




场景:用python, BeautifulSoup构建爬虫获取网页信息。
问题:标签内容缺失。
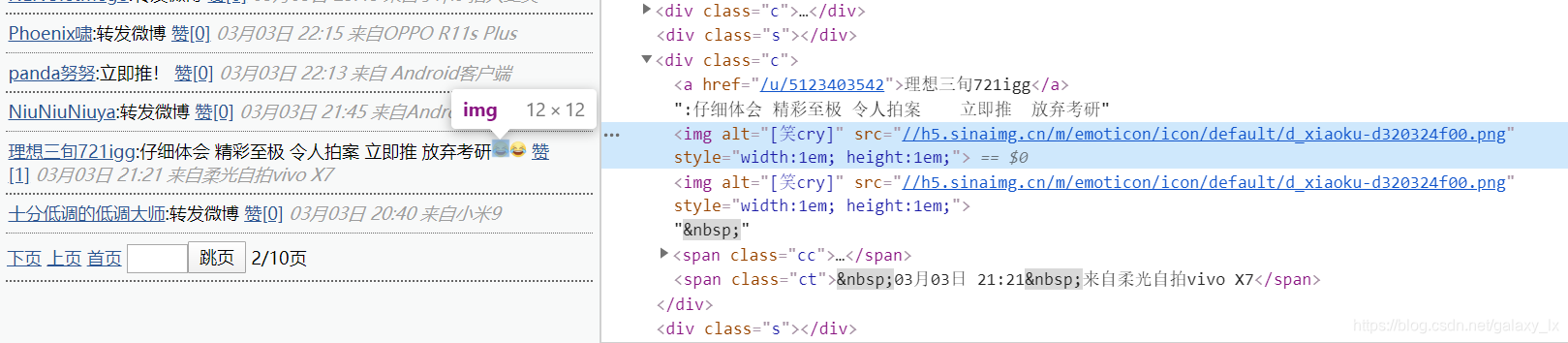
描述:例如,爬虫在爬取<div class='c'>标签中的文本文字,当爬完<a>标签下的文字即:‘仔细体会 精彩至极 令人拍案 立即推 放弃考研’后,下面的文字信息即‘03月03日 21:21 来自柔光自拍vivo X7’会无法被获取到。
解决方案:(大概是html.parser的问题)
按如下修改:
![]()
 本文探讨了使用Python和BeautifulSoup构建爬虫时遇到的标签内容缺失问题,特别是在爬取<div>标签内文本时,部分信息未能正确获取。文章提供了可能的解决方案,涉及html.parser的使用调整。
本文探讨了使用Python和BeautifulSoup构建爬虫时遇到的标签内容缺失问题,特别是在爬取<div>标签内文本时,部分信息未能正确获取。文章提供了可能的解决方案,涉及html.parser的使用调整。
场景:用python, BeautifulSoup构建爬虫获取网页信息。
问题:标签内容缺失。
描述:例如,爬虫在爬取<div class='c'>标签中的文本文字,当爬完<a>标签下的文字即:‘仔细体会 精彩至极 令人拍案 立即推 放弃考研’后,下面的文字信息即‘03月03日 21:21 来自柔光自拍vivo X7’会无法被获取到。
解决方案:(大概是html.parser的问题)
按如下修改:
![]()

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 2007
2007





