




 本文介绍了链表在数据结构中的重要性,特别是它在实现LRU缓存淘汰算法中的应用。LRU缓存策略是决定何时从缓存中移除数据的策略之一。文章讲解了链表与数组的性能对比,强调了链表在插入和删除操作上的优势,同时指出链表的随机访问性能较差。通过讨论单链表、双向链表和循环链表,阐述了链表的不同形态和优缺点。最后,文章提出如何使用链表来实现LRU缓存淘汰策略,并分析了其时间复杂度,提示可以进一步使用散列表进行优化。
本文介绍了链表在数据结构中的重要性,特别是它在实现LRU缓存淘汰算法中的应用。LRU缓存策略是决定何时从缓存中移除数据的策略之一。文章讲解了链表与数组的性能对比,强调了链表在插入和删除操作上的优势,同时指出链表的随机访问性能较差。通过讨论单链表、双向链表和循环链表,阐述了链表的不同形态和优缺点。最后,文章提出如何使用链表来实现LRU缓存淘汰策略,并分析了其时间复杂度,提示可以进一步使用散列表进行优化。
今天我们来聊聊“链表(Linked list)”这个数据结构。学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是LRU缓存淘汰算法。
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的CPU缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略FIFO(First In,First Out)、最少使用策略LFU(Least Frequently Used)、最近最少使用策略LRU(Least Recently Used)。
这些策略你不用死记,我打个比方你很容易就明白了。假如说,你买了很多本技术书,但有一天你发现,这些书太多了,太占书房空间了,你要做个大扫除,扔掉一些书籍。那这个时候,你会选择扔掉哪些书呢?对应一下,你的选择标准是不是和上面的三种策略神似呢?
好了,回到正题,我们今天的开篇问题就是:如何用链表来实现LRU缓存淘汰策略呢? 带着这个问题,我们开始今天的内容吧!
五花八门的链表结构
相比数组,链表是一种稍微复杂一点的数据结构。对于初学者来说,掌握起来也要比数组稍难一些。这两个非常基础、非常常用的数据结构,我们常常会放到一块儿来比较。所以我们先来看,这两者有什么区别。
我们先从底层的存储结构上来看一看。
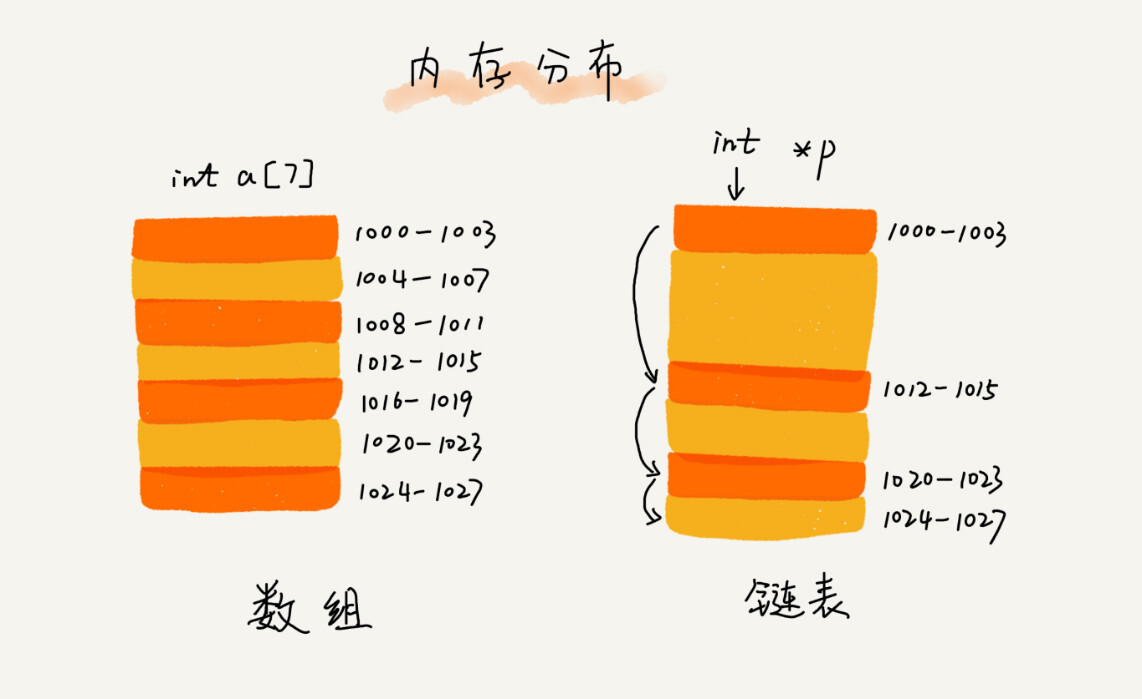
为了直观地对比,我画了一张图。从图中我们看到,数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个100MB大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于100MB,仍然会申请失败。
而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是100MB大小的链表,根本不会有问题。
链表结构五花八门,今天我重点给你介绍三种最常见的链表结构,它们分别是:单链表、双向链表和循环链表。我们首先来看最简单、最常用的单链表。
我们刚刚讲到,链表通过指针将一组零散的内存块串联在一起。其中,我们把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。如图所示,我们把这个记录下个结点地址的指针叫作后继指针next。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















:如何实现LRU缓存淘汰算法&spm=1001.2101.3001.5002&articleId=134072903&d=1&t=3&u=61d28df8fc2340cab356f330472e8bf9)
 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









