







【人工智能之大模型】详细介绍Post-LayerNorm和Pre-LayerNorm的区别?
【人工智能之大模型】详细介绍Post-LayerNorm和Pre-LayerNorm的区别?
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.youkuaiyun.com/gaoxiaoxiao1209/article/details/146477488
前言
在 Transformer 模型的设计中,Post-LayerNorm 和 Pre-LayerNorm 是两种不同的 Layer Normalization 的应用方式。
- 它们之间的主要区别在于 LayerNorm 的位置,具体来说,Pre-LayerNorm 和 Post-LayerNorm 分别指的是将 LayerNorm 放在每个子层的输入(Pre)还是输出(Post)的位置。
这两种方法的不同设计会影响训练过程的稳定性、收敛速度以及大模型在多任务学习中的表现。随着大模型的发展,了解这两种方式的差异和适用场景变得越来越重要。接下来,我会详细阐述它们的区别。
1. Post-LayerNorm(后置LayerNorm)
在 Post-LayerNorm 中,LayerNorm 应用于每个子层(如自注意力或前馈神经网络)的 输出。
结构:
- 输入 → 子层计算(例如自注意力或前馈层) → LayerNorm → 激活(例如 ReLU)→ 输出
优点:
- 在一些实验中,Post-LayerNorm 被发现能更好地训练深层网络,因为它可以减少模型中梯度消失和爆炸的风险。即便在非常深的模型中(例如 GPT-3、BERT 等大模型),Post-LayerNorm 仍能保持较为稳定的训练。
- 它在 梯度流 上表现较好,尤其是对于较深的网络。经过归一化的输出通常能保持较好的梯度流动,避免了梯度在深层网络中的消失。
- 许多标准的 Transformer 变体(如 GPT)使用 Post-LayerNorm,并且在许多自然语言处理任务中表现出色。
缺点:
- 它可能会导致一些 慢收敛 问题,尤其是在模型较浅或者某些特定任务中。
2. Pre-LayerNorm(前置LayerNorm)
在 Pre-LayerNorm 中,LayerNorm 应用于子层的 输入,也就是说,LayerNorm 在每个子层计算之前就已完成。
结构:
- 输入 → LayerNorm → 子层计算(例如自注意力或前馈层) → 激活(例如 ReLU)→ 输出
优点:
- 在 Pre-LayerNorm 中,数据经过标准化后再输入到每个子层,这有助于防止梯度爆炸和梯度消失,特别是在训练大模型时,它能更有效地促进收敛,避免训练过程中模型的不稳定性。
- 它对 浅层网络 或 较小模型 更为有效,尤其是在训练初期,能够确保模型在较小的参数空间内稳定地收敛。
- 在一些 Transformer 变种(如 Transformer-XL 和 T5)中,使用 Pre-LayerNorm 后,实验表明可以加速收敛并提高稳定性。
缺点:
- 在一些深层网络中(例如 GPT-3),Pre-LayerNorm 可能会出现梯度较小的情况,导致训练变得不那么稳定。
- Pre-LayerNorm 在大规模预训练的 Transformer 模型中可能并没有表现得比 Post-LayerNorm 更好。
3. 对比分析
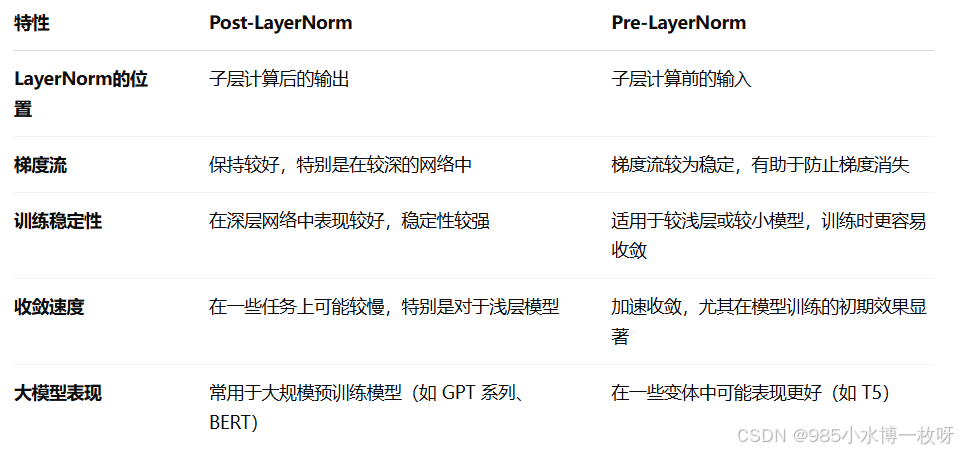
4. 当前大模型的应用趋势
随着 Transformer 模型的不断发展,尤其是在 大规模预训练 模型(如 GPT、T5、BERT)中,Post-LayerNorm 已成为 主流选择。原因在于:
- 大规模模型的训练 需要较强的梯度流动,Post-LayerNorm 更能在深层网络中保证稳定性,避免梯度消失或爆炸。
- 长序列建模 需要处理复杂的依赖关系,Post-LayerNorm 能有效地应对这一挑战。
然而,Pre-LayerNorm 也有其独特的优势,特别是在 浅层模型 或 小批量数据 的训练中。随着 Transformer 变体的发展,一些小型任务或特定的优化目标也可能倾向于使用 Pre-LayerNorm,例如在 低资源环境 或 自监督学习 中的应用。
5. 未来发展前景
随着大模型的快速发展,Pre-LayerNorm 和 Post-LayerNorm 可能会在不同的任务中交替使用。
- 对于任务复杂、需要强大表示能力的大模型,Post-LayerNorm 依然是主流的选择。而在一些更小的任务、计算资源有限的情况下,Pre-LayerNorm 可能会成为一个更好的选择。
- 此外,随着 更复杂的归一化技术(例如 GroupNorm、InstanceNorm 或 RMSNorm)的提出,Post-LayerNorm 和 Pre-LayerNorm 可能会继续进化,以适应未来更加多样化的模型需求。
总结
- Post-LayerNorm 和 Pre-LayerNorm 主要的区别在于 LayerNorm 在 Transformer 层中应用的时机:Post-LayerNorm 将 LayerNorm 放在子层输出之后,而 Pre-LayerNorm 将其放在输入之前。
- 两者各有优缺点,且在不同规模的模型中表现不同。对于大模型,Post-LayerNorm 在稳定性和性能上通常具有更好的表现,而 Pre-LayerNorm 更适合于较小或浅层模型,能够更快地收敛。
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.youkuaiyun.com/gaoxiaoxiao1209/article/details/146477488



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











