



0.1. 实验2 使用随机搜索法训练线性分类器
0.1.1. 读取图像形式的MNIST,划分为train/test
0.1.2. 定义Linear Classifier+Cross Entroy Loss
0.1.3. 用Random Search 来训练Linear Classifier
0.1.4. 在上述分类器前再增加一层(2层神经网络)使用Relu激活函数
0.1.5. 通过表格、曲线等形式进行汇总,分析比较是否使用激活函数、激活函数的类型对分类结果的影响
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from numpy.ma.extras import unique
'''
根据名称整出来训练集、测试集和对应的标签
'''
def load_images_and_split(folder):
train_images = []
test_images = []
test_labels = []
train_labels = []
for filename in os.listdir(folder):
if filename.endswith('.jpg'):
img_path = os.path.join(folder, filename)
try:
img = Image.open(img_path)
img_array = np.array(img)
#图像名称的倒数第五个是标签
label = filename[-5]
#划分数据集
if 'test' in filename:
test_images.append(img_array)
try:
# 将标签转换为整数
test_labels.append(int(label))
except ValueError:
print(f"Invalid label in {filename}: {label}. Skipping this image.")
elif 'training' in filename:
train_images.append(img_array)
try:
train_labels.append(int(label))
except ValueError:
print(f"Invalid label in {filename}: {label}. Skipping this image.")
except Exception as e:
print(f"Error loading {img_path}: {e}")
train_images = np.array(train_images)
test_images = np.array(test_images)
train_labels = np.array(train_labels)
test_labels = np.array(test_labels)
return train_images, train_labels, test_images, test_labels
# image_folder = 'mnist_jpg/mnist_jpg'
image_folder = "E:/Strudy/Data/nearestk/mnist_jpg/mnist_jpg"
#这里改成自己的名称,因为老师要求再jupyter上跑所以我就写了绝对路径
train_images, test_images,train_labels,test_labels = load_images_and_split(image_folder)
print(f"训练集数量: {len(train_images)}")
print(f"测试集数量: {len(test_images)}")
print(unique(test_labels))
第一步的运行结果:

'''
绘图
'''
#这里有三个参数,title是绘制图像的名称,同志们抄的时候注意一下把title换一下,好吗
def drawing(x,y,title):
plt.plot(x,y)
plt.title(title)
plt.show()
'''
数据预处理
'''
def preprocess_data(train_images, test_images):
# 展平图片数据
train_images_flat = train_images.reshape(train_images.shape[0], -1)
test_images_flat = test_images.reshape(test_images.shape[0], -1)
# 归一化处理
train_images_normalized = train_images_flat / 255.0
test_images_normalized = test_images_flat / 255.0
return train_images_normalized, test_images_normalized
'''
onehot编码方便交叉熵损失计算
'''
def one_hot_encode(labels, num_classes):
one_hot = np.zeros((labels.shape[0], num_classes))
one_hot[np.arange(labels.shape[0]), labels] = 1
return one_hot
'''
softmax
注意softmax是激活函数,在完成最后一个任务的时候是需要修改softmax函数的
'''
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=1, keepdims=True))
return exp_x / np.sum(exp_x, axis=1, keepdims=True)
'''
交叉熵
'''
def cross_entropy_loss(y_true, y_pred):
epsilon = 1e-15
y_pred = np.clip(y_pred, epsilon, 1 - epsilon)
loss = -np.mean(np.sum(y_true * np.log(y_pred), axis=1))
return loss
'''
单层模型评估
'''
def evaluate_model(test_images, test_labels, weights, bias,x_row):
logits = np.dot(test_images, weights) + bias
y_pred = softmax(logits)
predicted_labels = np.argmax(y_pred, axis=1)
accuracy = np.mean(predicted_labels == test_labels)
print(f'Accuracy on the test set: {accuracy * 100}%')
return accuracy
'''
单层线性分类器,最后使用的softmax激活
同志们注意一下,这里我的迭代方式是同时满足准确率上升和损失下降,同志们写作业的时候可以尝试修改一下迭代的条件,因为我最后做出来的结果不太好,我个人猜测是:如果要两个条件同时满足,我的迭代次数太少了,随意导致准确率不高
此外,在画图过程时候,可以更改一下传入y_rate和y_loss这两个,因为我传入的都是最好的,最后会生成一个单调函数,如果传入不是best_loss就是一个震荡上升的曲线,同志们可以尝试一下!
'''
def train_linear_classifier_random_search(test_images_normalized, test_labels,train_images, train_labels, num_classes, num_trials=100):
input_size = train_images.shape[1]
best_loss = float('inf')
best_weights = None
best_bias = None
acc=0
x_row = []
y_loss_row=[]
y_rate_row=[]
for trial in range(num_trials):
# 随机生成权重和偏置
x_row.append(trial)
weights = np.random.randn(input_size, num_classes) * 0.01
bias = np.zeros((1, num_classes))
# 前向传播
logits = np.dot(train_images, weights) + bias
y_pred = softmax(logits)
# 计算损失
y_true = one_hot_encode(train_labels, num_classes)
loss = cross_entropy_loss(y_true, y_pred)
# acc = evaluate_model(test_images_normalized, test_labels, best_weights, best_bias, x_row)
# 更新最佳参数
if loss < best_loss:
if evaluate_model(test_images_normalized, test_labels, weights, bias, x_row)>acc:
#如果当前的准确率高于最佳准确率则更新参数
best_loss = loss
best_weights = weights
best_bias = bias
#发现准确率下降了,在更新参数的时候加上准确率的迭代
y_loss_row.append(best_loss)
acc=evaluate_model(test_images_normalized, test_labels, best_weights, best_bias, x_row)
y_rate_row.append(acc)
print(f'Trial {trial + 1}, Loss: {loss}')
drawing(x_row, y_loss_row,title='single_loss_curve')
#使用best图表好看一点
drawing(x_row,y_rate_row,title='single_acc_curve')
return best_weights, best_bias
'''
the main func of test2
主函数,在这里修改超参数也是可以的
'''
folder_path = image_folder
train_images, train_labels, test_images, test_labels = load_images_and_split(folder_path)
train_images_normalized, test_images_normalized = preprocess_data(train_images, test_images)
num_classes = len(np.unique(train_labels))
weights, bias = train_linear_classifier_random_search(test_images_normalized, test_labels,train_images_normalized, train_labels, num_classes)
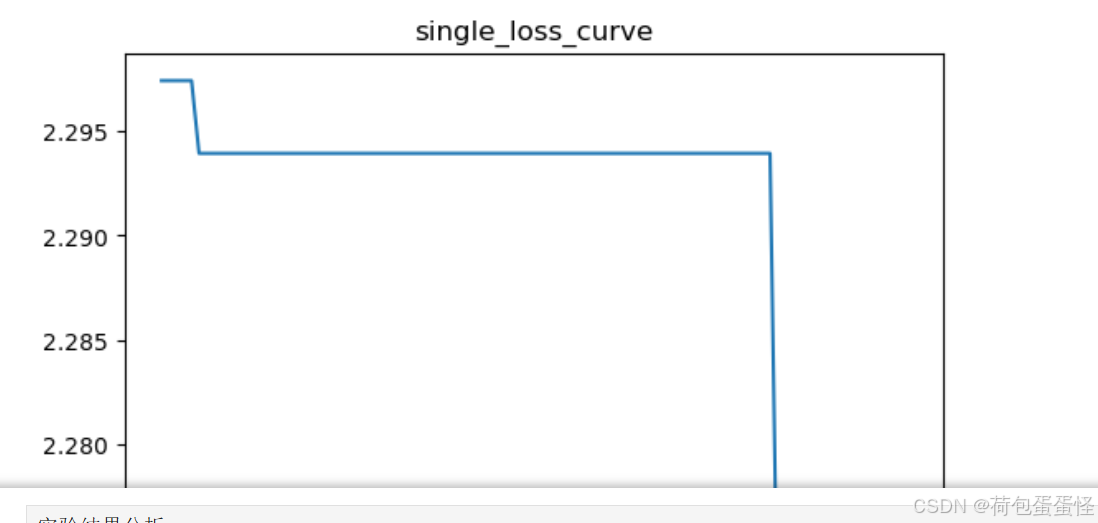

up太笨了,琢磨不出来怎么截屏完整的图像出来……
'''
两层模型评估
其实两层模型的评估和一层模型的写法评估大差不差,但是要注意一下矩阵的运算
'''
# test_images_normalized, test_labels, best_weights1, best_bias1,best_weights2,best_bias2, x_row)
def two_evaluate_model(test_images, test_labels, weights1, bias1,weights2,bias2,x_row):
#隐藏
hidden_layer=np.dot(test_images,weights1)+bias1
hidden_layer=relu(hidden_layer)
logits = np.dot(hidden_layer, weights2) + bias2
y_pred = softmax(logits)
predicted_labels = np.argmax(y_pred, axis=1)
accuracy = np.mean(predicted_labels == test_labels)
print(f'Accuracy on the test set: {accuracy * 100}%')
return accuracy
'''
relu函数
这玩意也是一个激活函数哦~最后一步也是可以修改的的
'''
def relu(x):
return np.maximum(0, x)
'''
两层线性分类器
'''
def two_train_linear_classifier_random_search(test_images_normalized, test_labels,train_images, train_labels, num_classes, num_trials=100):
input_size = train_images.shape[1]
best_loss = float('inf')
best_weights1 = None
best_bias1 = None
best_weights2 = None
best_bias2 = None
acc=0
x_row = []
y_loss_row=[]
y_rate_row=[]
for trial in range(num_trials):
# 随机生成权重和偏置
x_row.append(trial)
#初始化第一层
weights1 = np.random.randn(input_size, num_classes) * 0.01
bias1 = np.zeros((1, num_classes))
# 初始化第二层
weights2 = np.random.randn(num_classes, num_classes) * 0.01
bias2 = np.zeros((1, num_classes))
# 前向传播
hidden_layer = np.dot(train_images, weights1) + bias1
hidden_layer = relu(hidden_layer)
logits = np.dot(hidden_layer,weights2)+bias2
y_pred=softmax(logits)
# 计算损失
y_true = one_hot_encode(train_labels, num_classes)
loss = cross_entropy_loss(y_true, y_pred)
# 更新最佳参数,大家看好,这里是迭代条件哈,这里是可以修改的,如果谁能想到更聪明的迭代方法,麻烦教教我
if loss < best_loss:
if two_evaluate_model(test_images_normalized, test_labels, weights1, bias1,weights2,bias2, x_row)>acc:
best_loss = loss
best_weights1 = weights1
best_bias1 = bias1
best_weights2 = weights2
best_bias2 = bias2
y_loss_row.append(best_loss)
#我想要的只是递增图像~~~
acc=two_evaluate_model(test_images_normalized, test_labels, best_weights1, best_bias1,best_weights2,best_bias2, x_row)
y_rate_row.append(acc)
print(f'Trial {trial + 1}, Loss: {loss}')
drawing(x_row, y_loss_row,title='double_loss_curve')
drawing(x_row,y_rate_row,title='double_acc_curve')
return best_weights1, best_bias1,best_weights2, best_bias2
#这里是主函数了
two_train_linear_classifier_random_search(test_images_normalized, test_labels,train_images_normalized, train_labels, num_classes)
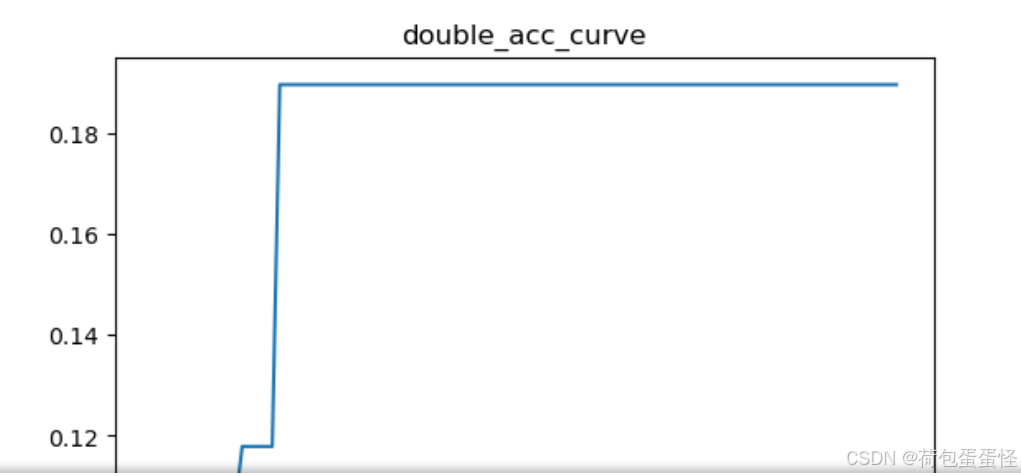
'''
0.1.5. 通过表格、曲线等形式进行汇总,分析比较是否使用激活函数、激活函数的类型对分类结果的影响。'''
'''
这个就是不实用激活函数了,自行丢尽刚刚的代码里修改一下就好了
def no_activate_func(x):
return x
'''
'''
这里举个例子
'''
def two_train_linear_without_activatefunc(test_images_normalized, test_labels,train_images, train_labels, num_classes, num_trials=100):
input_size = train_images.shape[1]
best_loss = float('inf')
best_weights1 = None
best_bias1 = None
best_weights2 = None
best_bias2 = None
acc=0
x_row = []
y_loss_row=[]
y_rate_row=[]
for trial in range(num_trials):
# 随机生成权重和偏置
x_row.append(trial)
#初始化第一层
weights1 = np.random.randn(input_size, num_classes) * 0.01
bias1 = np.zeros((1, num_classes))
# 初始化第二层
weights2 = np.random.randn(num_classes, num_classes) * 0.01
bias2 = np.zeros((1, num_classes))
# 前向传播
hidden_layer = np.dot(train_images, weights1) + bias1
hidden_layer = no_activate_func(hidden_layer)
logits = np.dot(hidden_layer,weights2)+bias2
y_pred=no_activate_func(logits)
# 计算损失
y_true = one_hot_encode(train_labels, num_classes)
loss = cross_entropy_loss(y_true, y_pred)
# 更新最佳参数
if loss < best_loss:
if two_evaluate_model(test_images_normalized, test_labels, weights1, bias1,weights2,bias2, x_row)>acc:
best_loss = loss
best_weights1 = weights1
best_bias1 = bias1
best_weights2 = weights2
best_bias2 = bias2
y_loss_row.append(best_loss)
#我想要的只是递增图像~~~
acc=two_evaluate_model(test_images_normalized, test_labels, best_weights1, best_bias1,best_weights2,best_bias2, x_row)
y_rate_row.append(acc)
print(f'Trial {trial + 1}, Loss: {loss}')
drawing(x_row, y_loss_row,title='double_loss_curve')
drawing(x_row,y_rate_row,title='double_acc_curve')
return best_weights1, best_bias1,best_weights2, best_bias2
two_train_linear_without_activatefunc(test_images_normalized, test_labels,train_images_normalized, train_labels, num_classes)
我刚刚写文章的时候想到,在评估函数里面也用到了激活函数,同志们可以在那里也修改一下
'''
sigmoid
'''
import numpy as np
def sigmoid(x):
derta=1/(1+np.exp(-x))
return derta


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









