




业务目的
全量离线运算统计,结果写入oracle
依赖版本
spark 2.0.1
hive 1.1.0
问题
- 执行时task数量过多
- hive动态分区小文件过多
- 测试环境5运算节点,内存分别为12G,运行30万测试数据不断发生内存溢出问题
逐步调优
1、执行时task数量过多,总数达到了108000个,OMG,每个任务都是内存溢出,因为是用sparksql读hive表,所以spark的spark.default.parallelism强制指定task数并没有用,考虑–conf spark.sql.shuffle.partitions=30,在查询hive on hbase外部表时有效,但遇到hive分区表无效,此外考虑通过spark中repartition来处理,但是sparksql原始查询还是会根据hive分区表的情况开启task,问题定位到hive分区表。
2、目前是将数据动态分区,执行insert overwrite,产生了大量小文件
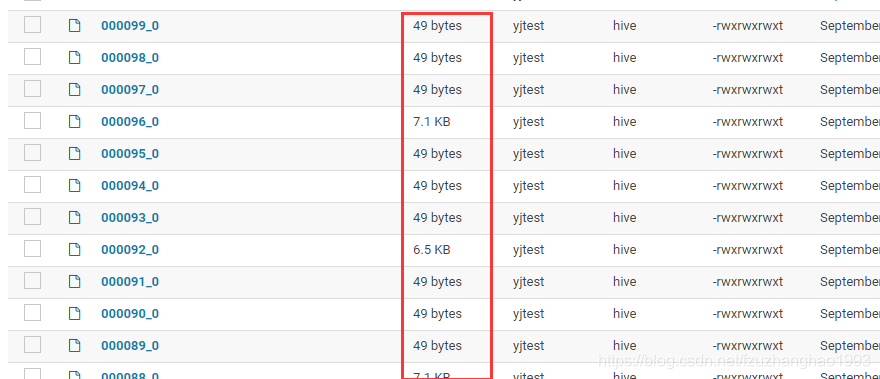
如图可以看到小文件数量达到100个,而且大小都不到10K,这样一方面对于namenode来说维护成本过高,另一方面在对hive分区表全量数据进行运算清洗时,消耗巨大,导致task数极其不合理。
处理方式:
set mapred.max.split.size=256000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set mapred.reduce.tasks=20;
set  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5528
5528




 到【灌水乐园】发言
到【灌水乐园】发言







