







文章目录
scrapy框架
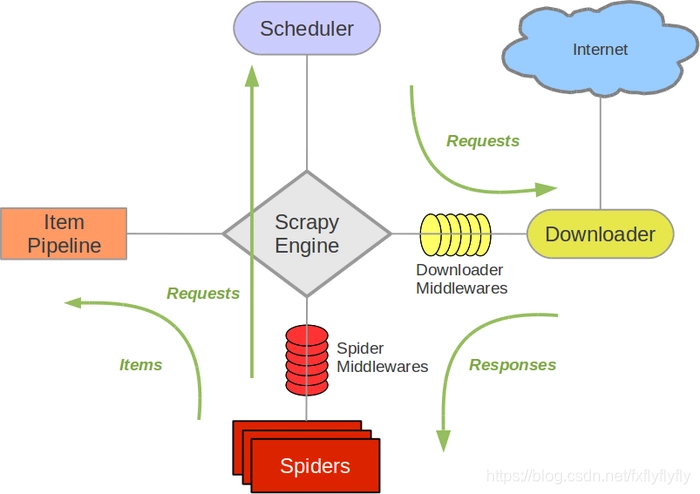
| 组件 | 描述 | 类型 |
|---|---|---|
| Scrapy Engine | 引擎,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等 | 内部组件 |
| Scheduler | 调度器:,它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 | 内部组件 |
| Downloader | 下载器:负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理 | 内部组件 |
| Spider | 爬虫:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器), | 用户实现 |
| Item Pipeline | 管道:它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方. | 可选组件 |
| Downloader Middlewares | 下载中间件:你可以当作是一个可以自定义扩展下载功能的组件,负责对resquest和response对象处理。 | 可选组件 |
| Spider Middlewares | Spider中间件:你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests ) | 可选组件 |
流程:
- 当SPIDER要爬取某URL地址的页面时,需使用该URL构造一 个Request对象,提交给ENGINE。
- Request对象随后进入SCHEDULER按某种算法进行排队,之 后的某个时刻SCHEDULER将其出队,送往DOWNLOADER。
- DOWNLOADER根据Request对象中的URL地址发送一次HTTP 请求到网站服务器,之后用服务器返回的HTTP响应构造出一个 Response对象,其中包含页面的HTML文本。
- Response对象最终会被递送给SPIDER的页面解析函数(构造 Request对象时指定)进行处理,页面解析函数从页面中提取数据,封装成Item后提交给ENGINE,Item之后被送往ITEM PIPELINES进行处理,最终可能由EXPORTER以某种数据格式写入文件(csv,json);另一方面,页面解析函数还从页面中提取链接(URL),构造出新的Request对象提交给ENGINE。
Resquest/Response对象
Resquest
Request对象用来描述一个HTTP请求,下面是其构造器方法的参数列表:
Request(url[,callback,method='GET',headers,body,cookies,meta,encoding='utf8',priority=0,dont_filter=False,errback])
| 参数 | 描述 |
|---|---|
| url(必须) | 请求页面的url地址,bytes或str类型, 如’http://www.python.org/doc’。 |
| callback | 页面解析函数,Callable类型,Request对象请求的页面下载完成后,由该参数指定的页面解析函数被调用。如果未传递该参数,默认调用Spider的parse方法 |
| method | HTTP请求的方法,默认为’GET’ |
| headers | HTTP请求的头部字典,dict类型,例如{‘Accept’: ‘text/html’,‘User-Agent’:Mozilla/5.0’}。如果其中某项的值为None,就表示不发送该项HTTP头部,例如{‘Cookie’: None},禁止发送Cookie |
| body | HTTP请求的正文,bytes或str类型 |
| cookies | Cookie信息字典,dict类型,例如{‘currency’:‘USD’, ‘country’:‘UY’}。 |
| meta | Request的元数据字典,dict类型,用于给框架中其他组件传递信息,比如中间件Item Pipeline。其他组件可以使用Request对象的meta属性访问该元数据字典(request.meta),也用于给响应处理函数传递信息,详见Response的meta属性 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









