







 本文深入探讨了支持向量机(SVM)的核心概念,包括间隔、支持向量、对偶问题、核函数、软间隔及正则化。通过数学推导,详细解释了如何寻找最优分类超平面,并介绍了SVM在回归任务中的应用。此外,文章还涵盖了核方法在优化问题中的作用。
本文深入探讨了支持向量机(SVM)的核心概念,包括间隔、支持向量、对偶问题、核函数、软间隔及正则化。通过数学推导,详细解释了如何寻找最优分类超平面,并介绍了SVM在回归任务中的应用。此外,文章还涵盖了核方法在优化问题中的作用。
间隔与支持向量
给定数据集D={
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
m
,
y
m
)
\mathop (x_1,y_1),(x_2,y_2),...,(x_m,y_m)
(x1,y1),(x2,y2),...,(xm,ym)},
y
i
∈
[
−
1
,
+
1
]
\mathop y_i\in{[-1,+1]}
yi∈[−1,+1]训练的基本思想就是基于训练集D在样本空间找到一个划分超平面。
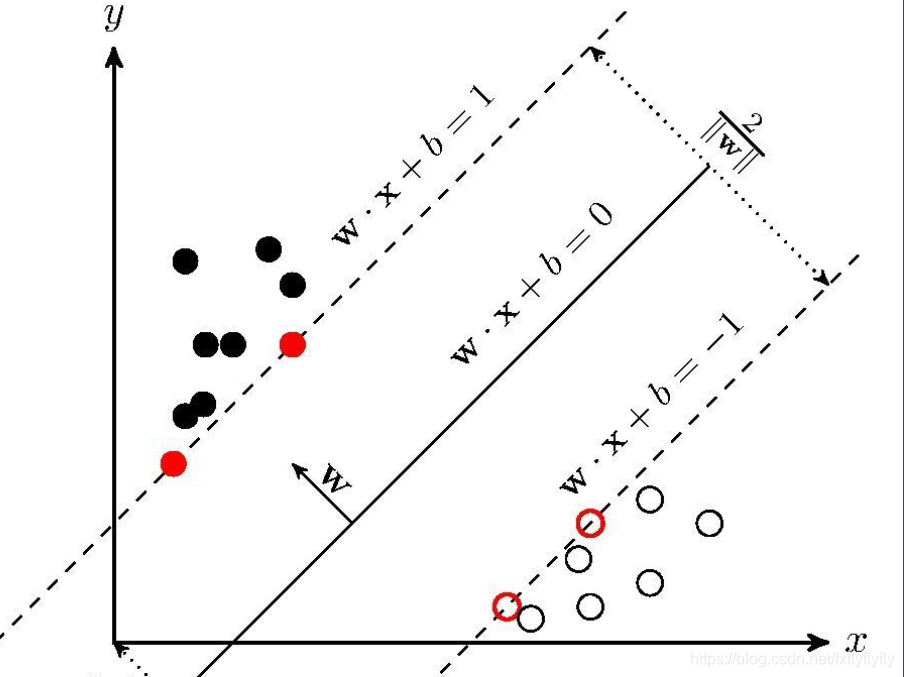 在样本空间中,划分超平面可通过如下线性方程来描述
在样本空间中,划分超平面可通过如下线性方程来描述
W
T
x
+
b
=
0
W^Tx+b = 0
WTx+b=0
其中
w
=
(
w
1
,
w
2
,
.
.
.
,
w
d
)
\mathop w = (w_1,w_2,...,w_d)
w=(w1,w2,...,wd)为法向量,决定超平面的方向,b为位移量,决定超平面与原点治安的距离,记为(w,b)
样本空间中任意点x到超平面(w,b)的距离为:
r
=
∣
W
T
x
+
b
∣
∣
∣
w
∣
∣
r = \frac{|W^Tx+b|}{||w||}
r=∣∣w∣∣∣WTx+b∣
若将w,b等比例增大,例如2w,2b,超平面未改变,但函数间隔缺改变了,所以除以||w||。
若超平面划分正确,则有:
{
w
T
x
i
+
b
>
0
,
y
i
=
+
1
w
T
x
i
+
b
<
0
,
y
i
=
−
1
\begin{cases} w^Tx_i+b>0, & y_i =+1 \\ w^Tx_i+b<0, & y_i =-1 \end{cases}
{wTxi+b>0,wTxi+b<0,yi=+1yi=−1
令:
{
w
T
x
i
+
b
≥
1
,
y
i
=
+
1
w
T
x
i
+
b
≤
−
1
,
y
i
=
−
1
\begin{cases} w^Tx_i+b \geq 1, & y_i =+1 \\ w^Tx_i+b \leq -1, & y_i =-1 \end{cases}
{wTxi+b≥1,wTxi+b≤−1,yi=+1yi=−1
若训练样本使
w
T
x
i
+
b
=
±
1
\mathop w^Tx_i +b=\pm1
wTxi+b=±1,则被称为支持向量,两个异类支持向量到超平面的距离之和成为间隔。
r
=
2
∣
∣
w
∣
∣
r = \frac{2}{||w||}
r=∣∣w∣∣2
欲找到最大化间隔的划分超平面,即使r最大
m
a
x
w
,
b
2
∣
∣
w
∣
∣
s
.
t
.
y
i
(
w
T
x
i
+
b
≥
1
)
max_{w,b}\frac{2}{||w||}_{s.t. y_i(w_Tx_i+b\geq 1)}
maxw,b∣∣w∣∣2s.t.yi(wTxi+b≥1)
即:
m
i
n
w
,
b
0.5
∣
∣
w
∣
∣
s
.
t
.
y
i
(
w
T
x
i
+
b
≥
1
)
2
min_{w,b}0.5||w||^2_{s.t. y_i(w_Tx_i+b\geq 1)}
minw,b0.5∣∣w∣∣s.t.yi(wTxi+b≥1)2
对偶问题
根据
m
i
n
w
,
b
0.5
∣
∣
w
∣
∣
s
.
t
.
y
i
(
w
T
x
i
+
b
≥
1
)
2
\mathop min_{w,b}0.5||w||^2_{s.t. y_i(w_Tx_i+b\geq 1)}
minw,b0.5∣∣w∣∣s.t.yi(wTxi+b≥1)2
f
(
x
)
=
w
T
x
+
b
\mathop f(x) = w^Tx+b
f(x)=wTx+b 求解得到最大间隔划分超平面
使用拉格朗日乘子法
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
+
∑
i
=
1
m
α
i
(
1
−
y
i
(
w
T
+
b
)
)
L(w,b,\alpha) = \frac{1}{2}||w||^2 + \sum_{i=1}^m \alpha_i(1-y_i(w^T+b))
L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wT+b))
如此,问题就变成了:
m
a
x
α
m
i
n
w
,
b
L
(
w
,
b
,
α
)
max_{\alpha} min_{w,b} L(w,b,\alpha)
maxαminw,bL(w,b,α)
对L(w,b,α)的w,b求偏导并等于0.
σ
L
σ
w
=
w
−
∑
i
=
1
m
α
i
y
i
x
i
=
0
\frac{\sigma L}{\sigma w} = w-\sum_{i=1}^m \alpha_iy_ix_i=0
σwσL=w−i=1∑mαiyixi=0
σ L σ b = ∑ i = 1 m α i g i = 0 \frac{\sigma L}{\sigma b} = \sum_{i=1}^m \alpha_ig_i = 0 σbσL=i=1∑mαigi=0
代入原式中
L
(
w
,
b
,
α
)
=
1
2
(
∑
i
=
1
m
α
i
y
i
x
i
)
2
−
∑
i
=
1
m
α
i
(
1
−
y
i
(
∑
i
=
1
m
α
i
y
i
x
i
∗
x
+
b
)
)
=
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
x
i
x
j
L(w,b,\alpha) = \frac{1}{2}(\sum_{i=1}^m \alpha_iy_ix_i)^2 - \sum_{i=1}^m \alpha_i(1-y_i(\sum_{i=1}^m\alpha_iy_ix_i * x+b)) =\sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m \sum_{j=1}^m \alpha_i\alpha_jy_iy_jx_ix_j
L(w,b,α)=21(i=1∑mαiyixi)2−i=1∑mαi(1−yi(i=1∑mαiyixi∗x+b))=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxixj
即
m
a
x
α
L
(
w
,
b
,
α
)
s
.
t
.
{
∑
i
=
1
m
α
i
y
i
=
0
α
≥
0
max_\alpha L(w,b,\alpha)_{s.t. \begin{cases}\sum_{i=1}^m \alpha_iy_i=0 \\ \alpha \geq 0 \end{cases}}
maxαL(w,b,α)s.t.{∑i=1mαiyi=0α≥0
m a x α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i x j s . t . { α ≥ 0 ∑ i = 1 m α i y i = 0 {max_\alpha \sum_{i=1}^m\alpha_i - \frac{1}{2}\sum_{i=1}^m \sum_{j=1}^m \alpha_i\alpha_jy_iy_jx_ix_j }_{s.t. \begin{cases} \alpha \geq 0 \\ \sum_{i=1}^m \alpha_iy_i=0 \end{cases}} maxαi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxixjs.t.{α≥0∑i=1mαiyi=0
求解
f
(
x
)
=
w
T
x
+
b
=
∑
i
=
1
m
α
i
y
i
x
i
T
x
i
+
b
f(x) = w^Tx +b = \sum_{i=1}^m \alpha_iy_ix_i^Tx_i +b
f(x)=wTx+b=i=1∑mαiyixiTxi+b
核函数
在原始样本空间内也许不存在一个能正确划分两类样本的超平面,这是,我们可以将样本从原始空间映射到一个更高维的特征空间。
令
Φ
(
x
)
\mathop \Phi(x)
Φ(x)表示将x映射后的特征向量,则超平面为:
f
(
x
)
=
w
T
Φ
(
x
)
+
b
f(x)=w^T\Phi(x) +b
f(x)=wTΦ(x)+b
对应有
m
a
x
α
∑
i
=
1
m
α
i
−
1
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
j
(
Φ
(
x
i
)
∗
Φ
(
x
j
)
)
s
.
t
.
{
α
≥
0
∑
i
=
1
m
α
i
y
i
=
0
{max_\alpha \sum_{i=1}^m\alpha_i - \frac{1}{2}\sum_{i=1}^m \sum_{j=1}^m \alpha_i\alpha_jy_iy_j(\Phi(x_i)*\Phi(x_j))}_{s.t. \begin{cases} \alpha \geq 0 \\ \sum_{i=1}^m \alpha_iy_i=0 \end{cases}}
maxαi=1∑mαi−21i=1∑mj=1∑mαiαjyiyj(Φ(xi)∗Φ(xj))s.t.{α≥0∑i=1mαiyi=0
因为
Φ
(
x
i
)
∗
Φ
(
x
j
)
\mathop \Phi(x_i)*\Phi(x_j)
Φ(xi)∗Φ(xj)难以计算,所以设想一个函数k
K
(
x
i
,
x
j
)
=
<
Φ
(
x
i
)
,
Φ
(
x
j
)
>
=
Φ
(
x
i
)
∗
Φ
(
x
j
)
K(x_i,x_j) = <\Phi(x_i),\Phi(x_j)> = \Phi(x_i)*\Phi(x_j)
K(xi,xj)=<Φ(xi),Φ(xj)>=Φ(xi)∗Φ(xj)
我们称K<·,·>为核函数
令x为输入空间,K<·,·>是定义在xxx上的对称函数,当且仅当对于任意数据
D
=
[
X
1
,
X
2
,
.
.
,
x
m
]
\mathop D=[X_1,X_2,..,x_m]
D=[X1,X2,..,xm],核矩阵k总是半正定的,k使核函数。
K
=
[
k
(
x
1
,
x
1
)
.
.
.
k
(
x
1
,
x
j
)
.
.
.
k
(
x
1
,
x
m
)
.
.
.
.
.
.
.
.
.
.
.
.
k
(
x
i
,
x
1
)
.
.
.
k
(
x
i
,
x
j
)
.
.
.
k
(
x
i
,
x
m
)
.
.
.
.
.
.
.
.
.
.
.
.
k
(
x
m
,
x
1
)
.
.
.
k
(
x
m
,
x
j
)
.
.
.
k
(
x
m
,
x
m
)
]
K = \begin{bmatrix} k(x_1,x_1) & ... & k(x_1,x_j) & ... &k(x_1,x_m) \\..& ...&..&...&.. \\ k(x_i,x_1) &...&k(x_i,x_j)&...& k(x_i,x_m) \\..& ...&..&...&.. \\ k(x_m,x_1)&...&k(x_m,x_j)&...&k(x_m,x_m) \end{bmatrix}
K=⎣⎢⎢⎢⎢⎡k(x1,x1)..k(xi,x1)..k(xm,x1)...............k(x1,xj)..k(xi,xj)..k(xm,xj)...............k(x1,xm)..k(xi,xm)..k(xm,xm)⎦⎥⎥⎥⎥⎤
常用核函数
k
(
x
i
,
y
i
)
=
x
i
y
i
k(x_i,y_i)=x_iy_i
k(xi,yi)=xiyi
k ( x i , y i ) = ( x i y i ) d k(x_i,y_i)=(x_iy_i)^d k(xi,yi)=(xiyi)d
k ( x i , y i ) = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 2 σ 2 ) k(x_i,y_i)=exp(-\frac{||x_i-x_j||^2}{2\sigma^2}) k(xi,yi)=exp(−2σ2∣∣xi−xj∣∣2)
. . . . . . . . ........ ........
软间隔和正则化
软间隔是允许某些样本不满足条件
y
i
(
w
T
x
i
+
b
)
≥
1
y_i(w^Tx_i + b) \geq 1
yi(wTxi+b)≥1
于是优化目标可以写成
m
i
n
w
,
b
1
2
∣
∣
w
∣
∣
2
+
c
∑
i
=
1
m
τ
0
/
1
(
y
i
(
w
T
x
i
+
b
)
−
1
)
min_{w,b} \frac{1}{2}||w||^2 + c \sum_{i=1}^m\tau_{0/1}(y_i(w^Tx_i+b)-1)
minw,b21∣∣w∣∣2+ci=1∑mτ0/1(yi(wTxi+b)−1)
其中C是大于0的常熟,
τ
0
/
1
\mathop \tau_{0/1}
τ0/1是0/1的损失函数
{
1
,
if z<0
0
,
otherwise
\begin{cases}1 , &&\text{if z<0} \\ 0,&& \text{otherwise}\end{cases}
{1,0,if z<0otherwise
当C为无穷大时,则等价为硬间隔,
τ
0
/
1
\mathop \tau_{0/1}
τ0/1的数学性质不好,所以使用代替函数,常见有:
hinge损失:
ι
h
i
n
g
e
(
z
)
=
m
a
x
(
0
,
1
−
z
)
\mathop \iota_{hinge}(z) = max(0,1-z)
ιhinge(z)=max(0,1−z)
指数损失:
ι
e
x
p
(
z
)
=
e
x
p
(
−
z
)
\mathop \iota_{exp}(z) = exp(-z)
ιexp(z)=exp(−z)
对率损失:
ι
l
o
g
(
z
)
=
l
o
g
(
1
+
e
x
p
(
−
z
)
)
\mathop \iota_{log}(z) = log(1+exp(-z))
ιlog(z)=log(1+exp(−z))
使用hinge损失,可将原始改为:
m
i
n
w
,
b
1
2
∣
∣
w
∣
∣
2
+
c
∑
i
=
1
m
m
a
x
(
0
,
1
−
y
i
(
w
T
x
i
+
b
)
)
min_{w,b} \frac{1}{2}||w||^2 + c \sum_{i=1}^mmax(0,1-y_i(w^Tx_i+b))
minw,b21∣∣w∣∣2+ci=1∑mmax(0,1−yi(wTxi+b))
引入松弛变量
ξ
i
≥
0
\mathop \xi_i\geq0
ξi≥0
m
i
n
w
,
b
,
ξ
1
/
2
∣
∣
w
∣
∣
2
+
c
∑
i
=
1
m
ξ
i
min_{w,b,\xi} 1/2||w||^2 + c\sum_{i=1}^m\xi_i
minw,b,ξ1/2∣∣w∣∣2+ci=1∑mξi
s . t . y i ( w T x i + b ) ≥ 1 − ξ i s.t. y_i(w^Tx_i+b)\geq 1-\xi_i s.t.yi(wTxi+b)≥1−ξi
ξ i ≥ 0 \xi_i\geq0 ξi≥0
拉格朗日乘子法
L
(
w
,
b
,
α
,
ξ
,
μ
)
=
1
/
2
∣
∣
w
∣
∣
2
+
c
∑
i
=
1
m
ξ
i
+
∑
i
=
1
m
α
i
(
1
−
ξ
i
−
y
i
(
w
T
x
i
+
b
)
)
−
∑
i
=
1
m
μ
i
ξ
i
L(w,b,\alpha,\xi,\mu) = 1/2 ||w||^2+c\sum_{i=1}^m\xi_i+\sum_{i=1}^m\alpha_i(1-\xi_i-y_i(w^Tx_i+b))-\sum_{i=1}^m\mu_i\xi_i
L(w,b,α,ξ,μ)=1/2∣∣w∣∣2+ci=1∑mξi+i=1∑mαi(1−ξi−yi(wTxi+b))−i=1∑mμiξi
对
w
,
b
,
ξ
\mathop w,b,\xi
w,b,ξ求偏导。
w
=
∑
i
=
1
m
α
i
y
i
x
i
w = \sum_{i=1}^m\alpha_iy_ix_i
w=i=1∑mαiyixi
0 = ∑ i = 1 m α i y i 0 = \sum_{i=1}^m\alpha_iy_i 0=i=1∑mαiyi
c = α i + μ i c=\alpha_i+\mu_i c=αi+μi
代入:
m
a
x
α
i
∑
i
=
1
m
α
i
−
1
/
2
∑
i
=
1
m
∑
j
=
1
m
α
i
α
j
y
i
y
i
x
i
x
j
max_{\alpha_i} \sum_{i=1}^m\alpha_i - 1/2\sum_{i=1}^m\sum_{j=1}^m\alpha_i\alpha_jy_iy_ix_ix_j
maxαii=1∑mαi−1/2i=1∑mj=1∑mαiαjyiyixixj
s . t . ∑ i = 1 m α i y i = 0 s.t. \sum_{i=1}^m\alpha_iy_i=0 s.t.i=1∑mαiyi=0
0 ≤ α i ≤ c 0\leq\alpha_i\leq c 0≤αi≤c
支持向量机回归
支持向量机回归能容忍
f
(
x
)
与
y
\mathop f(x) 与 y
f(x)与y之间有
ξ
\mathop \xi
ξ的偏差,这就相当于以
f
(
x
)
\mathop f(x)
f(x)为中心,构建了一个宽度为
2
ξ
\mathop2\xi
2ξ的间隔带,只有训练样本落入间隔带,则认为是正确预测。
m
i
n
w
,
b
1
/
2
∣
∣
w
∣
∣
2
+
c
∑
i
=
1
m
ζ
e
(
f
(
x
i
)
−
y
i
)
min_{w,b}1/2||w||^2 + c\sum_{i=1}^m\zeta_e(f(x_i)-y_i)
minw,b1/2∣∣w∣∣2+ci=1∑mζe(f(xi)−yi)
其中c为正则化常数,
ζ
e
(
z
)
=
{
0
,
i
f
∣
z
∣
≤
ϵ
∣
z
∣
−
ϵ
,
o
t
h
e
r
w
i
s
e
\zeta_e(z)=\begin{cases} 0 , & if |z|\leq \epsilon \\ |z|-\epsilon , & otherwise\end{cases}
ζe(z)={0,∣z∣−ϵ,if∣z∣≤ϵotherwise
引入松弛变量,可改写为:
m
i
n
w
,
b
,
ξ
i
,
ξ
^
i
1
/
2
∣
∣
w
∣
∣
2
+
c
∑
i
=
1
m
(
ξ
i
+
ξ
^
i
)
min_{w,b,\xi_i,\hat\xi_i} 1/2||w||^2 + c\sum_{i=1}^m(\xi_i+\hat\xi_i)
minw,b,ξi,ξ^i1/2∣∣w∣∣2+ci=1∑m(ξi+ξ^i)
s . t . f ( x i ) − y i ≤ ϵ i + ξ i s.t. f(x_i)-y_i \leq\epsilon_i+\xi_i s.t.f(xi)−yi≤ϵi+ξi
y i − f ( x i ) ≤ ϵ i + ξ ^ i y_i-f(x_i)\leq\epsilon_i+\hat\xi_i yi−f(xi)≤ϵi+ξ^i
ξ
i
≥
0
,
ξ
^
i
≥
0
\xi_i\geq0 ,\hat\xi_i\geq0
ξi≥0,ξ^i≥0
引入拉格朗日乘子
L
(
w
,
b
,
α
,
α
^
,
ξ
,
ξ
^
,
μ
,
μ
^
)
=
1
/
2
∣
∣
w
∣
∣
2
+
c
∑
i
=
1
m
(
ξ
+
ξ
^
)
−
∑
i
=
1
m
μ
i
ξ
i
−
∑
i
=
1
m
μ
^
i
ξ
^
i
+
∑
i
=
1
m
α
i
(
f
(
x
i
)
−
y
i
−
ϵ
−
ϵ
i
)
+
∑
i
=
1
m
α
^
i
(
y
i
−
f
(
s
i
)
−
ϵ
−
ξ
^
i
)
L(w,b,\alpha,\hat\alpha,\xi,\hat\xi,\mu,\hat\mu) = 1/2||w||^2+c\sum_{i=1}^m(\xi+\hat\xi)-\sum_{i=1}^m\mu_i\xi_i-\sum_{i=1}^m\hat\mu_i\hat\xi_i+\sum_{i=1}^m\alpha_i(f(x_i)-y_i-\epsilon-\epsilon_i)+\sum_{i=1}^m\hat\alpha_i(y_i-f(s_i)-\epsilon-\hat\xi_i)
L(w,b,α,α^,ξ,ξ^,μ,μ^)=1/2∣∣w∣∣2+ci=1∑m(ξ+ξ^)−i=1∑mμiξi−i=1∑mμ^iξ^i+i=1∑mαi(f(xi)−yi−ϵ−ϵi)+i=1∑mα^i(yi−f(si)−ϵ−ξ^i)
对
w
,
b
,
ξ
i
,
ξ
^
i
\mathop w,b,\xi_i,\hat\xi_i
w,b,ξi,ξ^i求偏导为零
w
=
∑
i
=
1
m
(
α
^
i
−
α
i
)
x
i
w=\sum_{i=1}^m(\hat\alpha_i-\alpha_i)x_i
w=i=1∑m(α^i−αi)xi
0 = ∑ i = 1 m ( α ^ i − α i ) 0 = \sum_{i=1}^m(\hat\alpha_i-\alpha_i) 0=i=1∑m(α^i−αi)
c = α i + μ i = α ^ i + μ ^ i c = \alpha_i +\mu_i=\hat\alpha_i+\hat\mu_i c=αi+μi=α^i+μ^i
代入上述 L ( w , b , α , α ^ , ξ , ξ ^ , μ , μ ^ ) \mathop L(w,b,\alpha,\hat\alpha,\xi,\hat\xi,\mu,\hat\mu) L(w,b,α,α^,ξ,ξ^,μ,μ^)中:
m a x α , α ^ ∑ i = 1 m ( α ^ i − α i ) − ϵ ( α ^ i + α i ) − 1 / 2 ∑ i = 1 m ∑ j = 1 m ( α ^ i − α ) ( α ^ j − α ) x i x j max_{\alpha,\hat\alpha}\sum_{i=1}^m(\hat\alpha_i-\alpha_i)-\epsilon(\hat\alpha_i+\alpha_i)-1/2\sum_{i=1}^m\sum_{j=1}^m(\hat\alpha_i-\alpha)(\hat\alpha_j-\alpha)x_ix_j maxα,α^i=1∑m(α^i−αi)−ϵ(α^i+αi)−1/2i=1∑mj=1∑m(α^i−α)(α^j−α)xixj
s . t . ∑ i = 1 m ( α ^ i − α i ) = 0 s.t. \sum_{i=1}^m(\hat\alpha_i-\alpha_i)=0 s.t.i=1∑m(α^i−αi)=0
0 ≤ ( α i , α ^ i ) ≤ c 0\leq(\alpha_i,\hat\alpha_i)\leq c 0≤(αi,α^i)≤c
核方法
定理:令H为核函数k对用的再生和希尔伯特空间,||h||H表示H空间中关于h的范数,对于任意单调递增函数
Ω
:
[
0
,
∞
]
→
R
\mathop \Omega:[0,\infty] \to R
Ω:[0,∞]→R和任意非负损失函数
ϑ
:
R
m
→
[
0
,
∞
]
\mathop \vartheta:R^m \to [0,\infty]
ϑ:Rm→[0,∞],优化问题
m
i
n
h
∈
H
F
(
h
)
=
Ω
(
∣
∣
h
∣
∣
H
)
+
ϑ
(
h
(
x
1
)
,
h
(
x
2
)
,
.
.
.
,
h
(
x
m
)
)
min_{h\in H}F(h)=\Omega(||h||_H) + \vartheta(h(x_1),h(x_2),...,h(x_m))
minh∈HF(h)=Ω(∣∣h∣∣H)+ϑ(h(x1),h(x2),...,h(xm))
的解总可以写为:
h ∗ ( x ) = ∑ i = 1 m α i k ( x , x i ) h^*(x)=\sum_{i=1}^m\alpha_ik(x,x_i) h∗(x)=i=1∑mαik(x,xi)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









