







Java爬虫基础入门
小白一枚,最近在学爬虫,记录一下平常踩的坑。
HttpClient
网络爬虫就是用程序帮助我们访问网络上的资源,我们一直以来都是使用HTTP协议访问互联网网页,网络爬虫需要编写程序,这里同样是使用HTTP协议访问网页
这里使用Java的HTTP协议客户端HttpClient,来实现抓取网页数据
先导入依赖
<!--httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.10</version>
</dependency>
GET请求
// 创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建HttpGet对象,设置Url访问地址
HttpGet httpGet = new HttpGet("http://www.baidu.com");
CloseableHttpResponse response = null;
try {
// 使用HttpClient发起请求,获取response
response = httpClient.execute(httpGet);
// 解析响应
if(response.getStatusLine().getStatusCode() == 200){
String content = EntityUtils.toString(response.getEntity(), "utf-8");
System.out.println(content);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(response != null){
response.close();
}
if(httpClient != null){
httpClient.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
带参数的GET请求
// 创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
try {
// 设置请求地址是 https://www.baidu.com/s?ie=UTF-8&wd=java
// 创建URIBuilder
URIBuilder uriBuilder = new URIBuilder("https://www.baidu.com/s");
//设置参数
uriBuilder.addParameter("ie", "UTF-8").addParameter("wd", "java");
// 创建HttpGet对象,设置Url访问地址
HttpGet httpGet = new HttpGet(uriBuilder.build());
// 使用HttpClient发起请求,获取response
response = httpClient.execute(httpGet);
// 解析响应
if(response.getStatusLine().getStatusCode() == 200){
String content = EntityUtils.toString(response.getEntity(), "utf-8");
System.out.println(content);
}
} catch (IOException | URISyntaxException e) {
e.printStackTrace();
} finally {
try {
if(response != null){
response.close();
}
if(httpClient != null){
httpClient.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
POST请求
// 创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建HttpGet对象,设置Url访问地址
HttpPost httpPost = new HttpPost("https://www.youkuaiyun.com/");
CloseableHttpResponse response = null;
try {
// 使用HttpClient发起请求,获取response
response = httpClient.execute(httpPost);
System.out.println("响应"+response);
// 解析响应
if(response.getStatusLine().getStatusCode() == 200){
String content = EntityUtils.toString(response.getEntity(), "utf-8");
System.out.println(content);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(response != null){
response.close();
}
if(httpClient != null){
httpClient.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
带参数的POST请求
// 创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建HttpGet对象,设置Url访问地址 //https://so.youkuaiyun.com/so/search/s.do?q=java
HttpPost httpPost = new HttpPost("https://so.youkuaiyun.com/so/search/s.do");
// 声明List集合,封装表单中的参数
List<NameValuePair> pairs = new ArrayList<>();
pairs.add(new BasicNameValuePair("q", "java"));
CloseableHttpResponse response = null;
try {
// 创建表单的entity对象
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(pairs,"utf-8");
// 设置表单中的entity对象到Post请求中
httpPost.setEntity(entity);
// 使用HttpClient发起请求,获取response
response = httpClient.execute(httpPost);
System.out.println("响应"+response);
// 解析响应
if(response.getStatusLine().getStatusCode() == 200){
String content = EntityUtils.toString(response.getEntity(), "utf-8");
System.out.println(content);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(response != null){
response.close();
}
if(httpClient != null){
httpClient.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
注意了,在获取完数据后,不能关闭HttpClient,由连接池管理
连接池
public class HttpClientPoolTest {
public static void main(String[] args) {
// 创建连接池管理器
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
// 设置最大连接数
cm.setMaxTotal(100);
// 设置每个主机的最大连接数
cm.setDefaultMaxPerRoute(10);
// 使用连接池管理器发起请求
doGet(cm);
// doGet(cm);
}
private static void doGet(PoolingHttpClientConnectionManager cm) {
// 不是每次创建新的HttpClient,而是从连接池中获取HttpClient
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(cm).build();
HttpGet httpGet = new HttpGet("http://10.211.39.193:8080/toPage?url=/yiyibook/manager/member");
// 配置请求信息
RequestConfig requestConfig = RequestConfig.custom()
//创建连接的最长时间,单位是毫秒
.setConnectTimeout(1000)
// 设置获取连接的最长时间,单位是毫秒
.setConnectionRequestTimeout(500)
// 设置数据传输的最长时间,单位是毫秒
.setConnectTimeout(10*1000)
.build();
// 给请求设置请求信息
httpGet.setConfig(requestConfig);
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
if(response.getStatusLine().getStatusCode() == 200){
String content = EntityUtils.toString(response.getEntity(), "utf8");
Document doc = Jsoup.parse(content);
String text = doc.getElementsByClass("navbar-page-title").first().text();
System.out.println(text);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if(response!=null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
// 不能关闭HttpClient,由连接池管理
// httpClient.close();
}
}
}
}
Jsoup
当获取到网页源码之后,需要从网页源码中取出我们想要的内容,就可以使用jsoup这类HTML解析器了。可以非常轻松的实现。
引入依赖
<!--Jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
Jsoup解析的三种方式
解析Url
@Test
public void testUrl(){
try {
// 解析Url地址
Document doc = Jsoup.parse(new URL("http://www.baidu.com"),5000);
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
} catch (IOException e) {
e.printStackTrace();
}
}
解析字符串
示例
<title>她</title>
<h1>小歪</h1>
<h3 id = "city" class = "testClass01 testClass02">武汉</h3>
<div class = "div">
<span class = "li">武昌</span>
<span class = "li" abc = "123">汉口</span>
<span class = "li" def = "123"><b>汉阳</b></span>
<span class = "li" abc = "1">洪山</span>
</div>
@Test
public void testString(){
try {
// 使用工具类读取文件,获取字符串
String content = FileUtils.readFileToString(new File("F:\\桌面\\test.html"), "utf-8");
// 解析字符串
Document doc = Jsoup.parse(content);
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
} catch (IOException e) {
e.printStackTrace();
}
}
解析文件
@Test
public void testFile(){
try {
// 解析文件
Document doc = Jsoup.parse(new File("F:\\桌面\\test.html"), "utf-8");
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
} catch (IOException e) {
e.printStackTrace();
}
}
使用dom方式遍历文档
获取元素
根据id查询元素 getElementById
Element city = document.getElementById("city");
根据标签获取元素 getElementsByTag
Element span = document.getElementsByTag("span").first();
根据class获取元素 getElementsByClass
Element li = document.getElementsByClass("li").last();
根据属性获取元素 getElementsByAttribute
Element abc = document.getElementsByAttribute("abc").first();
Element first = document.getElementsByAttributeValue("abc","1").first();
元素中获取数据
从元素中获取 id
// 从元素中获取
idString id = element.id();
从元素中获取 className
// 从元素中获取
classNameString s = element.className();
Set<String> strings = element.classNames();
从元素中获取属性的值 attr
// 从元素中获取属性的值 attr 根据属性名获取属性值
String attr = element.attr("id");
从元素中获取所有属性 attributes
// 从元素中获取所有属性 attributes
Attributes attributes = element.attributes();
从元素中获取文本内容 text
// 从元素中获取文本内容 text
String text = element.text();
Selector选择器组合使用
el#id元素+ID, 比如: h3#city_bj
// 元素+ID h3#city
Elements city = document.select("h3#city");
el.class元素+class, 比如: li.class_a
// 元素+class
Elements li = document.select("span.li");
el[attr] 元素+属性名, 比如: span[abc]
// 元素+属性名
Elements abc = document.select("span[abc]");
任意组合 比如: span[abc].s_name
// 任意组合
Elements def = document.select("span[def].li");
ancestor child查找某个元素的下子元素, 比如: .city_con li 查找city_con下的所有li
// 查找某个元素的下子元素
Elements spanLi = document.select(".div span");
parent > child 查找某个父元素下的直接子元素, 比如: .city_con>ul>li 查找city_con第一级(直接子元素)的ul,再找所有ul下的第一级li
// 查找某个父元素下的直接子元素
Elements b = document.select("div>span>b");
parent >* 查找某个父元素下所有直接子元素
// 查找某个父元素下所有直接子元素
Elements elements = document.select("div>*");
Selenium
现在很多都是前后端分离项目,这会使得数据异步加载问题更加突出,所以我们在爬虫时遇到这类问题不必惊讶,不必慌张。
Selenium 是一个模拟浏览器,进行自动化测试的工具,它提供一组 API 可以与真实的浏览器内核交互。在自动化测试上使用的比较多,爬虫时解决异步加载也经常使用它
引入依赖
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
下载对应的 driver
例如 chromedriver,下载地址为:https://npm.taobao.org/mirrors/chromedriver/
下载后,需要将 driver 的位置写到 Java 的环境变量里
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
注意driver要与电脑本身的版本一致,避免以下不必要的bug
Exception in thread "main" org.openqa.selenium.WebDriverException: unknown error: call function result missing 'value'
(Session info: chrome=65.0.3325.31)
(Driver info: chromedriver=2.33.506120 (e3e53437346286c0bc2d2dc9aa4915ba81d9023f),platform=Windows NT 6.1.7601 SP1 x86)
(WARNING: The server did not provide any stacktrace information)
Command duration or timeout: 0 milliseconds
2019年兼容版本对照表
| 谷歌浏览器 | chromedriver版本 |
|---|---|
| ChromeDriver 79.0.3945.36 (2019-11-18) | Supports Chrome version 79 |
| ChromeDriver 78.0.3904.11 (2019-09-12) | Supports Chrome version 78 |
| ChromeDriver 77.0.3865.40 (2019-08-20) | Supports Chrome version 77 |
| ChromeDriver 76.0.3809.12 (2019-06-07) | Supports Chrome version 76 |
| ChromeDriver 75.0.3770.8 (2019-04-29) | Supports Chrome version 75 |
| ChromeDriver v74.0.3729.6 (2019-03-14) | Supports Chrome v74 |
| ChromeDriver v2.46 (2019-02-01) | Supports Chrome v71-73 |
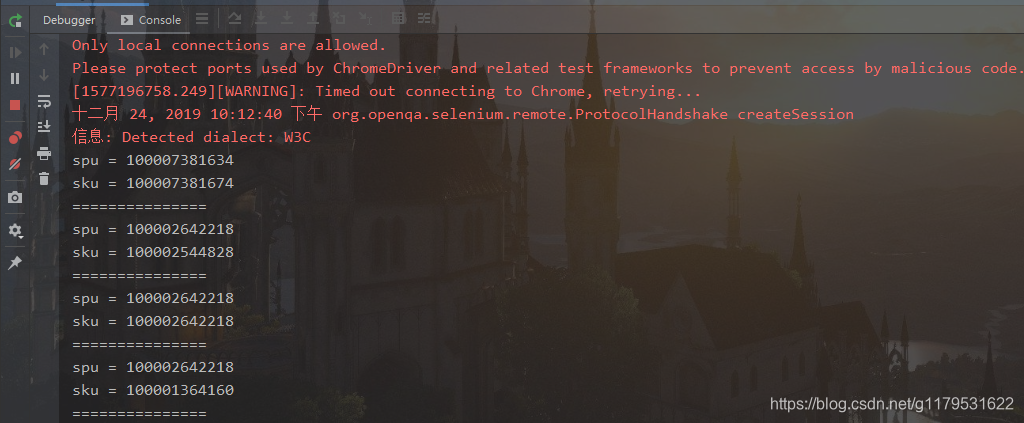
做好准备工作后编写代码,获取京东手机商品数据的spu和sku
/**
* selenium 解决数据异步加载问题
* https://npm.taobao.org/mirrors/chromedriver/
*
* @param url https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf- 8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&s=361&click=0&page=1
*/
private static void selenium(String url) {
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,这样就不会弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取京东手机信息
List<WebElement> elements = webDriver.findElements(By.cssSelector("div#J_goodsList > ul > li"));
elements.forEach(spuElement -> {
String spu = spuElement.getAttribute("data-spu");
System.out.println("spu = "+spu);
// 获取sku
List<WebElement> skuElements = spuElement.findElements(By.cssSelector("li.ps-item"));
skuElements.forEach(webElement -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement img = webElement.findElement(By.cssSelector("img[data-sku]"));
String sku = img.getAttribute("data-sku");
System.out.println("sku = "+sku);
System.out.println("===============");
});
});
webDriver.close();
}
需注意:selenium 方式获取html数据,会受到网络波动或电脑配置的影响。当动态加载页面时,可能还存在部分数据没有加载完毕,为它设置休眠时间后,可保证有足够的时间,加载完 Thread.sleep(2000);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









