







 本章聚焦Web和App数据采集,介绍如何使用Python和后裔采集器采集猫眼电影数据,包括首页、详情页的采集。讲解了配置后裔采集器、解析加密数据的方法,以及如何利用Selenium进行Web数据采集。此外,还提到了使用雷电模拟器和uiautomator2模块进行APP数据采集的基础知识和步骤。
本章聚焦Web和App数据采集,介绍如何使用Python和后裔采集器采集猫眼电影数据,包括首页、详情页的采集。讲解了配置后裔采集器、解析加密数据的方法,以及如何利用Selenium进行Web数据采集。此外,还提到了使用雷电模拟器和uiautomator2模块进行APP数据采集的基础知识和步骤。
网络爬虫,也称为网页蜘蛛或自动索引程序,是一种自动浏览互联网并收集信息的程序。
网络爬虫的应用终端并不是特定的设备或硬件,而是指网络爬虫可以从哪些地方获取和抓取数据。这些应用终端涵盖了互联网的各个方面,包括但不限于:
网页(Web端)
移动应用(App端)
API接口(例如,社交媒体平台的API)
数据库(例如,公开可访问的政府数据库)
文件(例如,公开的PDF或文档)
然而,在这个广泛的列表中,我们主要关注两个应用终端:Web端和App端。这是出于两个原因:
普遍性:Web端和App端是互联网数据的主要来源。无论是新闻网站、社交媒体平台、电子商务网站,或是手机应用,它们都可以归类为Web端或App端。
多样性:Web端和App端提供的数据类型丰富多样,包括文本、图片、视频、用户评论、商品信息、地理位置等。这使得我们可以应用网络爬虫来处理各种各样的问题和项目。
在接下来的学习中,我们将深入研究Web端和App端的网络爬虫技术。我们会学习如何编写网络爬虫来获取和处理来自这些终端的数据,如何优雅地处理可能遇到的问题,以及如何在尊重隐私和遵守法律的前提下进行数据采集。
具体在本章中,我们将学习如何使用Windows采集工具(后裔采集器)来进行数据采集,以训练数字密文识别模型。我们将通过采集猫眼电影网站上的关于电影评分和电影票房的数字密文,为后续的模型训练打下基础。本章将重点介绍如何采集数据以及处理采集到的数字密文。
2.1 数据采集与准备
在进行数字密文识别的训练之前,我们需要准备大量的数字密文数据。猫眼电影网站提供了电影评分和票房等信息,这些信息被加密为数字密文形式。我们将通过后裔采集器自动化地采集这些数据。
我们看看chatgpt的提示:
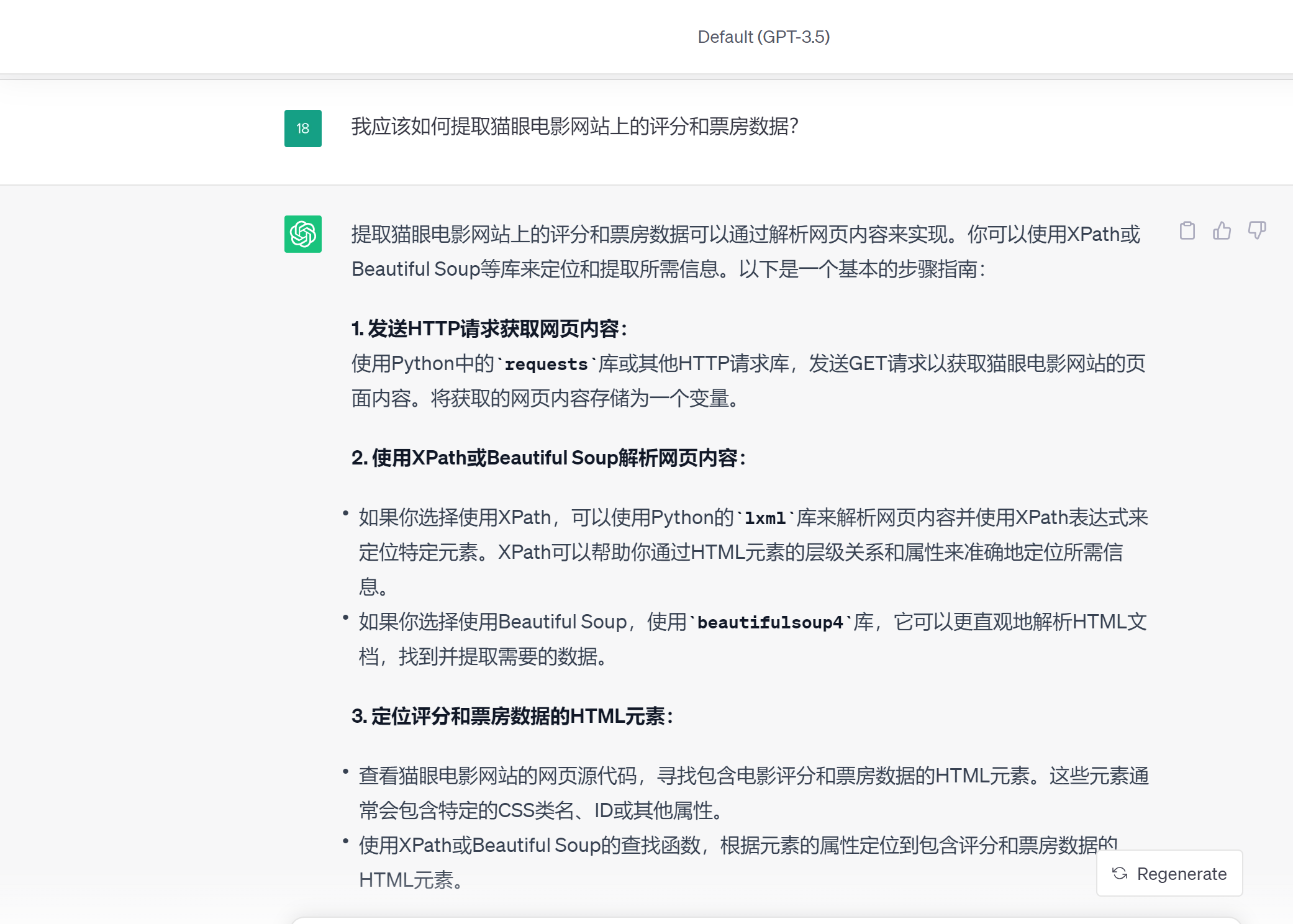
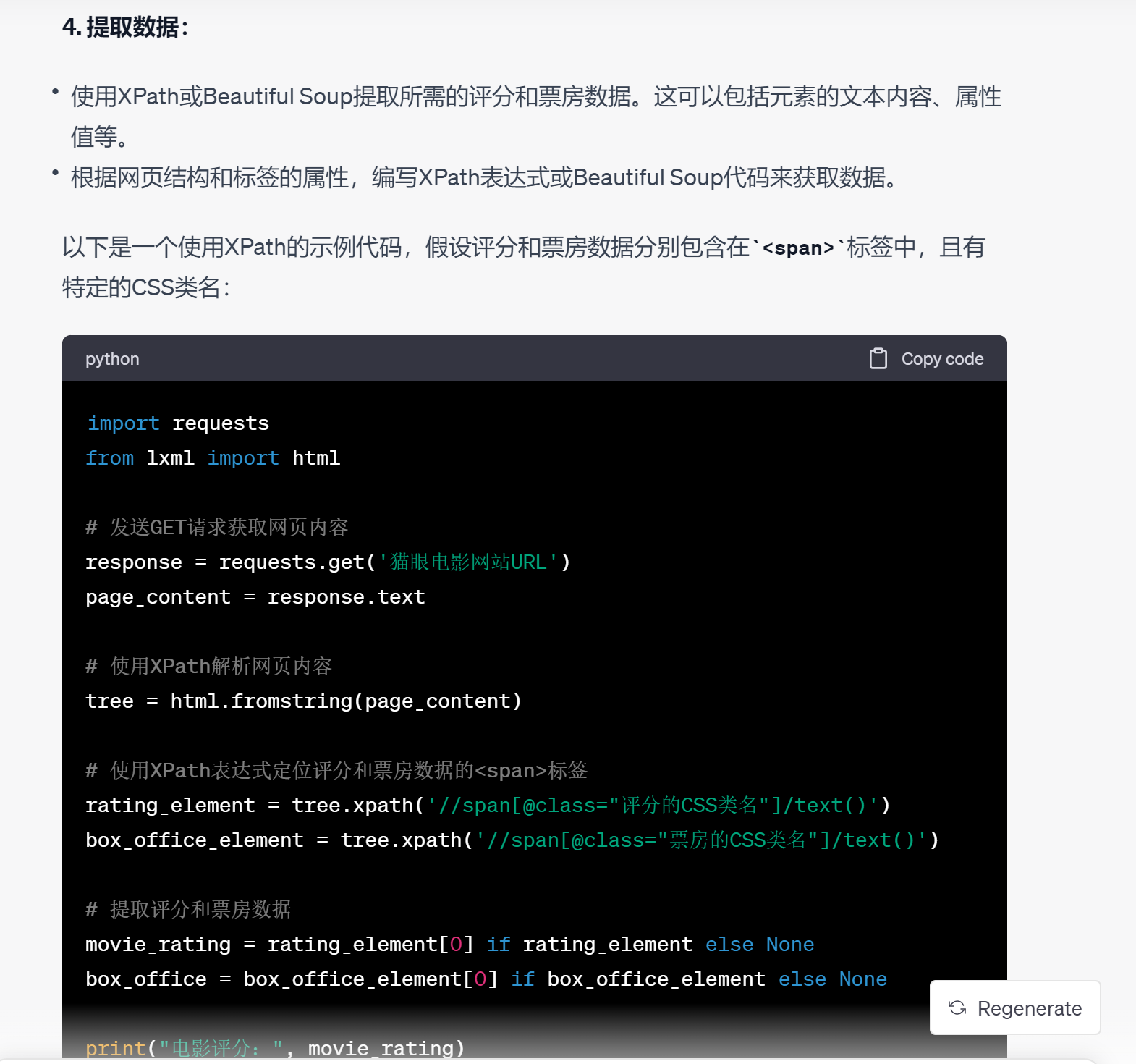
chatgpt给出的答案,是一个比较通用的数据采集的方法,从中可以看出数据采集采用的基本模块和函数代码,可以作为参考。在实际的数据采集中,一般会运用一些工具进行,能够提高工作效率。本课程主要采用后裔采集器。
2.1.1 首页采集
首先,我们将配置后裔采集器,模拟用户访问猫眼电影网站的首页。
-
用chrome浏览器,进入需要采集数据网页,拿到它的URL,本次采集的URL='经典影片_电影大全_经典高清电影-猫眼电影'。
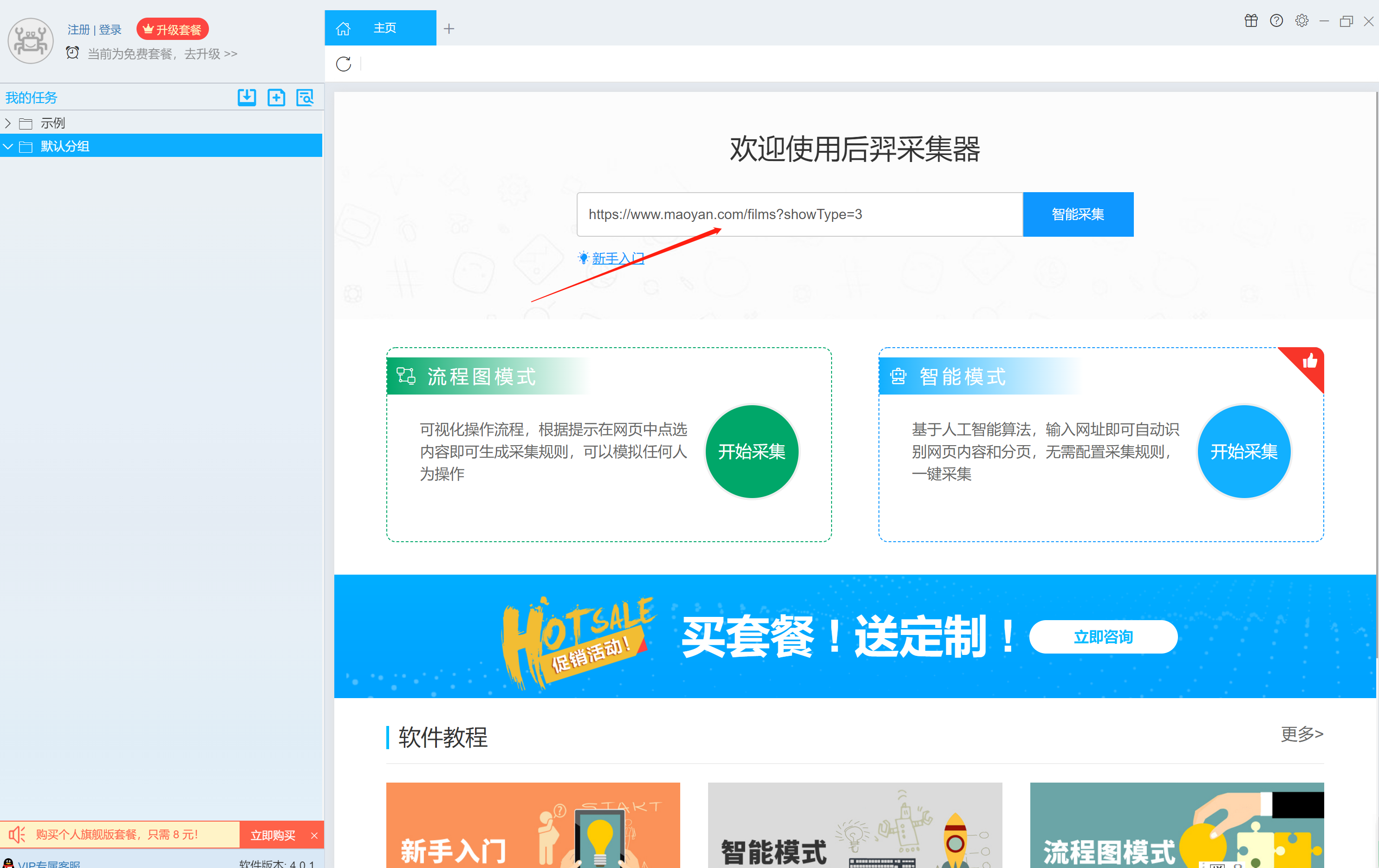
2.打开后裔采集器首页,输入所采集网页的地址
3.打开智能采集的按钮,进入首页采集界面,我们看到有些字段已经被锁定在采集范围内了。
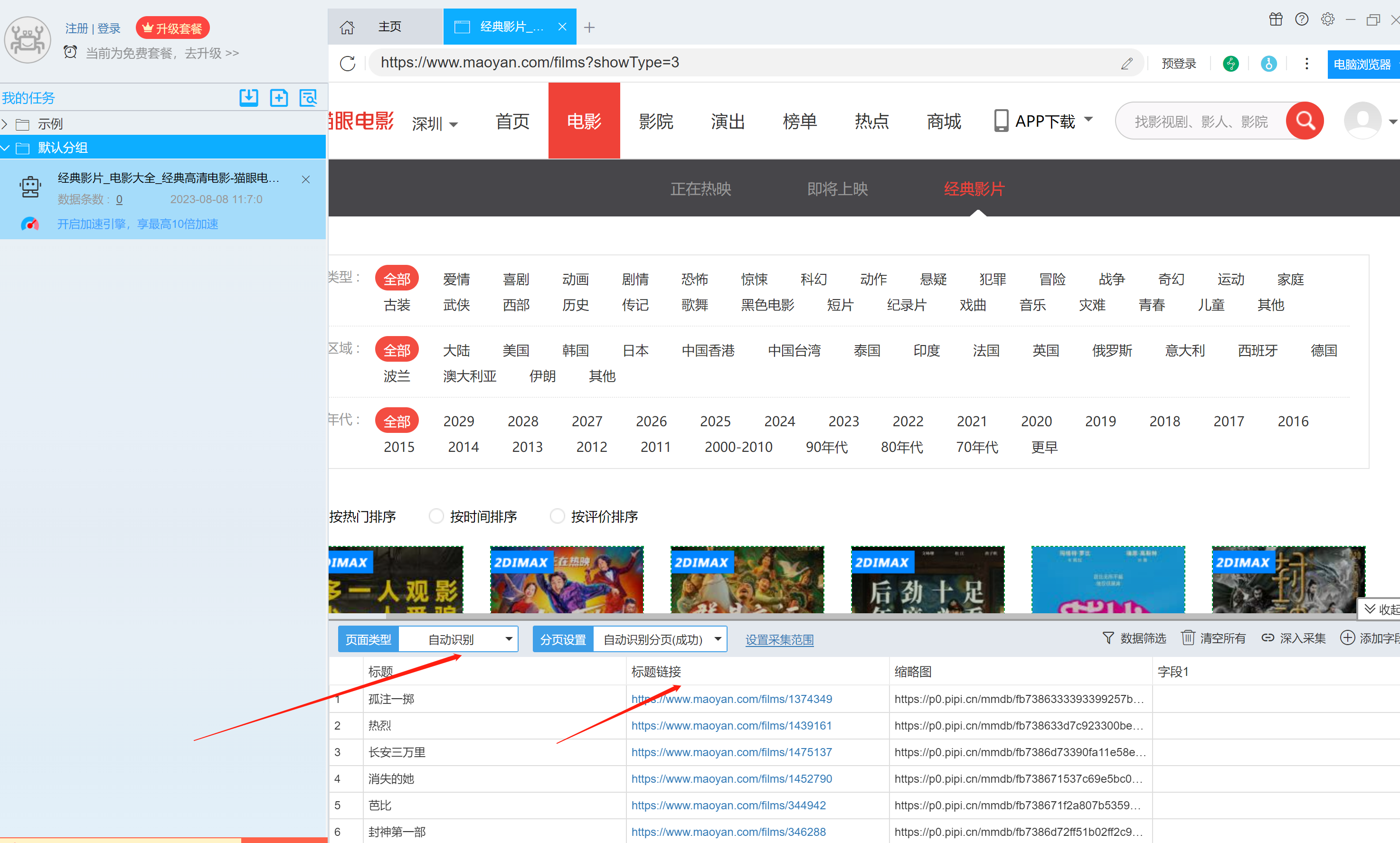
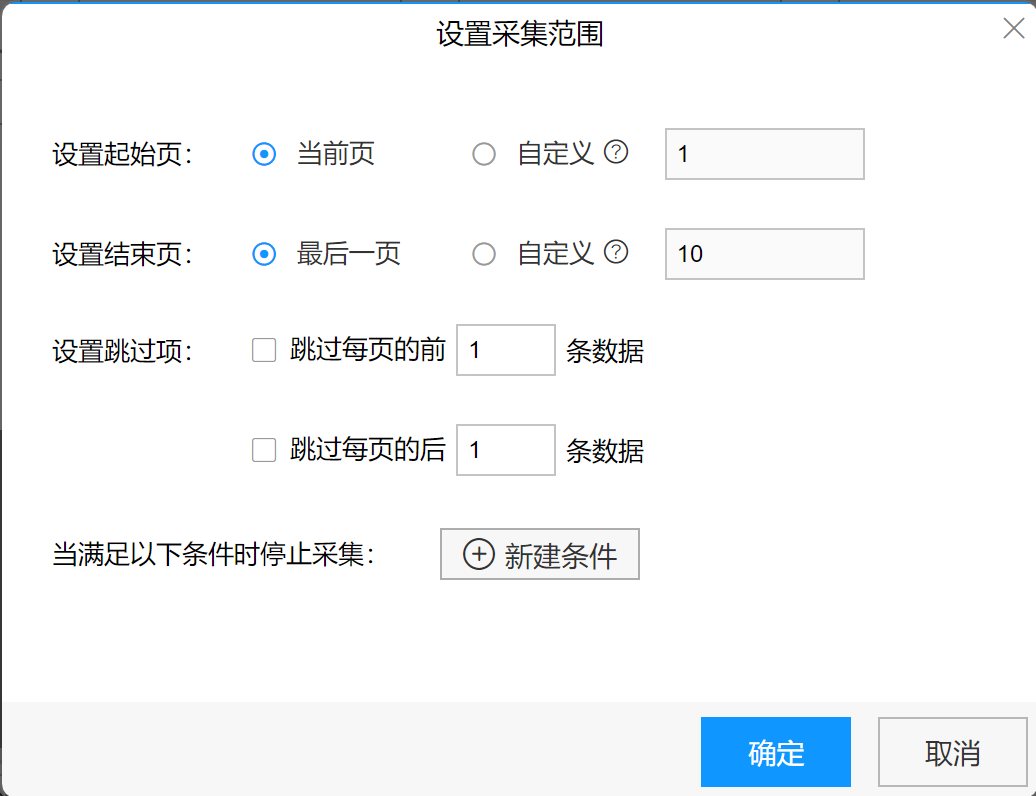
4.点击采集范围,设置好采集的页数,本次我们设置为1-10页。
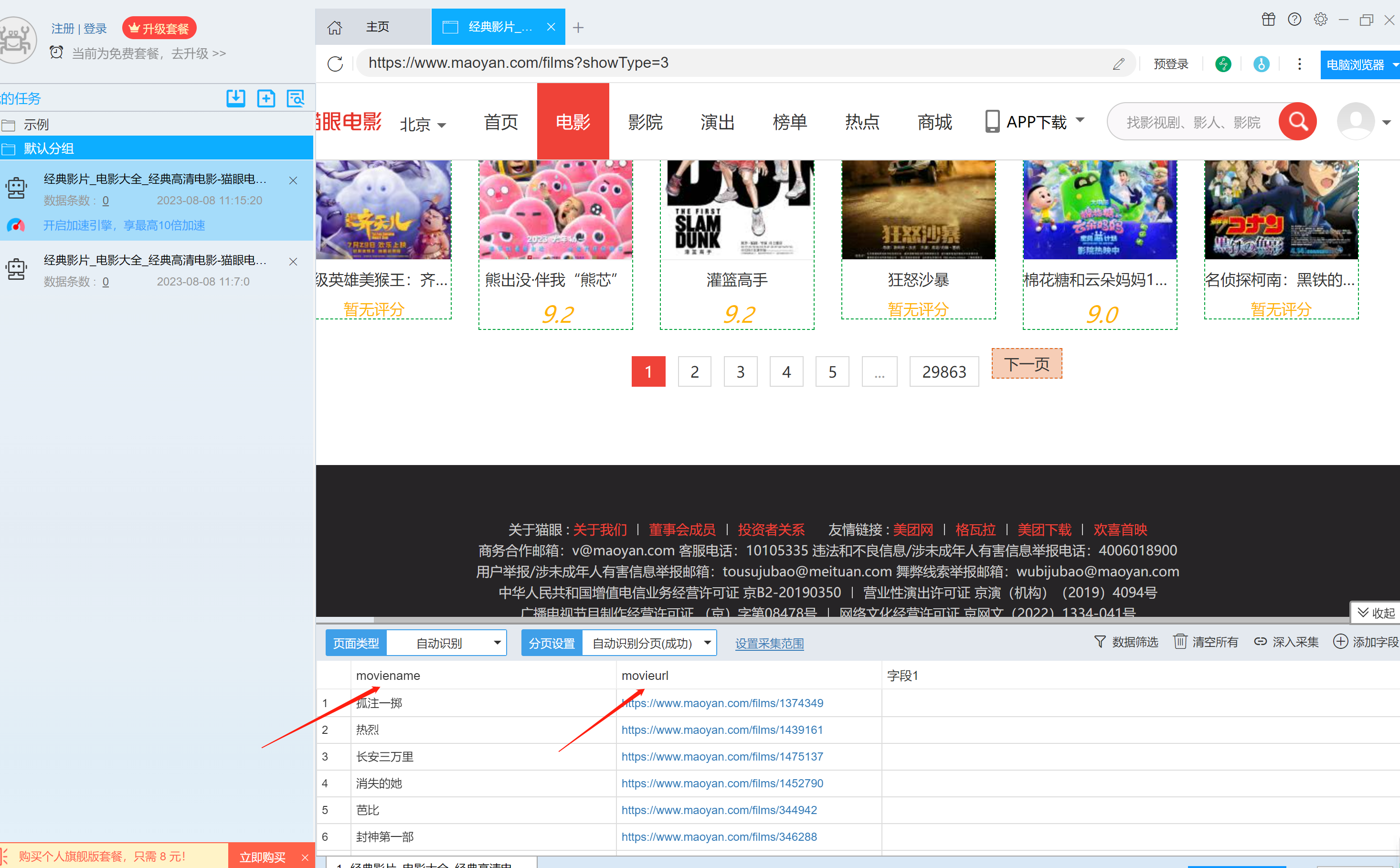
5.点击采集数据字段的列,鼠标右键可以修改字段的名称、删除不需要的字段,这里我们把电影名字和链接两个字段所在的列,修改了名字,并删除了不必要的字段。
2.1.2详情页采集
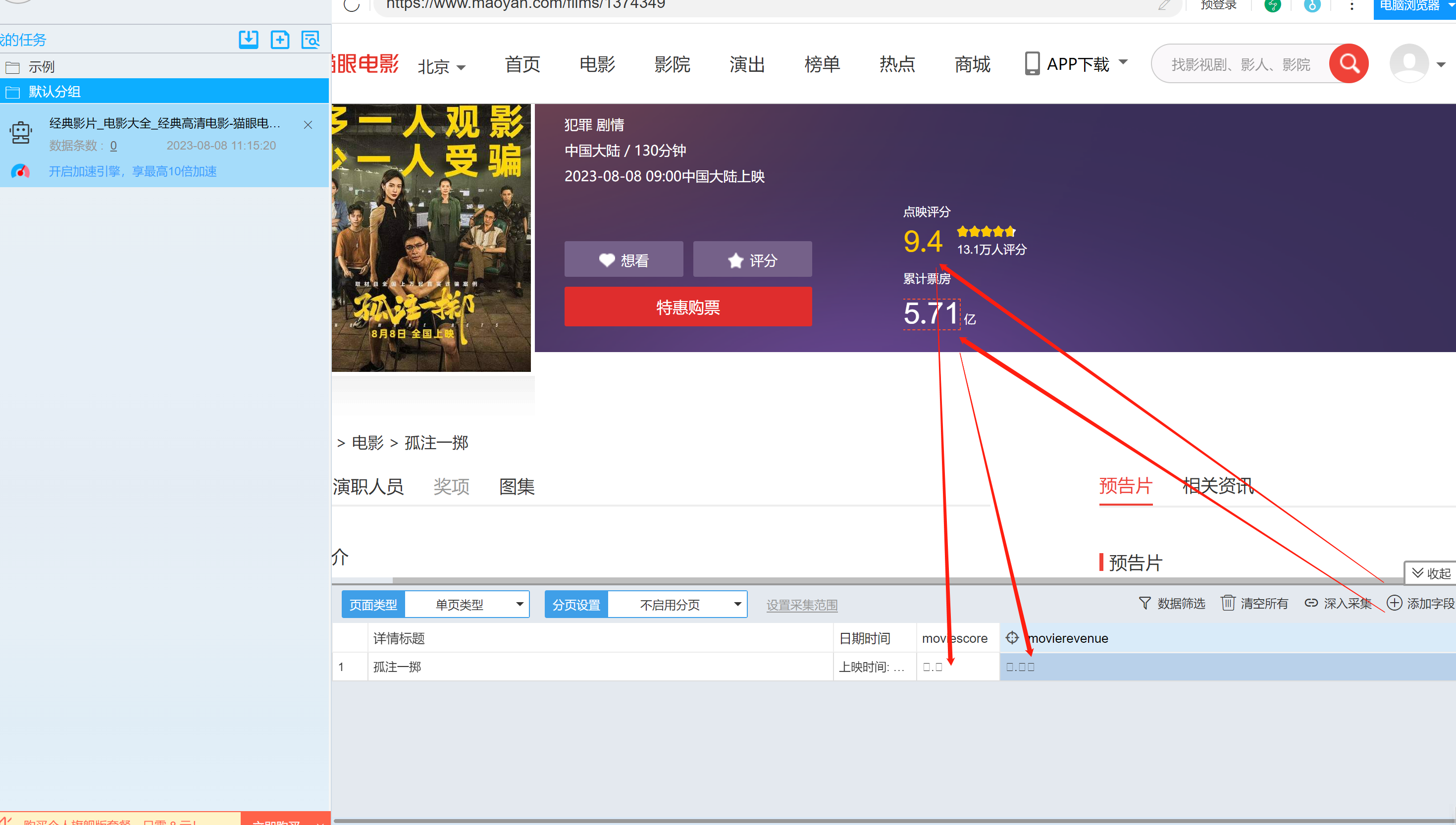
6.点击深入采集进入电影链接的详情页数据的采集。
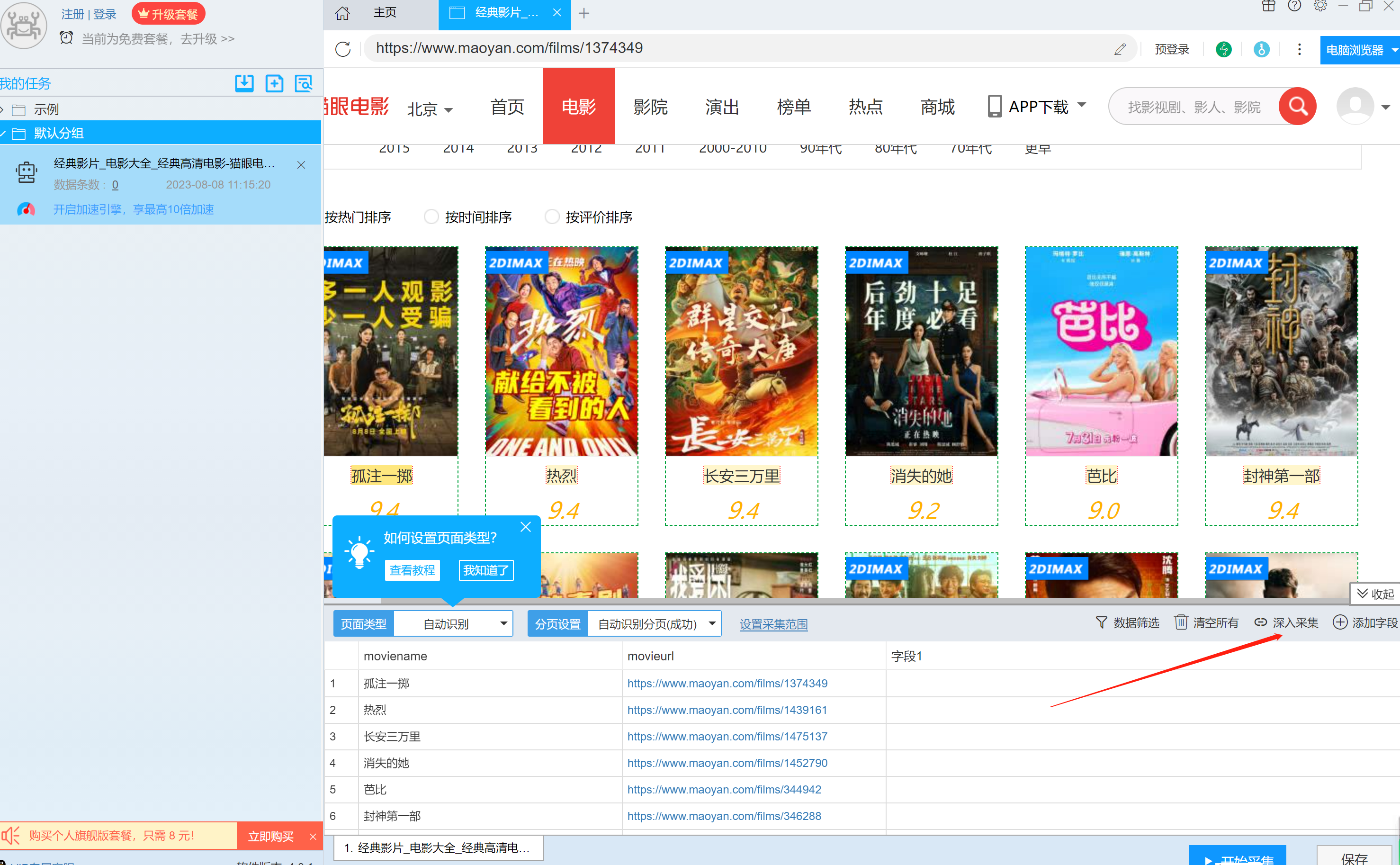
7.点击添加字段,并点击要添加的内容,如“评分”和“票房”,将数据采集下来,并修改字段名字分别为moviescore、movierevenue。数据采集下来后,我们会发现在网页上可以看到的评分和票房数据,采集下来后确是加密后的内容。因此需要我们进一步找出密文的密钥。
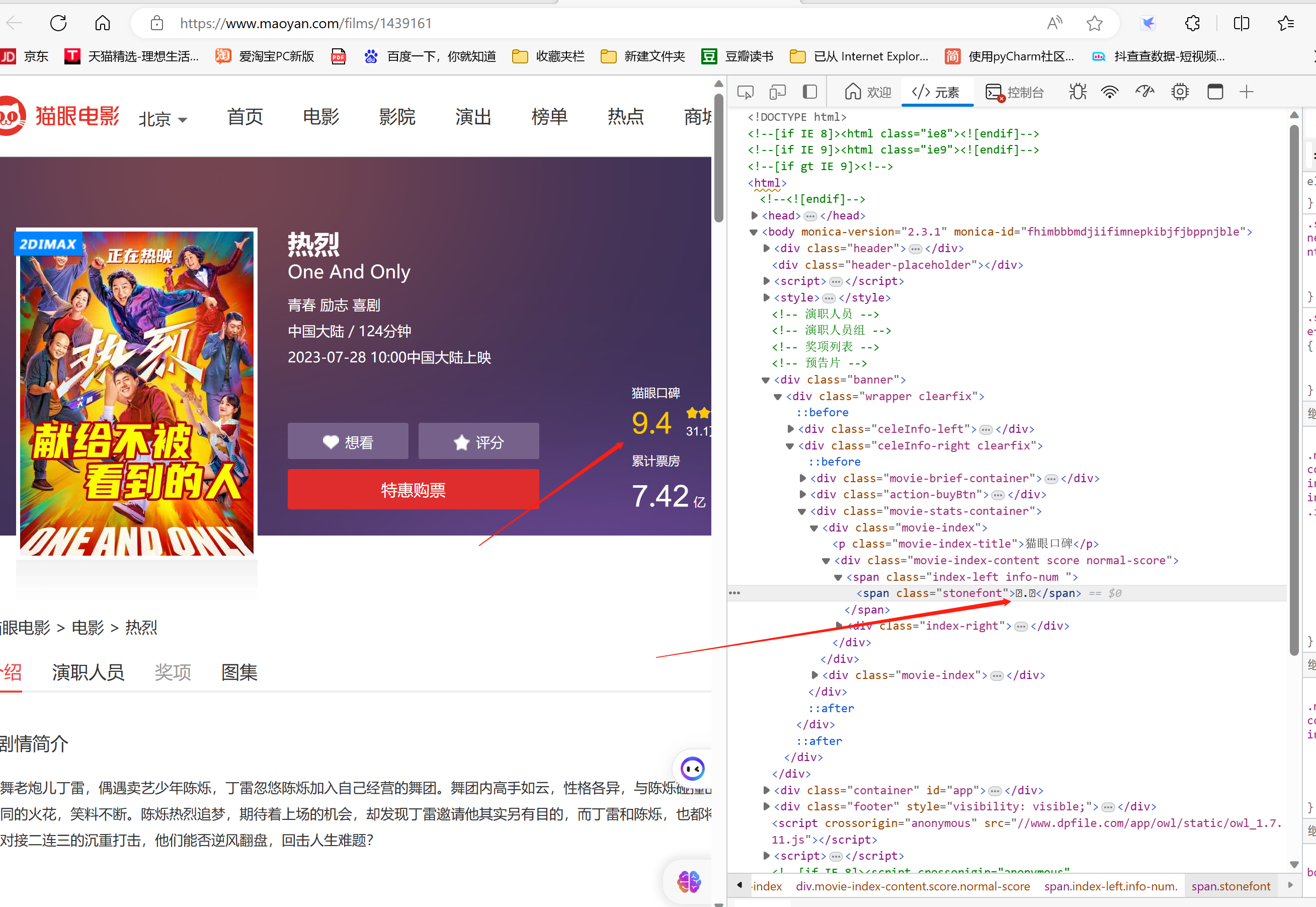
8.通过打开检查中的元素(element)栏目发现,评分的分数确实被加密了。
9.然后我们打开检查中的网络栏目,重新加载一下,发现一个加载项目含有网页信息的(1439161),属于ajax的加载类型,因此加载的内容应该在该项目之中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











