




 本文介绍了一种处理包含中文及特殊字符的URL的方法。通过判断URL中是否存在中文字符,并在转码前替换特殊字符,确保URL的有效性。
本文介绍了一种处理包含中文及特殊字符的URL的方法。通过判断URL中是否存在中文字符,并在转码前替换特殊字符,确保URL的有效性。
在做爬虫时,爬下来的书籍的URL地址各式各样,什么情况都有。
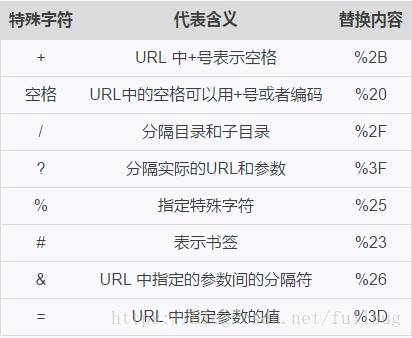
有的url地址既有中文,又有%20 空格等特殊字符。如 http://www.ishareread.com/book/2018/不成问题的问题%20-%20老舍.mobi
如果是在url中有中文需要转码,但转码后会将%号替换成%25,导致url不能访问了。
解决的办法,先判断url中是否有中文,如果有中文,则替换特殊字符,再进行转码。
代码如下:
判断字符串是否含有中文的方法:
public static boolean isContainChinese(String str) {
Pattern p = Pattern.compile("[\u4e00-\u9fa5]");
Matcher m = p.matcher(str);
if (m.find()) {
return true;
}
return false;
}
#先判断是否有中文,然后替换特殊字符,再转码,一般来说英文的url是不需要转码的。
if(StringUtil.isContainChinese(ebookDownloadUrl))
{
try
{
ebookDownloadUrl=ebookDownloadUrl.replaceAll("%20", " ");
ebookDownloadUrl=UriUtils.encodePath(ebookDownloadUrl, "UTF-8");
}
catch(Exception ex)
{
log.error(String.format("解释文件路径失败,URL地址为%s", ebookDownloadUrl), ex);
}
}
return "redirect:" +ebookDownloadUrl;


















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











