







tags: python,机器学习,决策树,随机森林,numpy
决策树
定义
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。
使用
首先需要从sklearn.tree中导入,
做分类时代码:from sklearn.tree import DecisionTreeClassifier
做回归时代码:from sklearn.tree import DecisionTreeRegressor
预剪枝
决策树很容易过拟合,使用的时候一定要进行剪枝
其中的参数max_depth控制树的最大深度。如果使用默认值None,则会一致进行分类,直到所有的类别都被分好或者达到min_samples_split指定的值。
所以如果知道树的最大深度是多少,可以直接对参数max_depth值进行设置
如果不知道树的最大深度,则可以通过控制参数min_samples_split和min_samples_leaf
参数min_samples_split:如果树某个节点内数据(也可以看作是可分隔的数数据)小于该值,则停止划分
参数min_samples_leaf:如果样本树的最小的子节点小于该值,也停止划分。
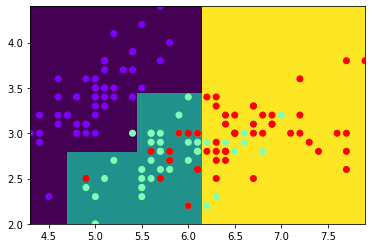
画出决策树的边界
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
iris = load_iris()
data = iris['data']
target = iris['target']
dd2 = data[:,0:2]
x, y = np.linspace(dd2[:,0].min(), dd2[:,0].max(), 1000), np.linspace(dd2[:,1].min(), dd2[:,1].max(), 1000)
X, Y = np.meshgrid(x,y)
XY = np.c_[X.reshape(-1), Y.ravel()]
# ravel和reshape(-1)是一样的
tree = DecisionTreeClassifier(max_depth=3)
tree.fit(dd2, target)
y_ = tree.predict(XY)
plt.pcolormesh(X,Y,y_.reshape(1000,1000))
plt.scatter(dd2[:,0],dd2[:,1],c=target,cmap='rainbow')
numpy中的.reshape()函数
numpy中reshape函数的三种常见相关用法
reshape(1,-1)转化成1行,reshape(-1)也有这个意思。
reshape(2,-1)转换成两行:
reshape(-1,1)转换成1列:
reshape(-1,2)转化成两列
reshape(m,-1),转化为m行x列(具体多少列,系统会自己计算)
reshape(-1,m),转化为x行m列(具体多少行,系统会自己计算)
随机森林
随机森林是决策树生成的很多树.
一颗决策树容易过拟合,用很多决策树来平衡一下.
随机森林中随机有两重含义.
- 对样本数随机, 但是所有的树取的样本个数是一样的.
- 对特征随机, 所有树取的特征数是一样.
对于分类来说, 对结果进行投票.
对于回归来说, 对结果取平均.
随机森林有一个很重要的用途,就是用来做特征选择,随机森林可以计算特征的重要性
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
iris = load_iris()
data = iris['data']
target = iris['target']
# n_estimators为随机森林中树的个数,
# 在100以内都是可以的,如果高于100,效果可能会下降
rfc = RandomForestClassifier(n_estimators=100, max_depth=2)
score = rfc.fit(data,target).score(data,target)
# 随机森林中还有一个重要用途,用来做特征选择,随机森林可以计算特征的重要性
f_i = rfc.feature_importances_
# 数字越大表示特征越重要
print(score)
print(f_i)
上面的代码使用sklearn数据库中的鸢尾花数据,打印的模型分数为0.96,特征重要性为:[1.19671505e-01, 2.53232652e-05, 3.69154276e-01, 5.11148895e-01]。
从上面的数据可以看出第二个特征重要性不好。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









