







 本文探讨了RAG(检索增强生成)在解决大型语言模型(LLM)如幻觉问题、数据安全和时效性问题上的作用。RAG通过引入检索机制增强LLM的性能。介绍了LlamaIndex框架,用于实现RAG,提供了从环境准备到高级定制的详细步骤,包括数据连接器、嵌入模型、向量存储和聊天机器人的构建。
本文探讨了RAG(检索增强生成)在解决大型语言模型(LLM)如幻觉问题、数据安全和时效性问题上的作用。RAG通过引入检索机制增强LLM的性能。介绍了LlamaIndex框架,用于实现RAG,提供了从环境准备到高级定制的详细步骤,包括数据连接器、嵌入模型、向量存储和聊天机器人的构建。
RAG(检索增强生成)在LLM(大型语言模型)中的应用
1.为什么需要RAG?
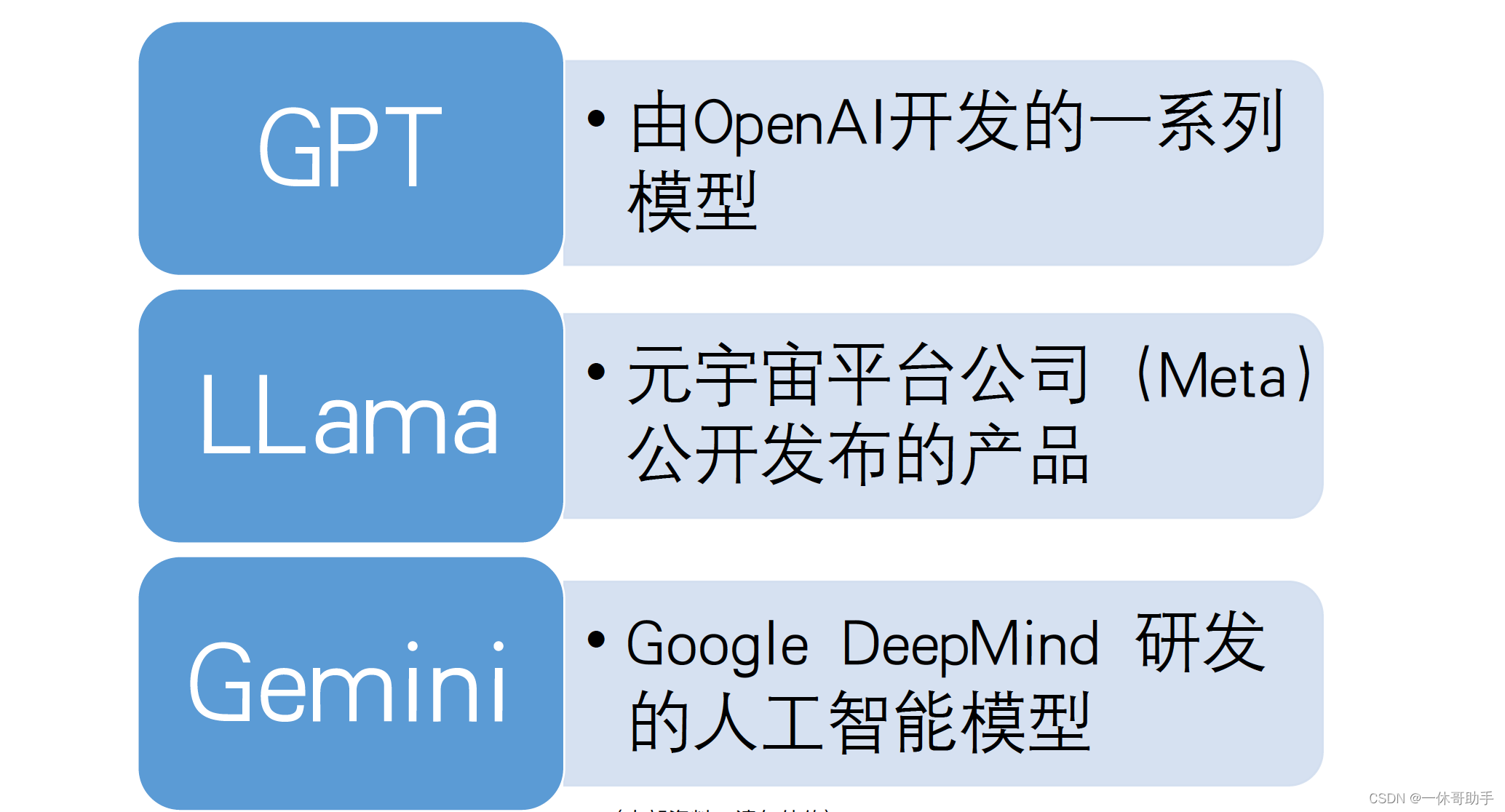
1.1 国外现有的LLM系列
1.2 RAG解决LLM存在的问题
幻觉问题:
对于一些相对通用和大众的知识,LLM 通常能生成比较准确的结果,而对于一些专业知识,LLM 生成的回复通常并不可靠,甚至有时候会一本正经胡说八道
数据安全
OpenAI已经遭到过几次隐私数据的投诉。而对于企业来说,如果把自己的经营数据、合同文件等机密文件和数据上传到互联网上的大模型会很不安全。
时效问题
由于 LLM 中学习的知识来自于训练数据,数据不是最新的。对于一些高时效性的事情,大模型更加无能为力。
2.什么是RAG?
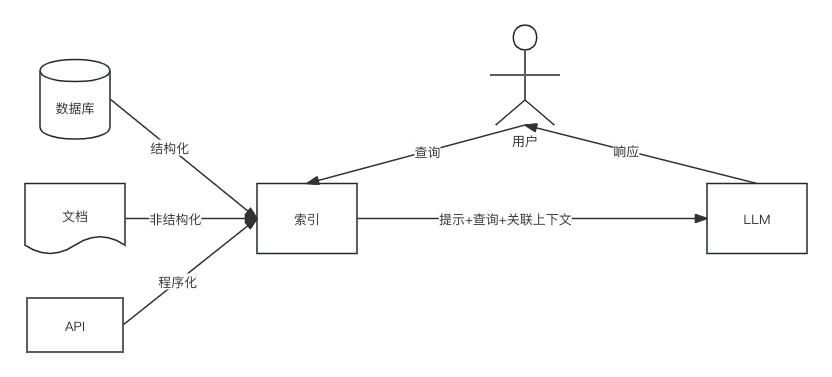
2.1 RAG的过程
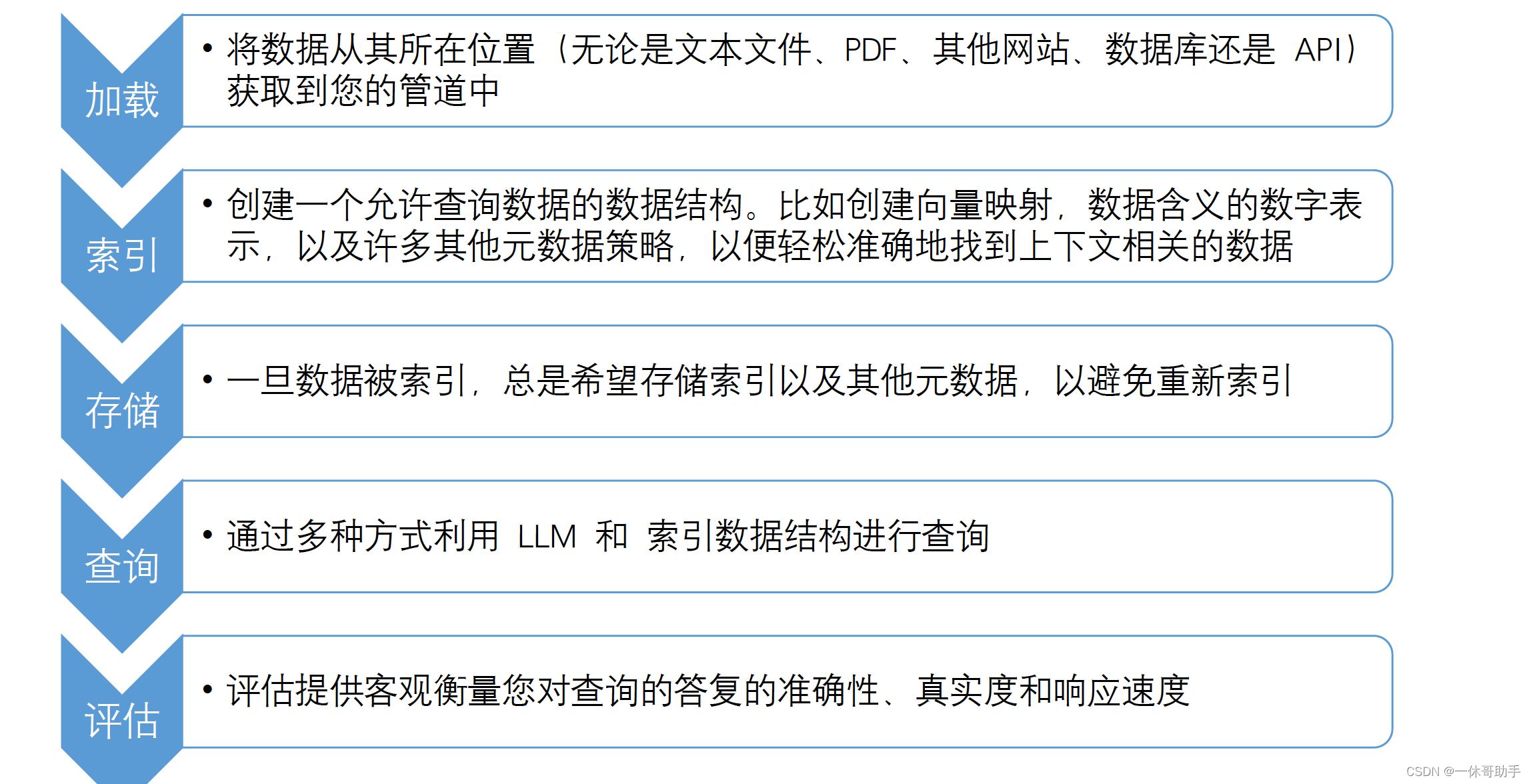
2.2 RAG 的关键阶段
3.如何实现RAG?
3.1 通过llamaindex框架实现RAG
LlamaIndex 是一个数据框架,供基于LLM的应用程序摄取、构建和访问私有或特定域的
数据。
LlamaIndex是为初学者和高级用户设计的。高级API允许初学者使用LlamaIndex在5行代
码中摄取和查询他们的数据。低级api允许高级用户自定义和扩展任何模块(数据连接器、
索引、检索器、查询引擎、重新排序模块),以满足他们的需求。
3.2 llamaindex的使用
(1)环境准备
本地需要有外网访问能力
Mac电脑:
brew install python@3.11
pip3.11 install llama-index
pip3.11 install openai
(2)入门案例
https://docs.llamaindex.ai/en/stable/getting_started/starter_example.html
# -*- coding: utf-8 -*-
import openai
import logging
import sys
import os.path
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
ServiceContext,
)
# 设置ChatGpt大模型的访问API的key
openai.api_key = ''
# 使用日志记录查看查询和事件
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# 检查存储是否存在
PERSIST_DIR = "./storagel"
if not os.path.exists(PERSIST_DIR):
# 加载数据并建立索引
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(
documents
)
# 存储您的索引(默认情况下,这会将数据保存到目录中storage,但您可以通过传递persist_dir参数来更改它)
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# 加载存在的索引
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
# 查询索引
query_engine = index.as_query_engine(similarity_top_k=1)
response = query_engine.query("鲁迅的真名叫什么?")
print(response)
(3)定制案例:设置文档解析块大小
from llama_index import ServiceContext
service_context = ServiceContext.from_defaults(chunk_size=1000)
(4)定制案例:自定义数据连接器
- 作用:
将来自不同数据源和数据格式的数据提取为简单的Document表示形式(文本和简单元数据) - 支持的数据连接器:
https://docs.llamaindex.ai/en/stable/module_guides/loading/connector/root.html - 网页数据获取:
from llama_index import SummaryIndex
from llama_index.readers import SimpleWebPageReader
from IPython.display import Markdown, display
import os
import openai
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
openai.api_key = ''
documents = SimpleWebPageReader(html_to_text=True).load_data(
["http://paulgraham.com/worked.html"]
)
documents[0]
index = SummaryIndex.from_documents(documents)
# set Logging to DEBUG for more detailed outputs
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
(5)定制案例:自定义节点解析器
- 参考文档:
https://docs.llamaindex.ai/en/stable/module_guides/loading/node_parsers/modules.html
# -*- coding: utf-8 -*-
import logging
import sys
import os
# 使用日志记录查看查询和事件
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from llama_index.text_splitter import SentenceSplitter
from llama_index import SimpleDirectoryReader
# load documents
documents = SimpleDirectoryReader(input_files=["./datalawsuit/test.txt"]).load_data()
# 句子分割器
splitter1 = SentenceSplitter(
# 对输入文本序列进行切分的最大长度
chunk_size=256,
# 相邻两个chunk之间的重叠数量
chunk_overlap 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











