







 本文详细介绍了Redis集群的搭建过程,包括数据分布策略、安装步骤、集群伸缩方法及客户端路由机制。深入探讨了故障转移与集群运维策略,以及Redis集群在实际应用中的优势与挑战。
本文详细介绍了Redis集群的搭建过程,包括数据分布策略、安装步骤、集群伸缩方法及客户端路由机制。深入探讨了故障转移与集群运维策略,以及Redis集群在实际应用中的优势与挑战。
1.数据分布
1.1 顺序分区
产品:HBase 、BigTable
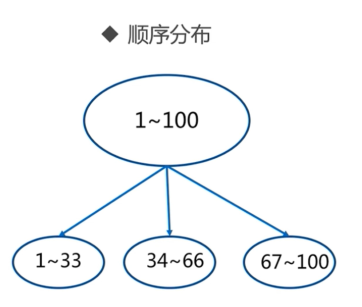
1.2 哈希分区
1.2.1 节点取余
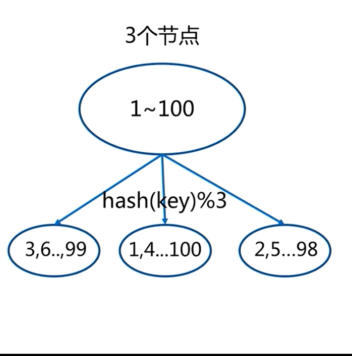
缺点:扩容节点时,迁移率非常高。建议翻倍扩容(3--->6),可降低到50%(也很高)
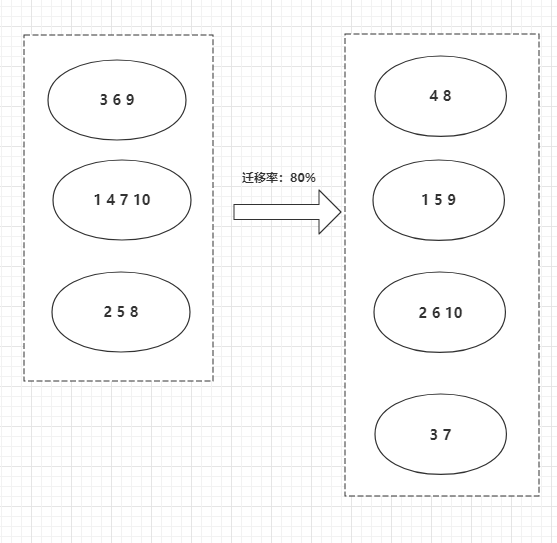
1.2.2 一致性哈希
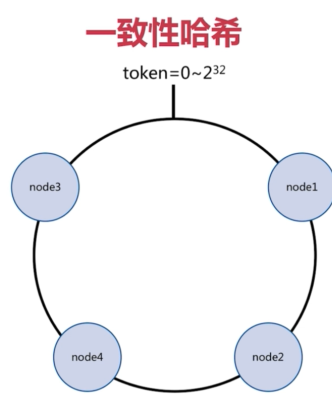
一致性哈希:每次扩容或者缩容只影响附近的节点;
缺点:没有办法实现数据的负载均衡,建议翻倍伸缩
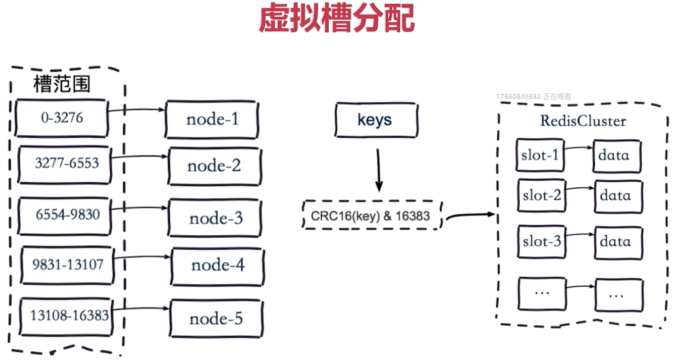
1.2.3 虚拟槽分区
产品:Redis集群
虚拟槽:每个槽映射一个数字子集,一般比节点数大
2 安装集群
2.1 安装步骤

- 节点:开启集群模式:cluster-enabled:yes
- meet:节点间相互通信,获取彼此的信息
- 指派槽:指定该节点负责的槽位
- 主从复制: 主从复制不依赖于哨兵,通过节点间的相互监控
2.2 原生命令安装
2.2.1 配置节点
port 7000 daemonize yes dir "./" logfile "${port}.log" dbfilename "dump-${port}.rdb" cluster-enabled yes #是否开启集群 cluster-config-file nodes-${port}.conf #集群配置文件 cluster-node-timeout 15000 #15s,节点超时时间 cluster-require-full-coverage no #当有节点宕机时,集群是否不可用
复制配置文件:
sed 's/7000/7001/g' 源目录 目标目录 sed 's/7000/70002/g' 7000/redis.conf > 7002/redis.conf
启动服务:
redis-server redis.conf redis-cli -p 端口号 cat node.conf //查看节点配置文件 redis-cli -p 7000 cluster nodes //查看节点信息 redis-cli -p 7000 cluster info //查看集群信息
查看信息
cluster info //查看集群信息 cluster nodes // 查看节点信息
2.2.2 节点互通
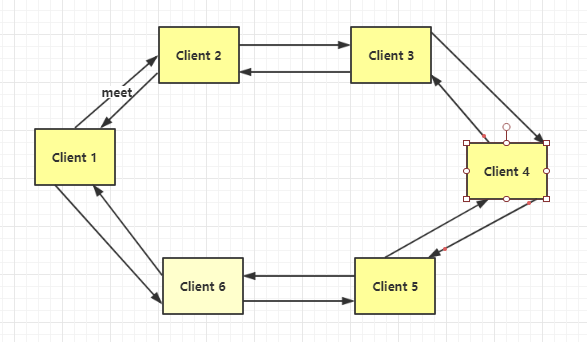
只要一个节点meet其他节点,所有节点就都连通了。
# cluster meet ip port redis-cli -p 7000 cluster meet 127.0.0.1 7001 //7000meet7001 cluster nodes// 可以查看节点信息
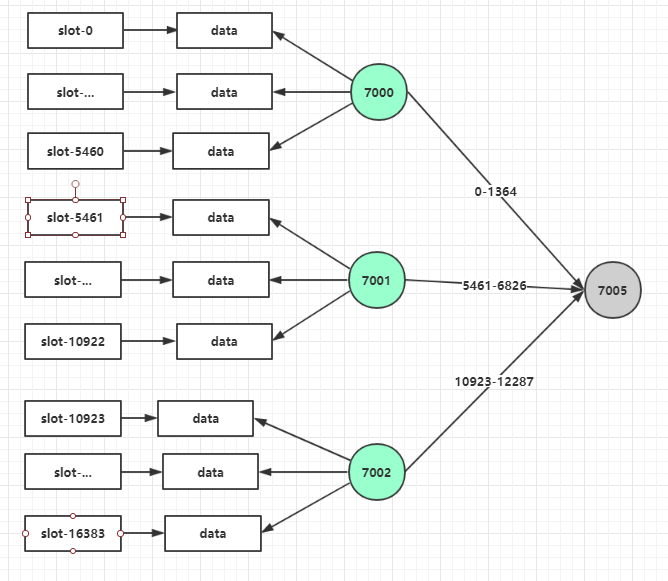
2.2.3 分配槽位
cluster addslots slot cluster slots //查看槽位信息
脚本:
#!/bin/bash start=${1} end=${2} port=${3} for slot in `seq ${start} ${end}` do echo "slot:${slot}" redis-cli -p ${port} cluster addslots ${slot} done
2.2.4 设置主从
cluster replicate 主节点NodeId nodeId不同于runId,nodeId不会因为机器重启而改变
2.3 官方工具安装
2.3.1 安装ruby工具包
//下载压缩包 yum install ruby wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz //解压 tar -zxvf 目录 ./configure -prefix=/usr/local/ruby //安装 make & make install // 下载rubygems wget http://rubygems.org/downloads/redis-3.3.0.gem # 安装rubygems gem install -l redis-3.3.0.gem gem list --check redis gem # 复制配置文件到usr/local/bin下 将redis-trib.rb文件复制到usr/local/bin下 cp ${Redus_Home}/src/redis-trib.rb /usr/local/bin
2.2.2 启动集群
// 启动Redis redis-server redis.conf // 创建集群 redis-trib.rb create --replicas 1(从节点个数) 127.0.0.1:8000 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005
3 集群伸缩
3.1 扩容集群
- 加入主节点实现扩容
- 加入从节点实现故障转移
3.1.1 准备新节点
配置文件-> 启动服务 ->孤立节点
3.1.2 加入集群
// 命令式 cluster meet IP地址 端口号 // 工具式 【好处:在meet前会检测当期节点是否是孤立节点,避免两个集群狼狈为奸】 redis-trib.rb add-node new_host:new_port existing_host:existing_port --slave --mastser-id
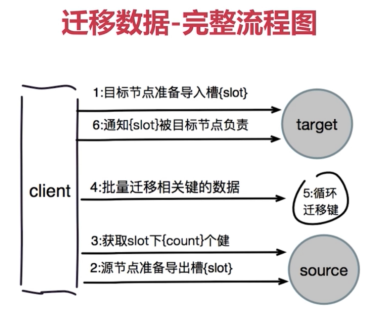
3.1.3 迁移槽和数据
- 对目标节点发送:cluster setslot {slot} importing {sourceNodeId}命令,让目标节点准备导入槽的数据;
- 对源节点发生:cluster setslot {slot} migrating {targetNodeId}命令,让源节点准备迁出槽的数据;
- 源节点循环执行cluster getkeysinslot {slot} {count}命令,每次获取count个属于槽的键;
- 在源节点执行 migrate {targetIp} {targetPort} key 0(数据库,集群下只有一个数据库 db0) {timeout} 命令把指定的key迁移走
- 重复执行3,4直到槽下所有的键数据迁移到目标节点
- 向集群内所有主节点发送cluster setslot {slot} node {targetNodeId} 命令,通知槽分配给了目标节点
Redis3.0.6 支持pipeline功能,可以批量迁移key,但是有bug(如果同时混合有过期数据和非过期数据,会将非过期数据置为过期数据,导致数据丢失),3.2.8修复该bug
3.1.4 集群扩容
//1.复制配置文件 sed "s/8000/8007/g" redis-8000.conf > redis-8007.conf //2.检查配置文件 cat redis-8007.conf //3.启动服务 redis-server redis-8007.conf //4.添加节点 //4.1 添加主节点 redis-trib.rb add-node 127.0.0.1:8006 127.0.0.1:8000 cluseter nodes //检查节点信息 //4.2 添加从节点 redis-trib.rb add-node new_host:new_port existing_host:existing_port --slave --master-id 主节点NodeId cluseter nodes //检查节点信息 // 主从复制 cluster replicate masterNodeId //5.分配槽位&迁移数据 redis-trib.rb reshard existing_host:existing_port How many slots do you want to move (from 1 to 16384)? //打算迁移多个个槽(总和) What is the receiving node ID? //接收NodeId soureId: //从哪个节点迁移,all--代表全部 cluseter nodes
3.2 收缩集群
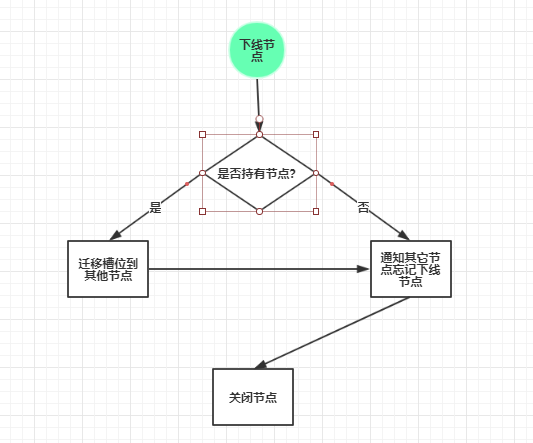
忘记节点 :cluster forget {downNodeId}
//1.查看当前节点信息 cluster nodes //2.迁移数据 redis-trib.rb reshard --from 源节点NodeId --to 目标节点NodeId --slots 迁移槽位数 existing_host:existing_port //3.下线节点 [先下从节点,再下主节点;先下主节点会触发故障自动转移] redis-trib.rb del-node existing_host:existing_port 下线节点NodeId
4 客户端路由
4.1 moved重定向
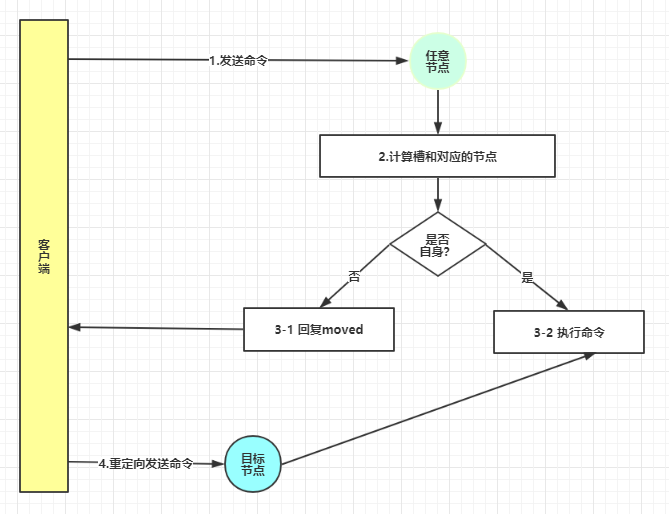
/** redis-cli -p 端口号 [非集群模式] **/ //1.计算槽位 cluster keyslot key //计算槽位 //2.set值 set php best (error) MOVED 9244 127.0.0.1:8001 //重定向 //3.手动切换& 设值 redis-cli -p new_port /** redis-cli -c -p 端口号 [集群模式] **/ //自动跳转&执行命令 127.0.0.1:8000> set php hello -> Redirected to slot [9244] located at 127.0.0.1:8001 OK 127.0.0.1:8001>
4.2 ask重定向
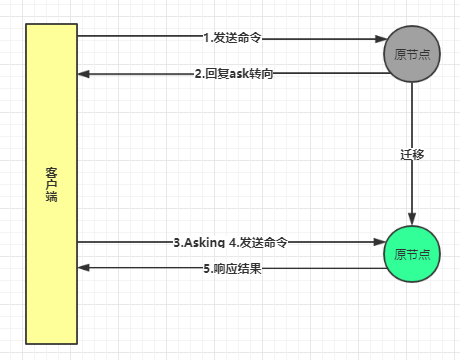
4.3 smart客户端
public class JedisClusterFactory { /** * JedisCluster */ private JedisCluster jedisCluster; /** * 主机:端口号 */ private List<String> hostPortList; /** * 超时时间 */ private int timeout; /** * Init方法 */ public void init() { // 配置 JedisPoolConfig poolConfig = new JedisPoolConfig(); // 节点集 Set<HostAndPort> nodeSet = new HashSet<HostAndPort>(); for (String hostPort : hostPortList) { String[] arr = hostPort.split(":"); if (arr.length != 2) { continue; } nodeSet.add(new HostAndPort(arr[0], Integer.valueOf(arr[1]))); } //创建JedisCluster try { jedisCluster = new JedisCluster(nodeSet, timeout, poolConfig); } catch (Exception e) { e.printStackTrace(); } } /** * 销毁 */ public void destory() { if (jedisCluster != null) { jedisCluster.close(); } } /** * 获取客户端 * @return */ public JedisCluster getJedisCluster() { return jedisCluster; } public void setHostPortList(List<String> hostPortList) { this.hostPortList = hostPortList; } public void setTimeout(int timeout) { this.timeout = timeout; } }
4.4 多节点命令实现
//获取所有节点JedisPool Map<String, JedisPool> jedisPoolMap = jedisCluster.getClusterNodes(); for (Map.Entry<String, JedisPool> entry : jedisPoolMap.entrySet()) { //获取每个Jedis连接 Jedis jedis = entry.getValue().getResource(); //过滤非主节点 if(!isMaster(jedis)){ continue; } //do something }
4.5 如何实现批量操作
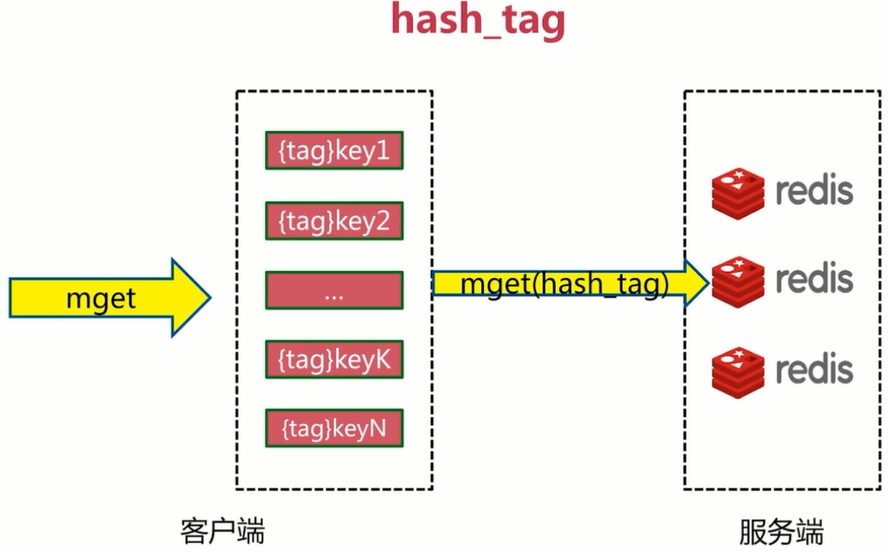
mget、mset无法保证所有key都在同一槽上;
- 方案一:串行mget
for循环遍历所有的key,时间复杂度 O(key个数)
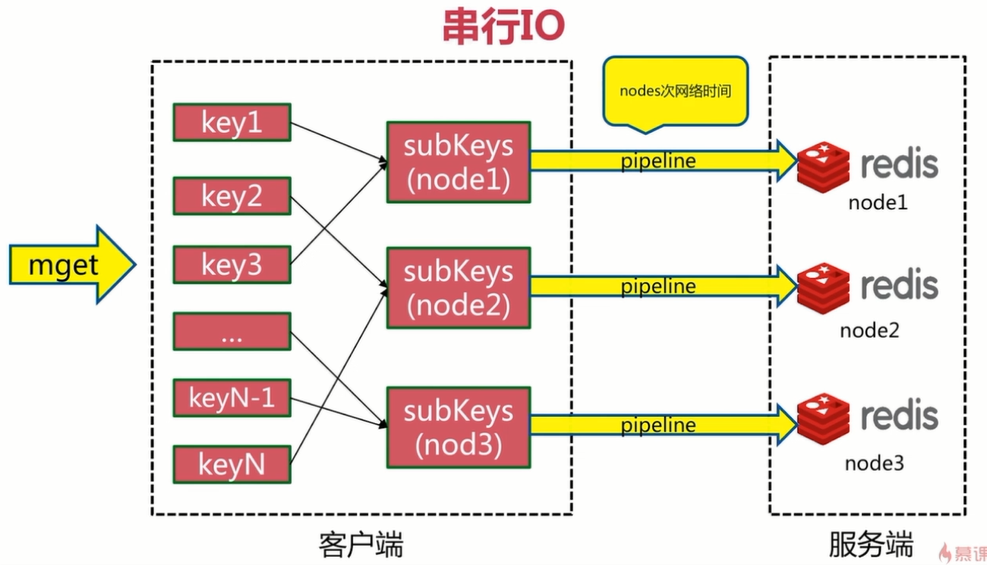
- 方案二:串行IO
将同一槽位的数据存储在同一个队列里,然后执行pipeline,时间复杂度O(节点个数)
- 并行IO
在串行IO的基本上,启动多线程,时间复杂度O(1)
- hash_tag
使用hash,包装同一key,放在同一节点,时间复杂度O(1)
5 故障转移 &集群运维
5.1 故障发现
5.1.1 主观下线
某一节点人为某节点不可用
5.1.2 客观下线
半数以上持有槽的主节点都标记某节点下线
5.2 故障恢复
主管下线 --> 客观下线 --> 故障恢复【资格检查(与主节点断线超过150s[默认配置]的从节点不具备竞选资格) -> 准备选举时间(与主节点断线时间最短的节点先选举) -->选举投票(获得半数以上主节点的从节点,选举为主节点) --> 替换主节点 (slaveof no one 、然后把主节点的槽分配给自己、广播自己的信息)】
5.3 集群运维
5.3.1 集群完整性
cluster-require-full-coverage no//是否槽位都可用时,集群才可用。
5.3.2 网络带宽
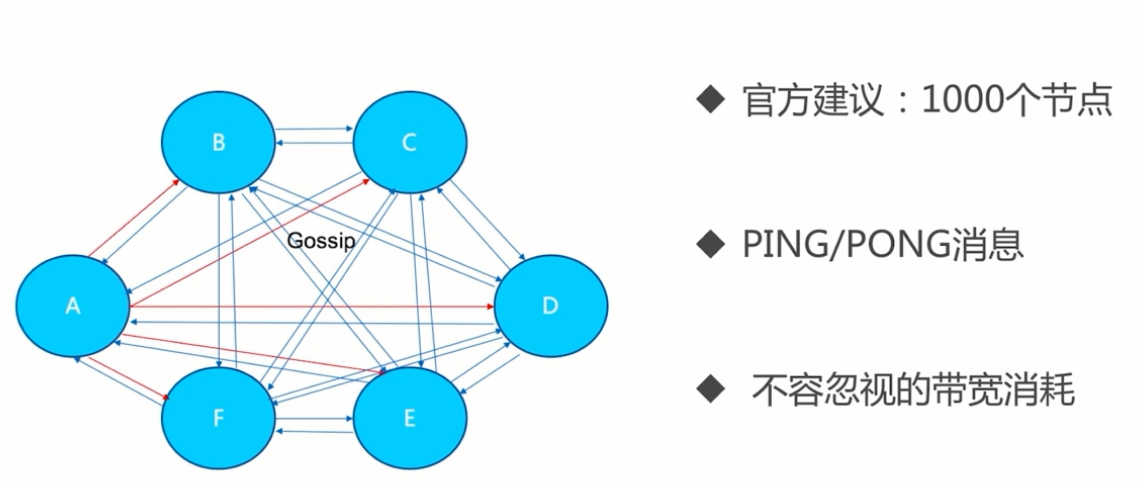
建议:
- 大集群转为多集群
- cluster-node-timeout:故障转移时间和网络带宽(1/2 timeout会进行一次节点互通)的权衡
5.3.3 集群倾斜
- 节点和槽分配不均
- 不同槽对应的键值数量差异较大
- 包含bigkey (redis-cli -bigkeys)
- 内存配置不一样
5.3.4 读写分离

5.3.5 数据迁移

redis-trib.rb import --from sourceHost:sourcePort --copy[--replace] tartgetHost:targetPort
note:官方工具是离线的(在迁移期间的新增的数据不一定会同步过去,因为采用的是scan)
5.3.6 集群的限制


6.
6.1 收益&代价
收益:
- 加速读写
- 降低后端负载(Mysql)负载
成本:
- 数据不一致:缓存层和数据层的数据不一致
- 代码维护成本:多了一层缓存逻辑
- 运维成本:RedisCluster
使用场景:
- 加速请求响应时间
- 降低后端负载
- 大量写合并为批量写(eg:计数器)
6.2 缓存更新策略
- LRU/FIFO算法剔除:
- 超时剔除:设置过期时间
- 主动更新
低一致性:最大内存和淘汰策略
高一致性:超时剔除和主动更新结合
6.3 缓存穿透问题
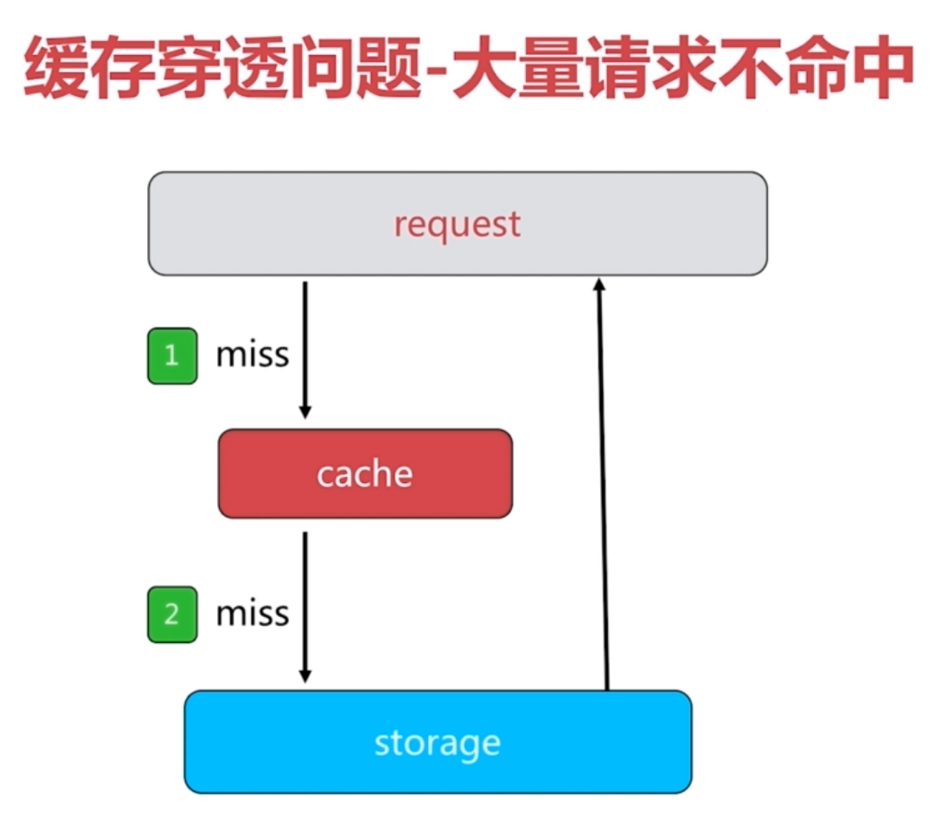
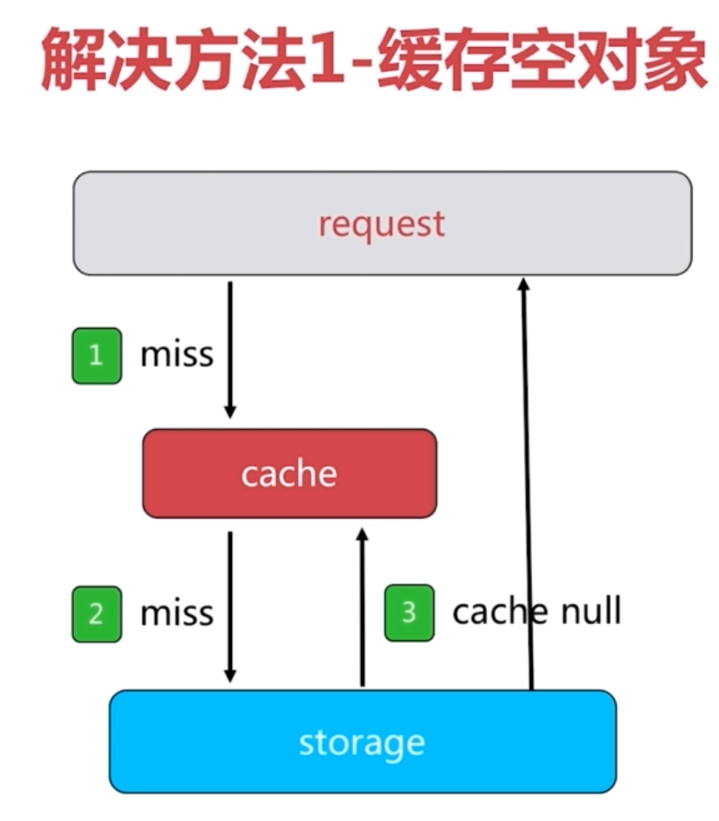
不足:1.需要更多的键 2.缓存层和存储层数据短期不一致
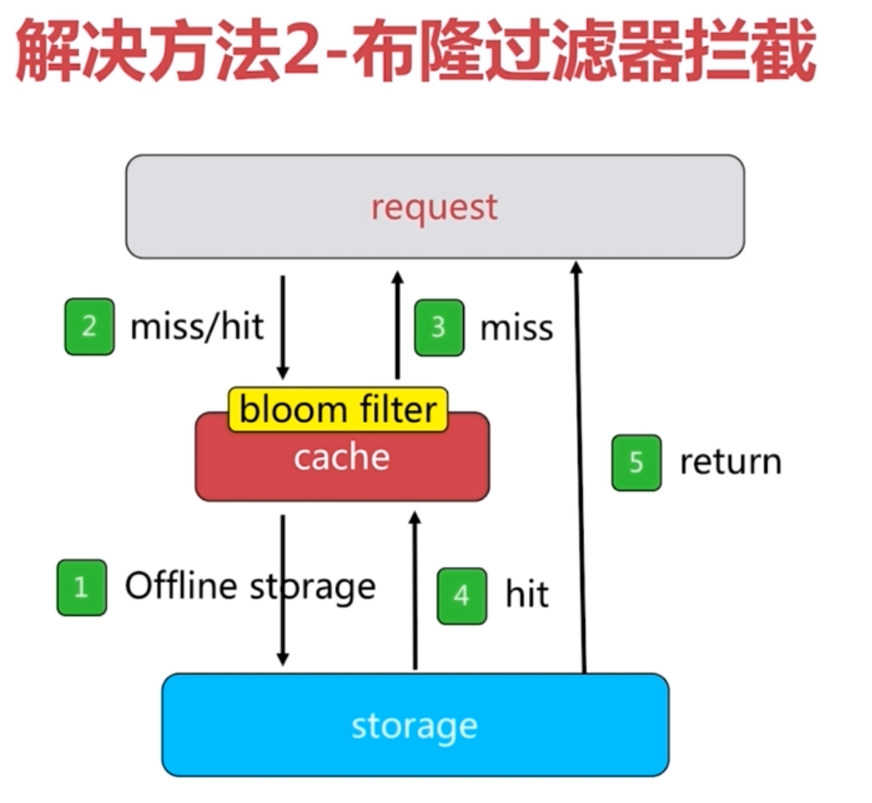
maven坐标:
<!-- https://mvnrepository.com/artifact/redis.clients/jedis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.0.1</version> </dependency>
连通性测试:
public static void main(String[] args) {
String host ="192.168.3.12";
int port =7000;
Jedis redis = new Jedis(host,port);
System.out.println(redis.ping());
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









