




 本文介绍如何使用PyFPDF库生成PDF文档,包括安装、基本用法、字体设置、绘图功能等。通过示例代码展示如何创建简单文档、添加字体及绘制线条和形状。
本文介绍如何使用PyFPDF库生成PDF文档,包括安装、基本用法、字体设置、绘图功能等。通过示例代码展示如何创建简单文档、添加字体及绘制线条和形状。
原文地址:
顺藤摸瓜找到一个有很多学习python电子书的窝。在这里 希望你喜欢。
文章是自己瞎翻译的,不足之处,麻烦指出。
生成PDFs文件,我会将 ReportLab作为首选工具。不过,我发现在Python里面还有其他类似的工具,比如:PyFPDF 或者 FPDF for Python. PyFPDF包实际上是PDF免费系统包中的一员,他是用PHP开发的。最近几年都没有更新了,但是在Github上,最近还是有提交更新的。也就是说这个项目的开发工作没有停止。PyFPDF 包支持 Python 2.7 和 Python 3.4+。
本文不打算事无巨细的把PyPDF 包的各个方面都讲到。只涉及到创建pdf的基本知识点。注意到有一本小册子专门讲这个:Python does PDF: pyFPDF。如果你想学到更多,下一本吧。
安装
安装非常简单,因为它基于pip设计的,一行命令搞定:
# python 2
sudo python -m pip install fpdf
# python 3
sudo python3 -m pip install fpdf
在安装的时候你会注意到,它是没有任何依赖的。爽吧!
基本用例
现在你已经安装了PyPDF, 开始创建一个简单的PDF文档吧。
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size=12)
pdf.cell(200, 10, txt="Welcome to Python!", ln=1, align="C")
pdf.output("simple_demo.pdf")
第一行需要从fpdf pakage 导入FPDF,此类的默认值是在纵向模式下创建PDF,使用毫米作为其测量单位并使用A4页面大小。如果你想要显式,你可以像这样编写实例化行:
pdf = FPDF(orientation='P', unit='mm', format='A4')
我不喜欢用字母’P’来告诉class它的方向是什么。如果你喜欢风景样式(横着排版)而不是肖像样式(竖着排版),你也可以使用’L’。
PyFPDF软件包支持’pt’,'cm’和’in’作为替代测量单位。
如果您深入了解源代码,您会发现PyFPDF软件包仅支持以下页面大小:
- A3
- A4
- A5
- letter
- legal
与ReportLab相比,这有点限制,您可以在其中支持几种额外的尺寸,并且您也可以将页面大小设置为自定义。
无论如何,下一步是使用add_page方法创建页面。然后我们通过set_font方法设置页面的字体。您将注意到我们传入了字体的系列名称和我们想要的大小。您还可以使用style参数设置字体的样式。如果你想这样做,请注意它需要一个字符串,如’B’表示粗体,或者’BI’表示Bold-Italicized。
接下来,我们创建一个宽200毫米,高10毫米的单元。单元格基本上是可流动的,可以保存文本并且可以启用边框。如果启用了自动分页功能并且单元格超出页面大小限制,它将自动分割。 txt参数是要在PDF中打印的文本。 ln参数告诉PyFPDF如果设置为1则添加换行符,这就是我们在这里所做的。最后,我们可以将文本的对齐方式设置为对齐(默认)或居中(‘C’)。我们在这里选择了后者。
最后,我们通过调用带有我们要保存的文件路径的输出方法将文档保存到磁盘。
当我运行此代码时,我最终得到了一个如下所示的PDF:

注意,原文没有说对中文的支持。这个时候需要下载支持中文的字体了。fireflysung.ttf下载。下下来放在脚本相同的目录里面。
#!/usr/bin/python3
from fpdf import FPDF
pdf=FPDF()
pdf.add_page()
pdf.add_font('fireflysung','','./fireflysung.ttf', uni=True)
pdf.set_font('fireflysung','',14)
pdf.write(8, u'Hello World!香港和台湾是中国不可分割的一部分!只有一代又一代的人奋斗下去,国家才会强大!只有国家强大,人民才有希望!')
pdf.output('test.pdf','F')
如果想添加水印,可以看这里
设置字体
PyFPDF有一组硬编码到其FPDF类中的核心字体:
self.core_fonts={'courier': 'Courier',
'courierB': 'Courier-Bold',
'courierBI': 'Courier-BoldOblique',
'courierI': 'Courier-Oblique',
'helvetica': 'Helvetica',
'helveticaB': 'Helvetica-Bold',
'helveticaBI': 'Helvetica-BoldOblique',
'helveticaI': 'Helvetica-Oblique',
'symbol': 'Symbol',
'times': 'Times-Roman',
'timesB': 'Times-Bold',
'timesBI': 'Times-BoldItalic',
'timesI': 'Times-Italic',
'zapfdingbats': 'ZapfDingbats'}
您会注意到,即使我们在前面的示例中使用过Arial,也未在此处列出。 Arial在实际的源代码中被重新映射到Helvetica,所以你根本就没有真正使用Arial。无论如何,让我们学习如何使用PyFPDF更改字体:
# change_fonts.py
from fpdf import FPDF
def change_fonts():
pdf = FPDF()
pdf.add_page()
font_size = 8
for font in pdf.core_fonts:
if any([letter for letter in font if letter.isupper()]):
# skip this font
continue
pdf.set_font(font, size=font_size)
txt = "Font name: {} - {} pts".format(font, font_size)
pdf.cell(0, 10, txt=txt, ln=1, align="C")
font_size += 2
pdf.output("change_fonts.pdf")
if __name__ == '__main__':
change_fonts()
在这里,我们创建一个名为change_fonts的简单函数,然后创建FPDF类的实例。下一步是创建一个页面,然后循环核心字体。当我尝试这个时,我发现PyFPDF并不认为其核心字体的变体名称是有效字体(即helveticaB,helveticaBI等)。因此,为了跳过这些变体,我们创建一个列表理解并检查字体名称中的任何大写字符。如果有,我们跳过该字体。否则我们设置字体和字体大小并写出来。我们还通过循环每次将字体大小增加两个点。如果要更改字体的颜色,则可以调用set_text_color并传入所需的RGB值。
结果如下:

我喜欢在PyFPDF中更改字体是多么容易。但是核心字体的数量非常少。您可以使用PyFPDF添加TrueType,OpenType或Type字体,但需要通过add_font方法。此方法采用以下参数:
- family (font family)
- style (font style)
- fname (font file name or full path to font file)
- uni (TTF Unicode flag)
PyFPDF文档使用的示例如下:
pdf.add_font('DejaVu', '', 'DejaVuSansCondensed.ttf', uni=True)
在尝试通过** set_font 方法使用它之前,您可以调用 add_font **。我在Windows上试过这个并且因为Windows无法找到这个字体而出现错误,这正是我的预期。这是一种非常简单的添加字体的方法,可能会起作用。请注意,它使用以下搜索路径:
- FPDF_FONTPATH
- SYSTEM_TTFONTS
这些似乎是在您的环境或PyFPDF包本身中定义的常量。文档没有解释如何设置或修改它们,但是,如果仔细查看API和源代码,您似乎必须在代码的开头执行以下操作:
import fpdf
fpdf.SYSTEM_TTFONTS = '/path/to/system/fonts'
否则,SYSTEM_TTFONTS默认设置为None。
画画
PyFPDF包具有有限的绘图支持。您可以绘制线条,椭圆和矩形。我们先来看看如何绘制线条:
# draw_lines.py
from fpdf import FPDF
def draw_lines():
pdf = FPDF()
pdf.add_page()
pdf.line(10, 10, 10, 100)
pdf.set_line_width(1)
pdf.set_draw_color(255, 0, 0)
pdf.line(20, 20, 100, 20)
pdf.output('draw_lines.pdf')
if __name__ == '__main__':
draw_lines()
这里我们调用line方法并传递两对x / y坐标。线宽默认为0.2 mm,因此我们通过调用set_line_width方法将第二行的宽度增加到1 mm。我们还通过将set_draw_color调用为等于红色的RGB值来设置第二行的颜色。输出如下所示:
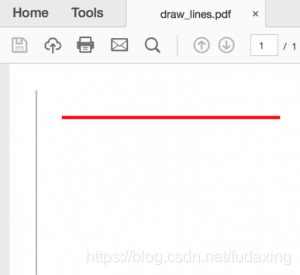
现在我们可以继续前进并绘制几种形状:
# draw_shapes.py
from fpdf import FPDF
def draw_shapes():
pdf = FPDF()
pdf.add_page()
pdf.set_fill_color(255, 0, 0)
pdf.ellipse(10, 10, 10, 100, 'F')
pdf.set_line_width(1)
pdf.set_fill_color(0, 255, 0)
pdf.rect(20, 20, 100, 50)
pdf.output('draw_shapes.pdf')
if __name__ == '__main__':
draw_shapes()
绘制椭圆或矩形等形状时,需要传入代表图形左上角的x和y坐标。然后你会想要传递形状的宽度和高度。您可以传入的最后一个参数是样式,可以是“D”或空字符串(默认),“F”表示填充或“DF”表示绘制和填充。在此示例中,我们填充椭圆并使用矩形的默认值。结果最终看起来像这样:



















 2740
2740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









