







 本文介绍了使用R语言进行前向逐步回归的原理和步骤,包括数据导入、分组、特征选择及模型效果评估。通过遍历属性子集,每次选择最优特征加入集合,以最小化测试集误差。
本文介绍了使用R语言进行前向逐步回归的原理和步骤,包括数据导入、分组、特征选择及模型效果评估。通过遍历属性子集,每次选择最优特征加入集合,以最小化测试集误差。
R语言实现前向逐步回归
前向逐步回归原理
前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性。接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集。以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集。这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加。
数据导入并分组
导入数据,将数据集抽取70%作为训练集,剩下30%作为测试集。特征与标签分开存放。
导入数据
R语言的实现如下图:

train和test中存储的数据情况如下:
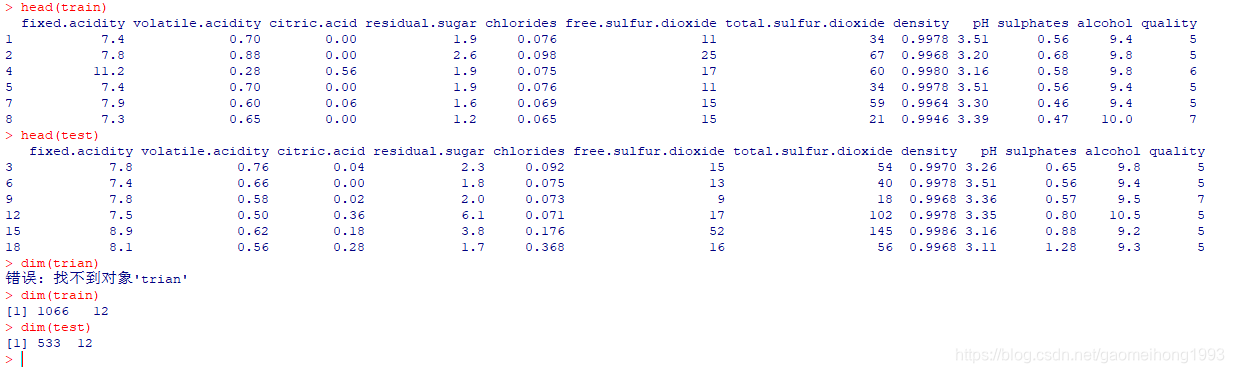
特征与标签分开存放
R语言的实现如下图:
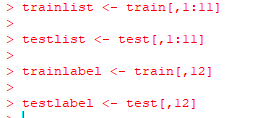
前向逐步回归构建输出特征集合
通过for循环,从属性的一个子集开始进行遍历。第一次遍历时,该子集为空。每一个属性被加入子集后,通过线性回归来拟合模型,并计算在测试集上的误差,每次遍历选择得到误差
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









