







一、为什么需要熔断
比如,我们的应用是微服务A调用微服务B和微服务C来完成的,而微服务B又需要调用微服务D,微服务D又需要调用微服务E。如果在调用的链路上对微服务E的调用,响应时间过长或者服务不可用,那么对微服务D的调用就会占用越来越多的系统资源,进而引起微服务D的系统崩溃,微服务D的不可用,又会连锁反应的引起微服务B崩溃,进而微服务A崩溃,最终导致整个应用不可用。这也就是所谓的“雪崩效应”,所以熔断尤为重要。
二、Sentinel以三种方式衡量被访问的资源是否处理稳定的状态
1 平均响应时间 (DEGRADE_GRADE_RT):当资源的平均响应时间超过阈值(DegradeRule 中的 count,以 ms 为单位)之后,资源进入准降级状态。接下来如果持续进入 5 个请求,它们的 RT 都持续超过这个阈值,那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回(抛出 DegradeException)。在下一个时间窗口到来时, 会接着再放入5个请求, 再重复上面的判断.
2 异常比例 (DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
3 异常数 (DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。
三、代码实现
1、改造/order/{orderNo}接口
为达到效果,我们这接口直接抛出运行异常,自定义异常fallbackHandler处理熔断异常
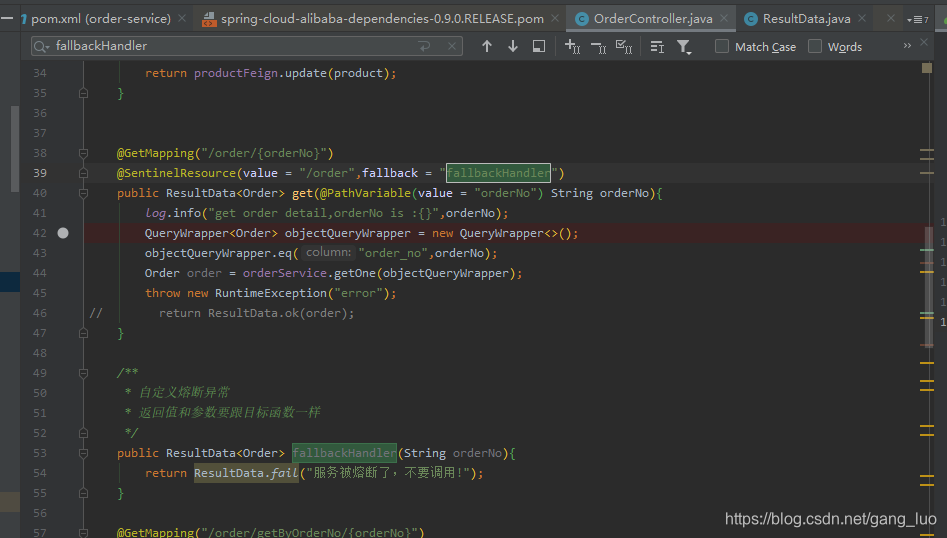
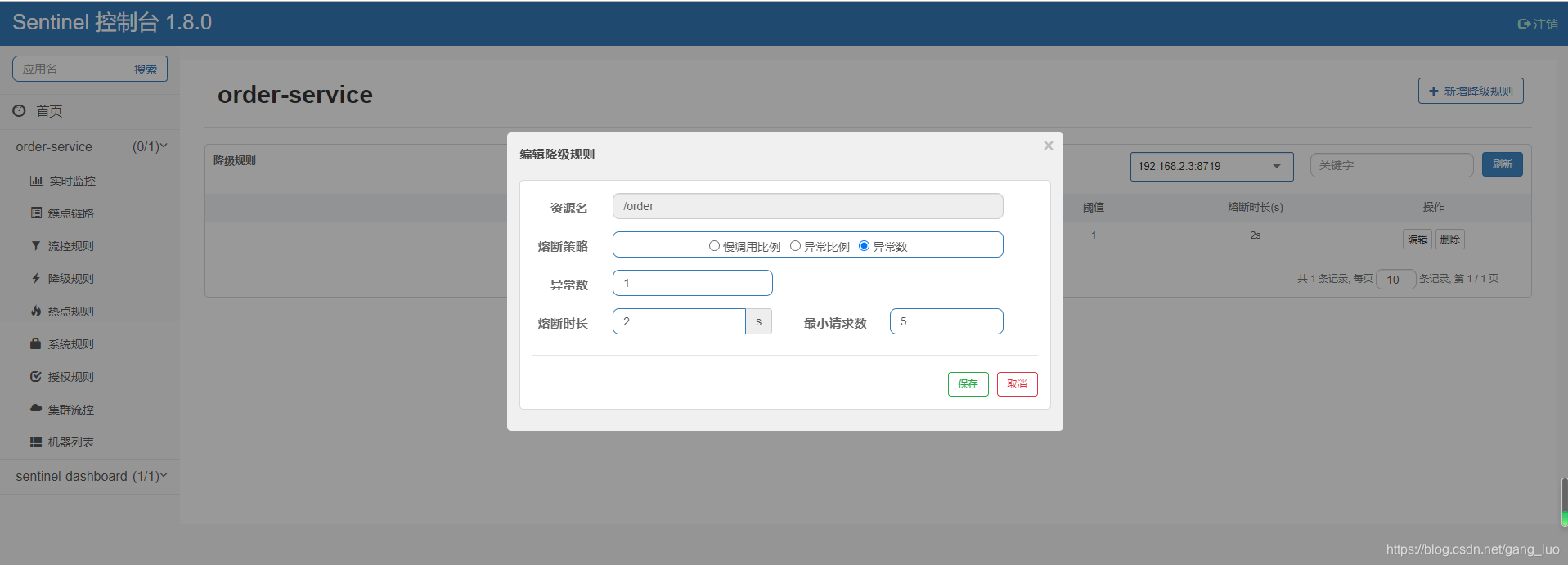
2、sentinel控制台新增降级规则
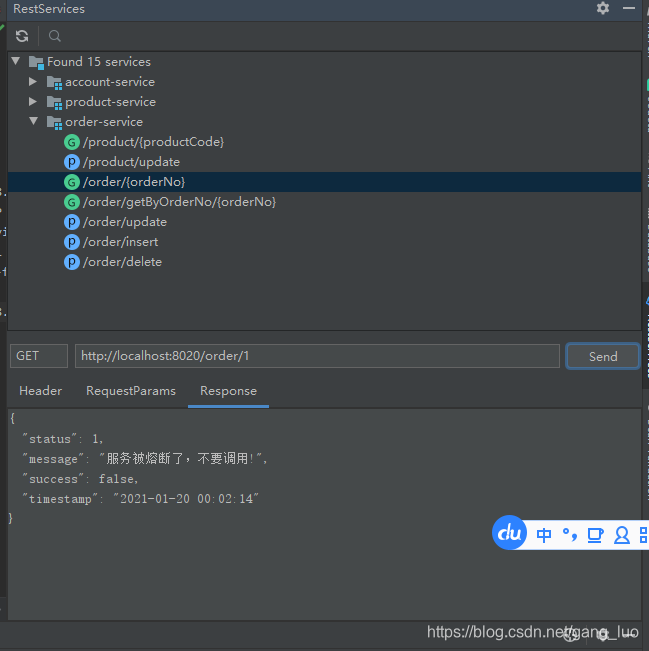
3、调用接口测试
四、持久化配置到nacos
1、引入sentinel-datasource-nacos组件
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>2、添加配置文件
ds2:
nacos:
server-addr: 192.168.2.6:8001
namespace: 9bb83945-f4a3-4839-8d3b-363f1b78db36
dataId: ${spring.application.name}-sentinel-degrade
group: DEFAULT_GROUP
data-type: json
rule-type: degrade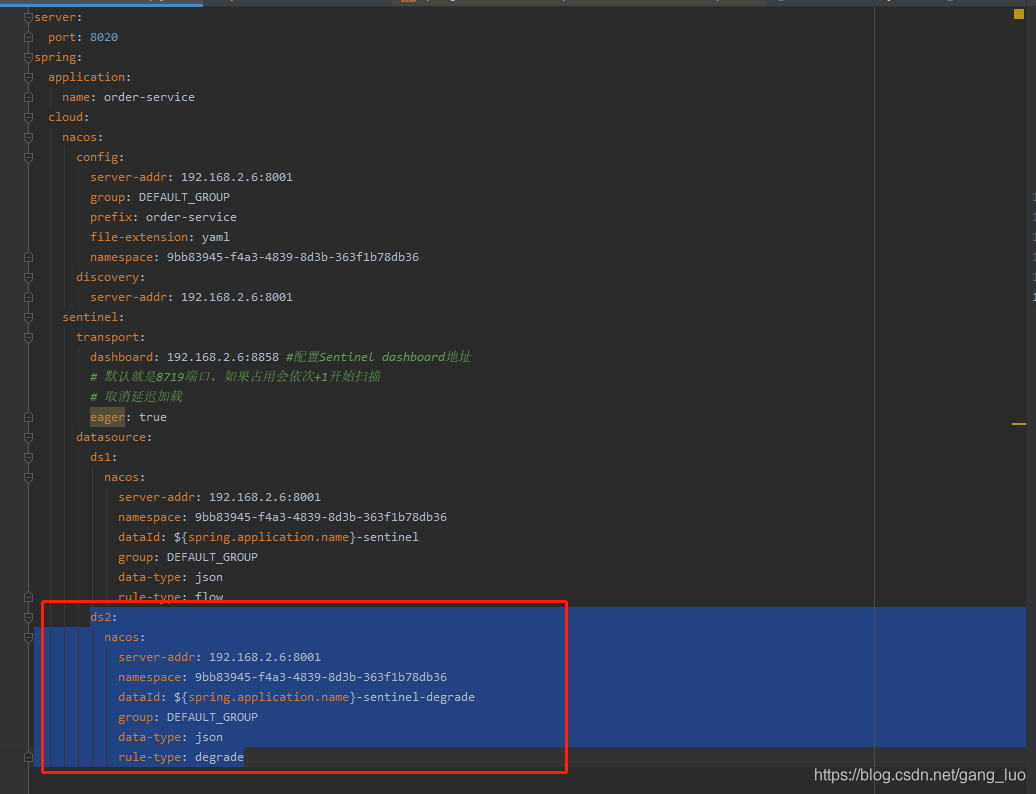
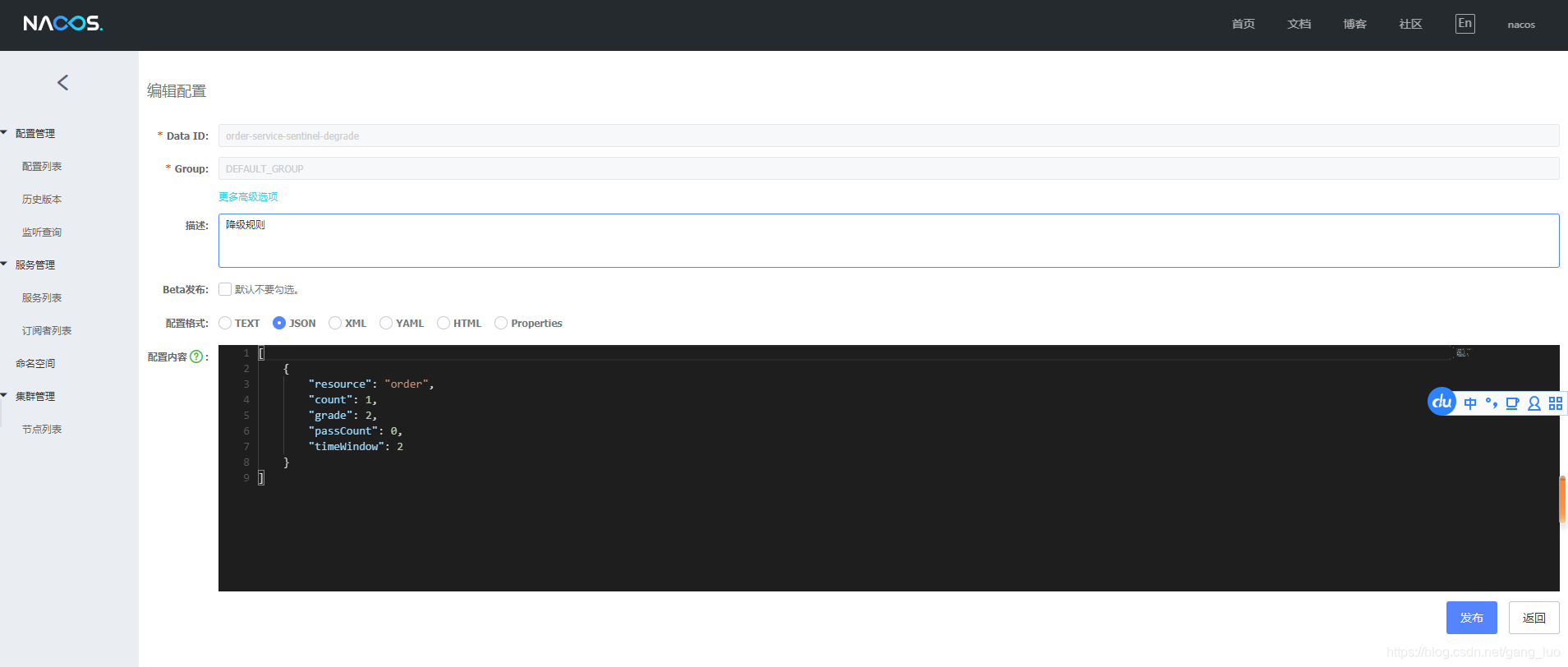
3、nacos添加配置
[
{
"resource": "order",
"count": 1,
"grade": 2,
"passCount": 0,
"timeWindow": 2
}
]可以看到上面配置规则是一个数组类型,数组中的每个对象是针对每一个保护资源的配置对象,每个对象中的属性解释如下:
resource:资源名,即降级规则的作用对象count:阈值grade:降级模式 0:RT 1:异常比例 2:异常数timeWindow:时间窗口(单位秒)
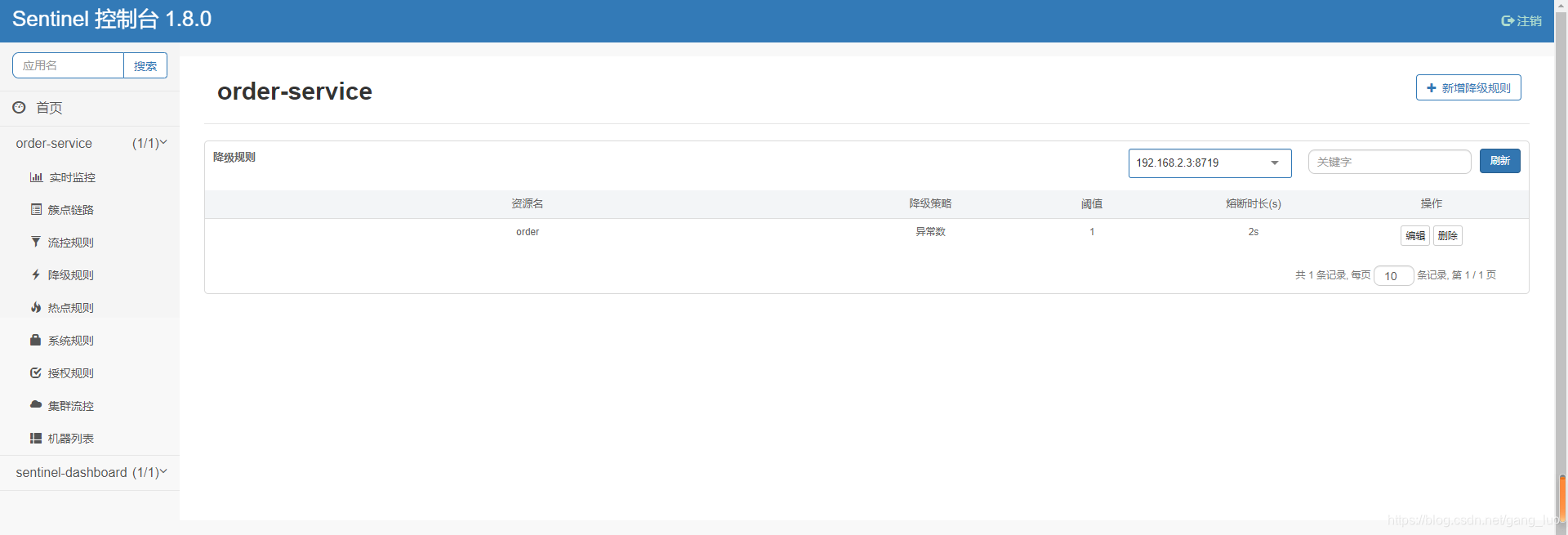
4、sentinel查看降级规则
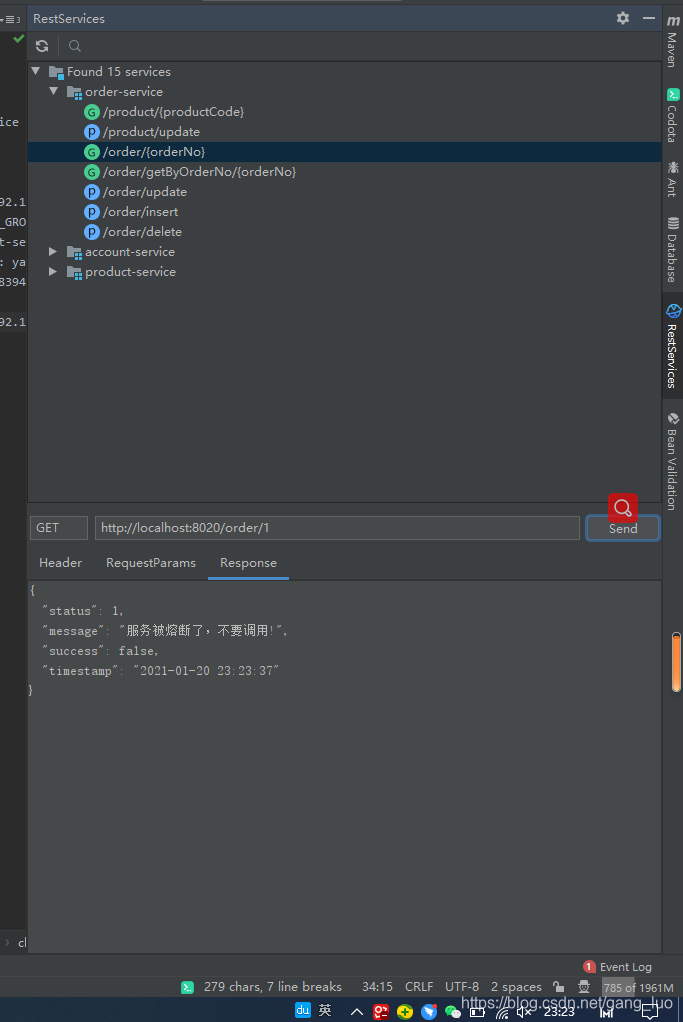
5、调用接口验证流控规则是否生效


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









