







tags: python,机器学习,线性回归,岭回归,Lasso回归,逻辑斯蒂回归,matplotlib,pandas,numpy,DataFrame
文章目录
一、线性回归概念
【关键词】最小二乘法,线性。
分类的目标变量是标称型数据,而回归将会对连续型的数据做出预测。
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。线性回归模型经常用最小二乘逼近来拟合。
二、糖尿病数据线性回归分析
2.1. 获取数据
在sklearn的数据库中,内置有糖尿病数据,可以从其中获取:
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
data = diabetes['data']
target = diabetes['target']
feature_names = diabetes['feature_names']
使用DataFrame将其中的数据展示出来:
from pandas import DataFrame
df = DataFrame(data=data, columns=feature_names)
df.head()
| age | sex | bmi | bp | s1 | s2 | s3 | s4 | s5 | s6 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.038076 | 0.050680 | 0.061696 | 0.021872 | -0.044223 | -0.034821 | -0.043401 | -0.002592 | 0.019908 | -0.017646 |
| 1 | -0.001882 | -0.044642 | -0.051474 | -0.026328 | -0.008449 | -0.019163 | 0.074412 | -0.039493 | -0.068330 | -0.092204 |
| 2 | 0.085299 | 0.050680 | 0.044451 | -0.005671 | -0.045599 | -0.034194 | -0.032356 | -0.002592 | 0.002864 | -0.025930 |
| 3 | -0.089063 | -0.044642 | -0.011595 | -0.036656 | 0.012191 | 0.024991 | -0.036038 | 0.034309 | 0.022692 | -0.009362 |
| 4 | 0.005383 | -0.044642 | -0.036385 | 0.021872 | 0.003935 | 0.015596 | 0.008142 | -0.002592 | -0.031991 | -0.046641 |
由于无法自己生成测试数据,所以需要对原始数据进行切割,使用下面的代码进行处理:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=42)
其中原始数据data的形状为(442, 10),所以上面获取的测试代码可以设置为42。
2.2. 模型训练,并进行可视化
from sklearn.linear_model import LinearRegression
linear = LinearRegression()
linear.fit(X_train, y_train)
# 研究单个特征对结果的影响
# 单独取出每个特征来研究对结果的影响
# 5行2列
plt.figure(figsize=(2*6,5*5))
for i, col in enumerate(df.columns):
X_train = df[[col]]
linear = LinearRegression()
score = linear.fit(X_train,target).score(X_train,target)
plt.subplot(5,2,i+1,title='{}:{}'.format(col,score))
plt.scatter(X_train,target)
x = np.linspace(X_train.min(), X_train.max(), 100)
y = linear.coef_ * x + linear.intercept_
plt.plot(x,y,c='r')
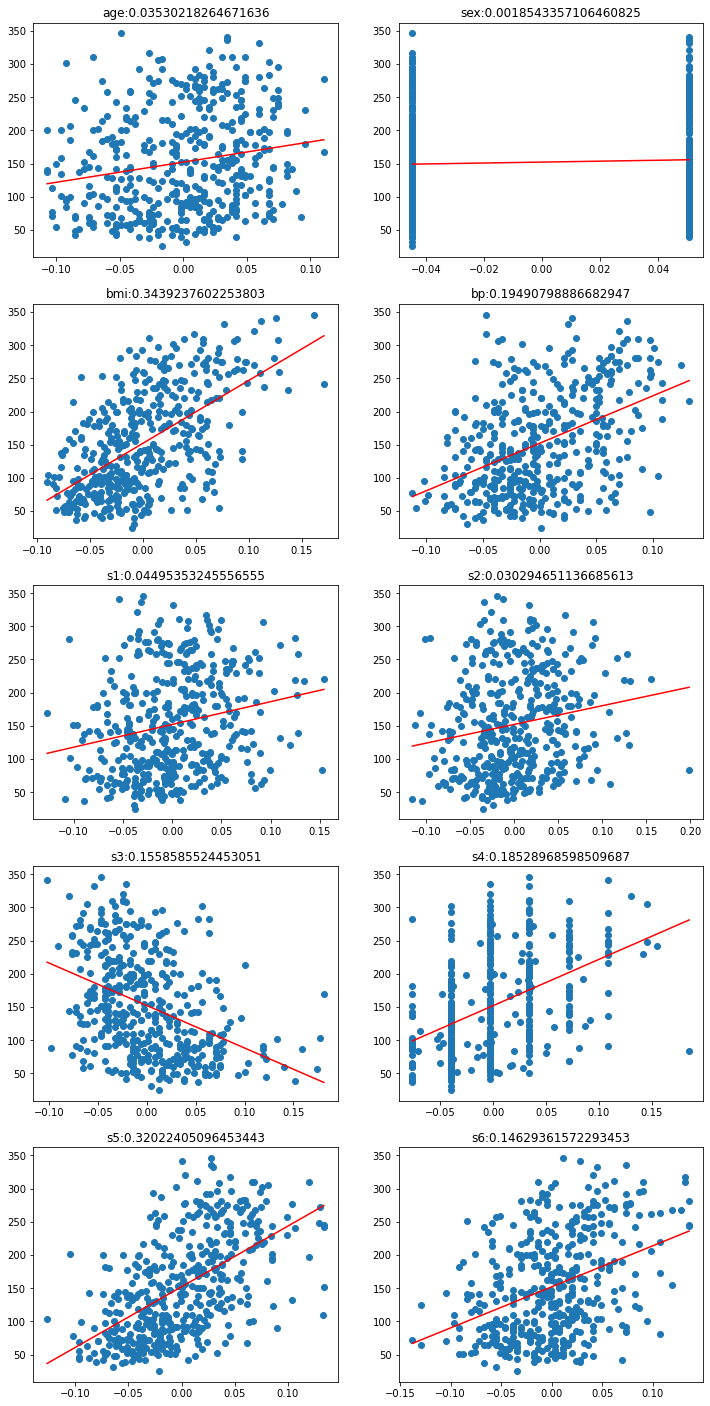
从上面的图片中可以看到所有特征与原数据中的target值之间的线性关系。,并可以看出有些特征对是否得糖尿病不相关。
三、岭回归
3.1. 岭回归概念
岭回归(ridge regression)一般用于处理特征数大于样本点数的情况,此时岭回归会将其中一些不重要的特征给消除掉,筛选出有用的特征。
对于这种情况,不能使用线性回归进行处理,这是因为输入数据的矩阵X不是满秩矩阵。非满秩矩阵在求逆时会出现问题。
如下面的代码
# 50个样本,200个特征
# 想当于有50个方程,200个未知数,求不出方程的唯一解
X = np.random.randn(50,200)
y = np.random.randn(50)
linear = LinearRegression()
linear.fit(X, y)
# 在线性回归中,如果得分过高,比如接近1,则证明不能拟和当前数据
linear.score(X, y)
上面的代码求出的线性回归得分为1.0,这说明线性回归不能进行拟合。
- 岭回归可以解决特征数量比样本量多的问题
- 岭回归作为一种缩减算法可以判断哪些特征重要或者不重要,有点类似于降维的效果
- 缩减算法可以看作是对一个模型增加偏差的同时减少方差
在线性回归中,如果得分过高,比如接近1,则证明不能拟和当前数据。
3.2. 岭回归系数研究
from sklearn.linear_model import Ridge
X = 1/(np.arange(1,11) + np.arange(10).reshape(10,1))
y = np.arange(1,11)
alphas = np.logspace(-2,-10,300)
ridge = Ridge()
coefs = []
for alpha in alphas:
ridge.set_params(alpha=alpha)
ridge.fit(X,y)
coef = ridge.coef_
coefs.append(coef)
plt.figure(figsize=(10,8))
_ = plt.plot(alphas, coefs)
plt.xlim(xmin=alphas[0],xmax=alphas[-1])
plt.xscale('log')
plt.xlabel('alphas')
plt.ylabel('coefs')
plt.title("relationship of alpha and coefs")
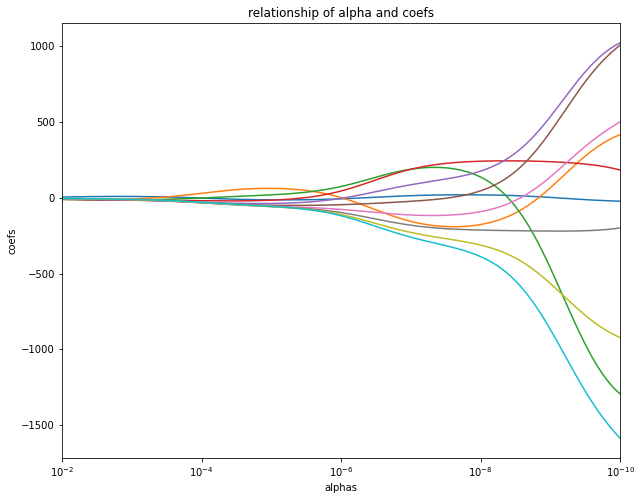
从上面的图片可以看出,岭回归中的系数alpha设置不合理时,可能会导致整个模型不稳定,或者没效果,所以一般建议选在0.01-0.0001左右
岭回归建立模型时,一定要先给定系数
alpha,因为系统默认的值为1,一般不适合模型的训练。
四、Lasso回归
与岭回归类似,它也是通过增加惩罚函数来判断、消除特征间的共线性。当λ足够小时,一些影响较弱的系数会因此被迫缩减到0。该算法是一种新算法,比岭回归稍微优秀一些。
使用时需要从模块中导入,代码:from sklearn.linear_model import Lasso
五、普通线性回归、岭回归与lasso回归比较
只要数据线性相关,用LinearRegression拟合的不是很好,需要正则化,可以考虑使用岭回归(Ridge), 如果输入特征的维度很高,而且是稀疏线性关系的话, 岭回归就不太合适,考虑使用Lasso回归。
from sklearn.linear_model import Lasso, LinearRegression, Ridge
np.random.seed(1)
X = np.random.randn(50,200)
coef = np.random.randn(200)
index = np.arange(0,200)
np.random.shuffle(index)
coef[index[0:190]] = 0
y = np.dot(X, coef)
modules = {
'linear': LinearRegression(),
'ridge': Ridge(alpha=0.01),
'lasso': Lasso(alpha=0.01)
}
plt.figure(figsize=(2*6,2*5))
plt.subplot(2,2,1)
plt.plot(coef)
plt.title('Origin')
i = 2
for key, val in modules.items():
val.fit(X,y)
score = val.score(X,y)
plt.subplot(2,2,i)
plt.plot(val.coef_)
plt.title(f'{key}(score:{score:.4f})')
i += 1
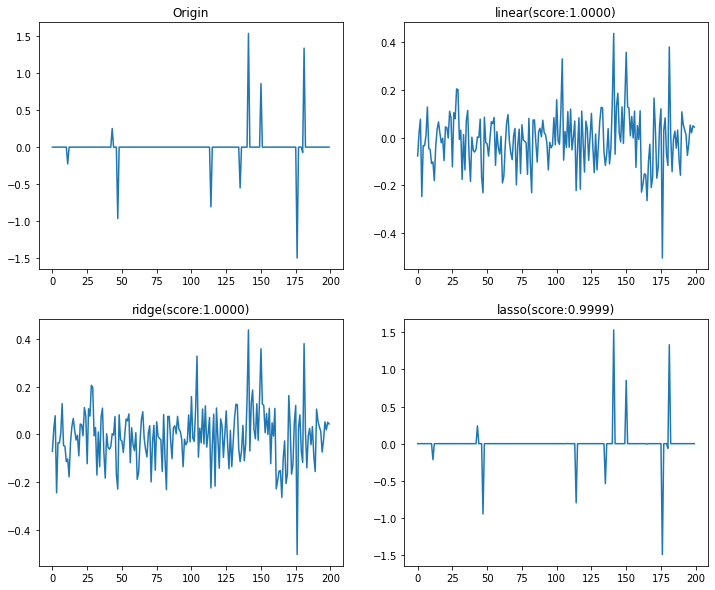
- 线性回归:适用于特征和样本之间存在线性或类线性关系的情况,且样本数要大于特征数。
- 岭回归:L2正则项,适用与样本数小于特征数的情况,但是其不会将样本系数缩减为0。如果线性回归出现过拟合时,可以使用岭回归进行优化。另外即使没有出现过拟合,也可以尝试使用岭回归,因为其加入了偏差,可以得到更好的结果,即岭回归也是数据处理的一种方式。
- Lasso回归:L1正则项,特别适用于样本数小于特征数、且解为稀松矩阵的情况。但是解是否为稀松矩阵并不能在提前知道,但遇到特征很多时,可以使用Lasso试试。另外其会将样本系数缩减为0。
六、逻辑斯蒂回归
6.1. 介绍
利用Logistics回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。Logistic Regression虽然名字里带“回归”,但是它实际上是一种分类方法。
sklearn.linear_model.LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
上面的函数主要需要对solver参数进行修改。solver参数的选择:
- “liblinear”:小数量级的数据集
- “lbfgs”, “sag” or “newton-cg”:大数量级的数据集以及多分类问题
- “sag”:极大的数据集
逻辑斯蒂回归适合处理样本点分类较为明显的情况,如果样本点类别之间有覆盖情况,该算法很容易出现过拟合。
6.2. 使用逻辑斯蒂回归对点进行分类
首先需要用sklearn.datasets中的make_blobs函数生成要分类的数据。
make_blobs(
# 生成的数据个数
n_samples=100,
# 生成的数据有几个特征值,即数据的列数
n_features=2,
# 每类数据的中心点位置
centers=None,
# 数据的标准差
cluster_std=1.0,
center_box=(-10.0, 10.0),
shuffle=True,
random_state=None,
)
具体代码:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_blobs
# make_blobs帮助我们快速生成随机的样本点
data, target = make_blobs(random_state=1)
logistic = LogisticRegression(solver='liblinear')
logistic.fit(data, target)
x, y = np.linspace(data[:,0].min(), data[:,0].max(), 1000), np.linspace(data[:,1].min(), data[:,1].max(), 1000)
X, Y = np.meshgrid(x,y)
XY = np.c_[X.ravel(), Y.ravel()]
y_ = logistic.predict(XY)
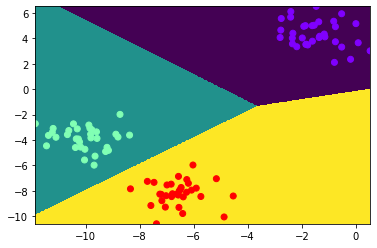
plt.pcolormesh(X, Y , y_.reshape(1000,1000))
plt.scatter(data[:,0], data[:,1], c=target, cmap='rainbow')

















 2342
2342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









