




 本文详细解读了Java中ArrayList的工作原理,包括初始化、扩容机制、内存溢出处理等内容,并介绍了ArrayList的内部实现细节。
本文详细解读了Java中ArrayList的工作原理,包括初始化、扩容机制、内存溢出处理等内容,并介绍了ArrayList的内部实现细节。
参考:https://www.cnblogs.com/xjwhaha/p/13531285.html
https://www.cnblogs.com/javastack/p/12930217.html
第一次认真读源码,逐行阅读难免有疏漏,希望各位看官轻喷
ArrayList几乎是我们日常开发最常用的集合了,存对象实例存字符串存数字,常规的存储数据和局部变量存放都经常用到它,今天我准备读一读它的源码,如有错误欢迎指正,我将逐个阅读各个方法,涉及到的复制数组的方法没有分析,读一读源码不难理解
ArrayList的特点概述
从ArrayList本身特点出发,结论如下:
| 关注点 | ArrayList相关结论 |
| 是否允许空的元素 | 是 |
| 是否允许重复的元素 | 是 |
| 元素有序:读取数据和存放数据的顺序一致 | 是 |
| 是否线程安全 | 否 |
| 随机访问的效率 | 随机访问指定索引(即数组的索引)的元素快 |
| 顺序添加元素的效率 | 在不涉及扩容时,顺序添加元素速度快; 当需要扩容时,涉及到元素的复制,相对较慢 |
| 删除和插入元素的效率 | 因涉及到复制和移动后续的元素,相对较慢 |
我们先来看一下ArrayList具体集成和实现了什么接口/抽象类

List有各种具体的实现类,ArrayList,LinkedList,它们特性和适用场景不同但都实现List接口,这个接口定义了所有List的通用方法,如add,remove,在List接口中,统一对这些方法的返回值、参数等都进行了规定,也就是对各个实现的功能进行了抽象。那么在有了List接口作为规范之后为什么还要继承AbstractList抽象类呢?而List,AbstractList,和ArrayList定义的时候都被定义成了泛型类,得益于java的运行时绑定机制,我们可以在定义ArrayList时指定其存储的数据类型,如:ArrayList list = new ArrayList<Integer>();
这与抽象类的特性有关了,接口中只有抽象方法,而实现了接口的类必须实现接口中的所有方法,抽象类则不同,它的内部是可以存在具体的方法的,如果各个实现类有一些公共的方法,我们是不是要在每个实现类中都写上一遍?jdk设计人员当然不愿意这么做,所以他们搞了这个抽象类,AbstractList实现了List接口,对其中的方法都有具体实现,虽然ArrayList自己实现了List接口内的方法,使得AbstractList看起来有些冗余,但这种设计思想是值得借鉴的
反过来想,继承了AbstractList,但AbstractList已经实现了List,为什么ArrayList还要再去实现List接口呢?
从网上总结看来,原因有以下几点
1 基于代理使用时,class.getinterfaces()返回不同,方便基于List的代理所以这么设计
2 增加可阅读性,显示实现了List接口
3 AbstractList已经实现大部分List接口的方法,这么做可以强制ArrayList将List方法重写一遍
4 真的写错了···
然后是实现serializable接口,这个没什么可说的,实现List实例的序列化传输
Cloneable接口,支持对象属性的深度赋值和浅度复制,深度赋值指可以赋值对象,及包含在对象中的对象的所有属性,前度赋值指只赋值当前对象的属性,这里暂时不深入研究
然后是RandomAccess接口,这个可以点进去看看介绍,是个空的标识接口,这个接口内部有简介,可以点开看看,大致意思就是支持快速随机访问,具体可以参考这篇博客;简单总结就是,是否实现该接口的list实例都使用二分法遍历(二分法的思想简单说就是给一个数和一堆有序的数比大小时从这一堆的中间数开始比,然后之后再和符合条件的剩余数的中间比,这样每次排出当前剩余的数字的中的一半),但实现该接口的二分法中使用的是索引遍历,未实现的使用的是迭代器遍历,这也是为什么,ArrayList使用for循环遍历的效率高于迭代器的遍历效率。
浏览完接口,我们来看一下主要内部定义的属性
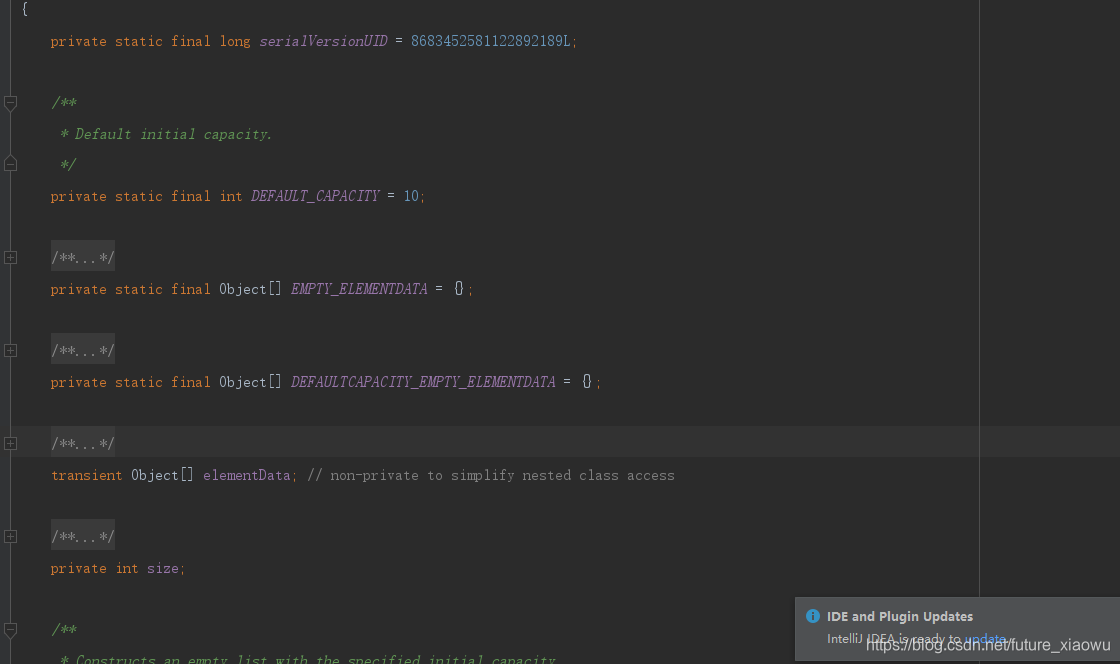
为了能放到一张图上我隐藏了简介,前三个属性都是常量,DEFAULT_CAPACITY即ArrayList的默认长度,这个长度实在扩容时去使用的,看了初始化方法以后我们可以发现其实在java8中ArrayList的初始化长度是个默认长度的数组,若你调用扩容方法,则可以根据你给的值和现在list长度来确认最佳容量。
EMPTY_ELEMENTDATA,按注释描述,是一个被共享的空数组,该空数组被用来表实ArrayList的空实例,即不包含任何元素的ArrayList实例(对象),一下将该实例简称为实例。
DEFAULTCAPACITY_EMPTY_ELEMENTDATA,也是一个空的Object数组,但是与上一个空数组不同,这是用来表示默认长度的实例的,而不是空,当第一个元素被添加至当前实例中时,我们就可以得知需要扩容的具体长度了。因为在add方法被调用后,会根据当前size + 1和默认值的比较来确认最佳容量,所以这也是为什么作者说在元素被添加至list后才知道具体容量,因为在添加元素之前,这只是一个默认长度的空数组
第三个属性elementData,不同于之前的常量,这是一个trasient修饰的Object数组,statsic修饰的静态变量不会被序列化,而transient这个修饰符也有这个效果,这意味着,将实例序列化成二进制流数据时,该属性不会被序列化,但是这个数组是实际存储数据的数组,如果序列化实例时不实例化这个数组,那么list中存的数据会不会丢失呢?这个当然不会,在源码中对这一点也会做处理,这个数组有点像是一个暂存器,只用它来存储元素,既然这个数组是用来存储元素的,那么它也一定会和自动扩容有一定的联系,后面在源码里,我们一起来看一下ArrayList的自动扩容是如何实现的。注释里还描述了,若实例中的该属性与DEFAULTCAPACITY_EMPTY_ELEMENTDATA相等,则在第一个元素被添加至实例时,该实例将自动扩展至DEFAULT_CAPACITY即10这个长度。
最后一个属性,private int size;注释描述为ArrayList包含的元素个数。
属性看完,来看一下构造方法,ArrayList在调用构造创建对象时可以指定初始化长度,也可以不指定创建一个默认长度的实例,或者Collection接口的实例并根据该实例创建一个对象。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}这是指定长度的构造,接收一个int类参数initialCapacity执行初始化,若该参数符合规范,大于0,则创建一个initialCapacity长度的数组,并使elementData的引用指向该数组,否则将elementData赋值为空数组。
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}无参构造,直接让elementData的引用指向DEFAULTCAPACITY_EMPTY_ELEMENTDATA,也是一个空的Object数组
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}接受Collection实例的构造方法,将所传实例直接调用自己实现的toArray()方法先转换成数组,然后使elementData的引用指向该数组,这里有一个额外的操作,当该数组的长度不为0(包含元素时),检查该对象是不是Object数组的实例,如果不是的话,则将该数组中的元素都复制出来,并存放至elementData所指向的Object数组中,如果为空,则还是执行之前的操作,使elementData指向空数组对象。
这就是几个构造方法,为什么先前要给出两个不同的Object空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA和EMPTY_ELEMENTDATA,我们在注释描述中和对构造方法的解析中找到了答案,在创建不同的实例时,我们为elementData赋值不同的属性以区别,空和默认还是不同的,空的实例很可能意味着该实例不必存储任何元素,而实例默认为空不代表它会一直为空,默认实例虽然初始化为空实例,但它是有存储元素的需求的,关于空实例存在的意义,我列举一个实际应用场景:
假如有方法如下
public List getUserInfo(){
````````````````````
List list = getUserList();
return list;
}
在这里,我们假设这个方法内部代码是获取用户信息列表并存储至某个list实例,最后返回这个list,假如方法中我做了try catch处理,在捕获异常时我不希望代码执行中断,我就可以在catch代码块中new ArrayList();并返回一个空的集合实例,空集合的存在意义类似与null值与有值的区别,空集合也是集合,只是不包含元素,长度为0,null值也是有值的,只是值为null;当然,它还可能有很多其它用处,我只是举个我认为比较明显的例子证明它的存在是有价值的。
在看完构造方法后,发现一个之前没怎么研究过的方法
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}这个方法内部首先对一个modCount的属性自增1,然后判断size(元素个数)是否小于数组长度,若小于,进一步判断size是否为0,为空则使数组引用指向空数组,将elementData重新赋值,该值即为原elementData的前size个元素。这个方法我理解是,要始终确保List实例中的元素个数与size是相同的,但是为什么只判断了size小于数组长度的情况呢?我接着结合源码去看。
首先,这个modCount是什么,为什么这个方法要让它自增1呢,按住ctrl点击这个属性发现,这是AbstractList中的 protected transient int modCount = 0;
这个属性的注释很长,概括起来就是这个属性要被迭代器使用,包括iterator和list专属的listiterator,随意修改这个值会导致使用迭代器时抛ConcurrentModificationExceptions
异常,这个属性为迭代器服务,任何AbstractList的子类若想使用非快速的迭代器遍历方式都需要有这个属性并在会使List实例结构改变的方法中使modCount属性增1,典型方法如add();看到这,我们知道这个属性的作用了。
顺序往下看
/**
* Increases the capacity of this <tt>ArrayList</tt> instance, if
* necessary, to ensure that it can hold at least the number of elements
* specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}方法名叫ensureCapacity,从简介来看就是确认容量,该方法就是确认List实例需要的最小容量,看下面这段话
* <p>An application can increase the capacity of an <tt>ArrayList</tt> instance
* before adding a large number of elements using the <tt>ensureCapacity</tt>
* operation. This may reduce the amount of incremental reallocation.某个应用在往ArrayList实例中添加大量元素之前可以通过调用该方法增加ArrayList实例的容量,该方法可以减少扩容的时候需要执行的元素重新定位操作的数量。
方法中注释也清晰,若是默认的空ArrayList实例,则只要minCapacity大于0为任意即可,否则至少应大于默认容量
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}方法内部调用了这个方法,该长度要大于当前实例的长度,随后调用grow()方法,grow()方法内部有一句注释,这是考虑到内存溢出的代码
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}这个方法计算了一个新的容量值,这个新的容量值是通过旧容量值加上旧值向右移位,将高位向右移动,关于移位运算,举个不恰当的例子,比如8,001000,你把它右移一位000100旧变成了4,移位还分带符号移位和不带符号移位,这里不细说,简单理解就是当前旧容量除以2,就是1.5倍旧容量,然后这个计算得来的新容量与指定容量对比,这两个方法就是在扩充数组长度时,对内存溢出的处理。
int newCapacity = oldCapacity + (oldCapacity >> 1);这句代码,如果执行后newCapacity大于Inter.MaxValue,则该值会变为负数,下面的代码就是针对该值变为负数的处理
hugeCapacity(minCapacity);这个方法返回Integer.MaxValue,最后也就是新建一个这么长的数组去作为List实例中存储元素的数组。因为int类型是有范围限制的,超出了它的范围,自然就会造成内存溢出。
public int size() {
return size;
}
/**
* Returns <tt>true</tt> if this list contains no elements.
*
* @return <tt>true</tt> if this list contains no elements
*/
public boolean isEmpty() {
return size == 0;
}后面这两个方法就是返回当前实例的元素个数和判断List实例是否为空
再后面
public boolean contains(Object o) {
return indexOf(o) >= 0;
}public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}contains方法与我们自己for循环遍历判断list实例中是否存在该元素是等价的。在后面是lastIndexOf()
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}因为list中可以存储重复元素,所以这里从后往前遍历来找最后的元素,故能找到该元素对应的最后一个索引。
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}因为ArrayList实现了Clonable接口,这个克隆方法就是实现当前实例的浅复制
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}将当前list实例转换成Object数组,数组内元素的顺序与原list保持一致
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}将list中的元素转换成某运行时类型的数组,如果数组的长度不够存储lits实例的元素,则创建一个新数组,否则将list元素复制到a数组内,如果复制后a中的元素个数大于list实例的元素个数,则将多出来的第一个元素立即赋值null
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}这就都是操作元素的方法了了,这个方法返回对应下标的数组元素
public E get(int index) {
rangeCheck(index);
return elementData(index);
}private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}获取之前对传入的下标参数校验,超出范围则抛出异常
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}最常用的get和set方法,set方法还会返回index下标对应的list中的旧值
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}add方法,在新增之前会计算一个新的合适的容量并进行和之前一样的内存溢出处理,新增长度为原来元素个数+1
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;这个常量对应的是规定数组的最大长度,我们不能将长度设置为int的最大值,而数组本身需要一定的栈容量存储自己的大小,这个需求量就是8byte,所以有了这个最大长度限制
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}在指定下标插入某元素,会将elementData的第index个元素及之后的元素复制到index+1及之后的位置,简单说就是第index个元素及之后的元素下标全部加1的新数组,内存溢出检测和之前一样,然后将第index个元素赋值为element,并使size自增1
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}移除指定下标元素,下标从0开始,长度从1开始,所以需要变动的元素个数是size - index -1;下标为index+1的元素及之后的元素下标全部-1;需要下标-1的元素个数为size - index -1.并将list中最后一个元素置为null
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}移除指定元素,这里判断需要移除元素的方法为equals,null单独处理因为用null调equals会报空指针,注意,所有改变原结构的方法,modCount都自增1
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}清除所有元素的方法,数组内元素全部置null,size置0,原先不理解为什么置为null就会清空集合,看到这句clear to let GC do its work时明白了,元素全部置null后会被GC回收,这里牵扯到java的垃圾回收机制,后面再学习。
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}我们常用的方法,通常用于将另一个set或者list实例(Collection接口实例)全部内容追加至当前ArrayList实例,代码很清晰,将c转换为数组,然后确认原list长度size+numNew是否会造成溢出,然后将c的全部内容追加到elementData中生成一个新数组
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}重写的addAll方法,平时用的不多,在指定位置插入某个集合,原集合的元素没有减少,只是下标变化,且长度变化
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}范围删除元素,同之前一样,只是因为是删除元素而没有检测是否内存溢出的操作,这个方法之后的几个校验方法旧略过了
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}public static <T> T requireNonNull(T obj) {
if (obj == null)
throw new NullPointerException();
return obj;
}private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}这个方法比较有趣,根据描述,是删除当前list中所有包含在指定集合中的元素,注意当前list中的元素是要和与指定集合中元素是可比较的,不然会抛ClassCastException,看代码,先是对参数判空,这个方法略复杂,我们逐行看
判空参数后,指定引用变量指向elementData,然后遍历该变量,将不包含在c集合中的元素重新赋值进数组,然后进finally模块,发现对r和size判等了,按理说遍历递增变量一定等于size,为什么会有不等的情况?看注释,如果传的c是个抽象类呢?这里会抛异常,r就会不等于size,此时r的值当为0,w值应当也为0,list实例不变,而如果w与size不等,则说明list实例的元素减少了,此时w就是减少后list的最大下标(数组从0开始),而w+1就是元素个数,由于w自增,最后的值会自动加一(先参与运算再自增一),减少的元素个数就是size-w,修改次数等于原次数加size-w,并且w即为现存list实例中的真实元素个数。看完这段方法不禁感慨,真是越短的代码越难理解,写的很简略,读起来比业务代码要复杂多了。
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}分析完上面的方法后,这个方法旧好理解了,这就是只保留包含在c中的list实例的元素,不包含的则删掉
之前提到过,实际存储元素的elementData数组是不会被序列化的,那么ArrayList实例在序列化之后会不会丢失它存储的数据呢?答案当然是不会,看下面这两个方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}/**
* Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}写方法将元素和size写到输出流中,这里就是对elementData的序列化和反序列化
迭代器的代码旧不细读了,值得注意的就是在使用迭代器删除元素的时候,如果原list发生变化modCount变化则会报错,因为迭代器对象保存了该值的副本,会在执行删除时进行对比,这就是为什么,在使用迭代器操作list时,不能增加或者删除元素
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}截取list的方法,同subString一样,它是包头不包尾的,而且它返回时其实是ArrayList的一个内部类,这个类的名字就叫SubList
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
public E set(int index, E e) {
rangeCheck(index);
checkForComodification();
E oldValue = ArrayList.this.elementData(offset + index);
ArrayList.this.elementData[offset + index] = e;
return oldValue;
}可以看到,SubList内部其实保存了原List,但是你截取之后只能操作截取的部分,这个子类的方法都是单独的,add,get都是单独实现,subList方法返回的是list的某一段视图,有个小技巧,可以通过
list.subList(from, to).clear();来清空List指定部分内容
sublist的内部方法和list几乎一样,就不再多说
最后看看foreach方法
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
void accept(T t);
/**
* Returns a composed {@code Consumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code Consumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}Consumer<? super E>简单理解成Consumer实例就好,这个接口没有任何动作,只是接收遍历的元素,具体对这个元素做什么,由用户自己定义,所以叫做action(动作),它是一个典型的函数式接口,而其中的参数t就是每次遍历时传进来的元素,accept表示接受该元素,而该方法体中就是操作元素的定义了,andThen用于链式编程,函数式接口支持lambuda表达式,所以在java8中,list支持lambuda遍历(这段是我找的,写到这里时我也不是很理解,勉强懂一点意思,后面再学lambuda估计就能更好的理解了)
最后总结一下:
1 网上有流传说ArrayList初始化会创建一个长度为10的数组,可能jdk8之前是这么做的,但jdk8之后不是了,10这个容量指标只是个参与容量确定运算的默认值
2 ArrayList的内存溢出处理是针对元素长度的,单个元素过大导致的栈溢出好像是没有处理的
3 从本质来说,ArrayList其实就是一个Object数组,每次新增元素时,都会在当前容量下和容量+1对比确定最佳容量
4 subList方法返回的不是ArrayList的实例,而是内部类SuList的实例,为ArrayList的某一段视图。

















 2678
2678







 到【灌水乐园】发言
到【灌水乐园】发言







