






 博客介绍斗鱼直播分页数据爬取方法。此前已实现单页房间数据爬取,此次聚焦翻页操作,介绍两种方法:一是结合无界面浏览器 Selenium 与 PantomJS;二是通过 ajax 异步请求,关键在于找到分页接口,如 'https://www.douyu.com/gapi/rkc/directory/0_0/%s' % 页数。
博客介绍斗鱼直播分页数据爬取方法。此前已实现单页房间数据爬取,此次聚焦翻页操作,介绍两种方法:一是结合无界面浏览器 Selenium 与 PantomJS;二是通过 ajax 异步请求,关键在于找到分页接口,如 'https://www.douyu.com/gapi/rkc/directory/0_0/%s' % 页数。
前面我们已经实现了斗鱼直播单页房间数据的爬取,
具体代码实现在我的博客:https://blog.youkuaiyun.com/g_optimistic/article/details/89944897
现在只讲翻页操作,以下有两种方法:
目录
1.使用无界面浏览器 Selenium 与PantomJS的结合
1.使用无界面浏览器 Selenium 与PantomJS的结合
当点击下一页的时候,如下图找到的那个标签 li 的属性 aria-disabled="true"的时候,就没有下一页了。

代码实现:
from selenium import webdriver
from lxml import etree
import time
def get_data(content):
tree = etree.HTML(content)
li_list = tree.xpath('//ul[@class="layout-Cover-list"]/li')
print(len(li_list))
i = 0
for li in li_list:
i += 1
print('===================第%s个房间======================' % i)
room_name = li.xpath('.//h3[@class="DyListCover-intro"]/text()')
print("房间名称", room_name[0])
room_tag = li.xpath('.//span[@class="DyListCover-zone"]/text()')
print("房间标签:", room_tag[0])
room_player = li.xpath('.//h2[@class="DyListCover-user"]/text()')
print("主播:", room_player[0])
room_follows = li.xpath('.//span[@class="DyListCover-hot"]/text()')
print("关注数:", room_follows[0])
return tree
# 创建浏览器
driver = webdriver.PhantomJS()
# 1.访问首页
page = 1
driver.get('https://www.douyu.com/directory/all')
time.sleep(5)
# 2.解析页面
tree = get_data(driver.page_source)
while True:
if tree.xpath('//li[@class=" dy-Pagination-next"]/@aria-disabled="true"') == 'true':
break
driver.find_element_by_class_name(' dy-Pagination-next').click()
time.sleep(3)
get_data(driver.page_source)
page += 1
print(page)
2.ajax异步请求,重点是找到接口
每次点击页数的时候,就会在network出现如下的XHR里面的文件,很有可能就写着和分页有关的东西
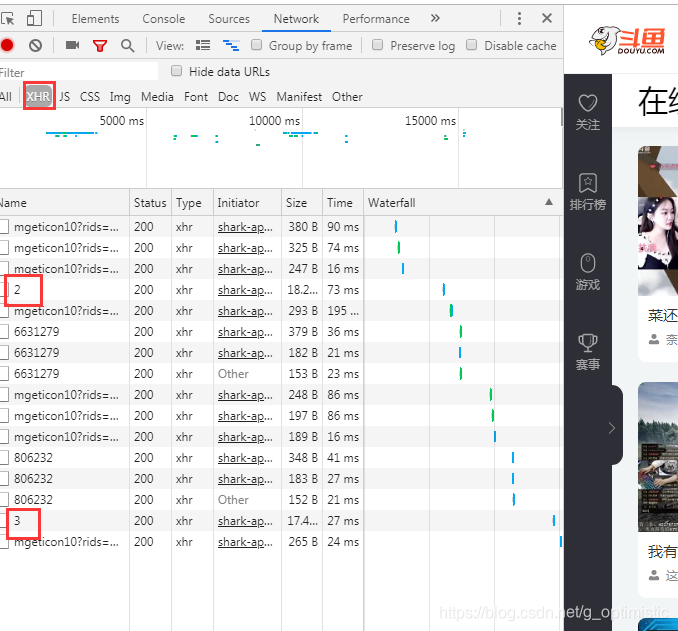
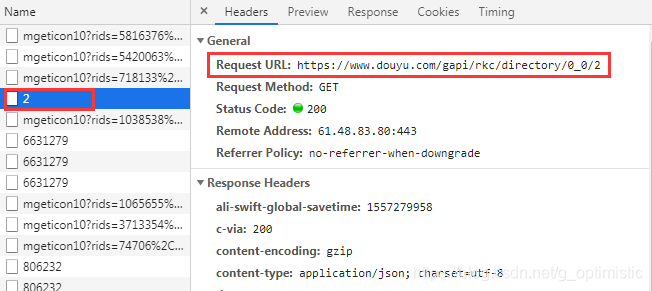
点开一个文件,看看他的请求头:得出以下规律
真正分页的接口是: 'https://www.douyu.com/gapi/rkc/directory/0_0/%s' % 页数
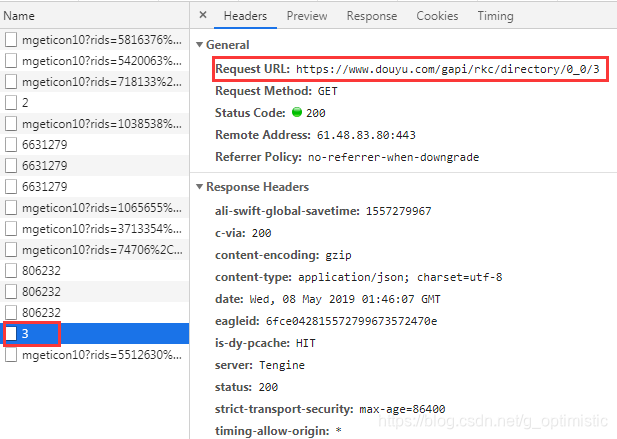
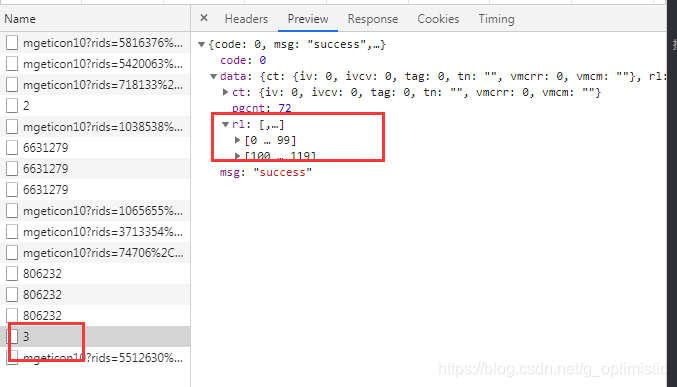
找到接口之后,看一下他的response的内容:

开始请求,代码如下:
import requests
page = 0
while True:
page += 1
print(
'-------------------------第%s页-----------------------------------------------------------------------------------------' % page)
url = 'https://www.douyu.com/gapi/rkc/directory/0_0/%s' % page
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
with open('templates\\douyu1.txt', 'w', encoding='utf-8') as fp:
fp.write(response.content.decode('utf-8'))
data_list = response.json()['data']['rl']
print("该页共查询到%s个房间" % len(data_list))
i = 0
for data in data_list:
i += 1
print("第%s个房间++++++++++++++++++++++++++++++++++++++++" % i)
room_name = data['rn']
room_tag = data['c2name']
room_player = data['nn']
room_follows = data['ol']
print("房间名称:", room_name)
print("主播:", room_player)
print("房间标签:", room_tag)
print("关注数:", room_follows)

















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









