI的GPT-3)和向量数据库(Facebook AI的FAISS)创建销售机器人。机器人通过加载、分割文档,将文本向量化存储,然后根据用户问题查询向量数据库,使用LLM生成回答。
本教程介绍如何结合大型语言模型(如OpenAI的GPT-3)和向量数据库(Facebook AI的FAISS)创建销售机器人。机器人通过加载、分割文档,将文本向量化存储,然后根据用户问题查询向量数据库,使用LLM生成回答。
在这个教程中,我们将使用OpenAI的大型语言模型和Facebook AI的FAISS向量数据库创建一个销售机器人。这个机器人可以理解和回答基于文档内容的问题。
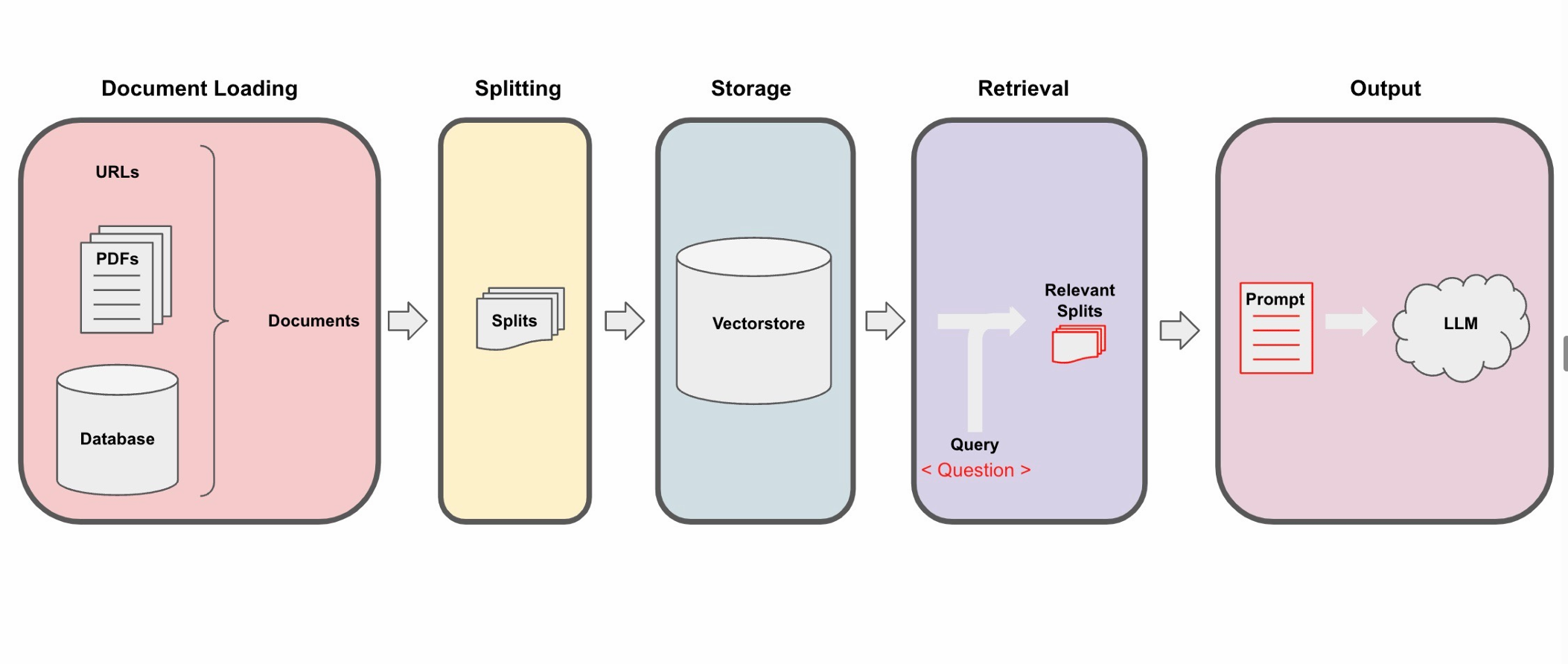
基于向量数据库和大型语言模型(Large Language Model,LLM)开发问答机器人的技术原理可以分为以下几个步骤:
1. Document Loading
这是整个流程的第一步,包括从各种来源(如本地文件、URLs、PDFs等)加载文档。这些文档的内容将用于训练和查询机器人。
2. Splitting
在这个步骤中,每个文档都会被分割成多个 "splits" 或段落。分割的目的是为了使每个单独的段落都能够作为一个独立的信息单位进行处理和查询。
3. Vector Storage
在将文档加载并分割成段落后,我们需要将这些段落转换为可以由机器理解的形式。这是通过所谓的 "嵌入" 或 "向量化" 进行的,其中每个段落都被转换为一个数值向量。这些向量然后被存储在一个 "向量数据库" 或 "向量存储"(Vectorstore)中。这样,每个段落都有一个对应的向量表示,这个表示捕获了段落的语义信息。
4. Query
当用户向机器人提出一个问题时,这个问题同样会被转换为一个向量。然后,这个向
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











