






 本文深入探讨了机器学习中的过拟合与欠拟合现象,详细解释了两者的定义、常见原因及解决方案。过拟合指模型过分适应训练数据,导致泛化能力差;欠拟合则指模型未能充分学习数据结构,表现为预测性能不佳。文章通过生动的比喻,帮助读者理解这两个概念。
本文深入探讨了机器学习中的过拟合与欠拟合现象,详细解释了两者的定义、常见原因及解决方案。过拟合指模型过分适应训练数据,导致泛化能力差;欠拟合则指模型未能充分学习数据结构,表现为预测性能不佳。文章通过生动的比喻,帮助读者理解这两个概念。
一、过拟合
1. 定义
在统计学中,过拟合(英语:overfitting,或称拟合过度)是指过于紧密或精确地匹配特定数据集,以致于无法良好地拟合其他数据或预测未来的观察结果的现象。[1]过拟合模型指的是相较有限的数据而言,参数过多或者结构过于复杂的统计模型。[2]发生过拟合时,模型的偏差小而方差大。过拟合的本质是训练算法从统计噪声中不自觉获取了信息并表达在了模型结构的参数当中。[3]:45相较用于训练的数据总量来说,一个模型只要结构足够复杂或参数足够多,就总是可以完美地适应数据的。过拟合一般可以视为违反奥卡姆剃刀原则。
注:奥卡姆剃刀原则:“如无必要,勿增实体”
----from wiki
图形上,过拟合如下。
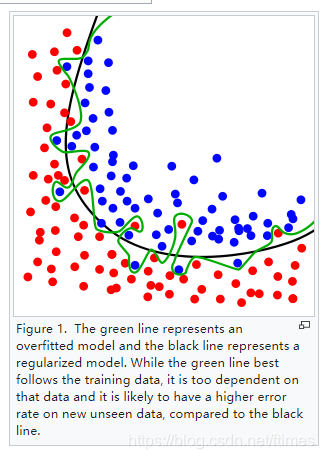
2. 常见原因
(1)建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
(2)样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
(3)假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
(4)参数太多,模型复杂度过高;
(5)对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集。
(6)对于神经网络模型:a)对样本数据可能存在分类决策面不唯一,随着学习的进行,,BP算法使权值可能收敛过于复杂的决策面;b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
3. 解决方案
- 正则化,什么是正则化?点击就送。
- 增加训练集的数据量/数据扩增:
通俗的讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般有以下方法:- 从数据源头采集更多数据
- 复制原有数据并加上随机噪声
- 重采样
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等
- 剪枝处理:
剪枝是决策树类算法防止过拟合的方法。如果决策树的结构过于复杂,可能会导致过拟合问题,此时需要对树进行剪枝,消掉某些节点让它变得更简单。剪枝的关键问题是确定减掉哪些树节点以及减掉它们之后如何进行节点合并。决策树的剪枝算法可以分为两类,分别称为预剪枝和后剪枝。前者在树的训练过程中通过停止分裂对树的规模进行限制;后者先构造出一棵完整的树,然后通过某种规则消除掉部分节点,用叶子节点替代。 - Dropout
Dropout是神经网络中防止过拟合的方法。dropout的做法是在训练时随机的选择一部分神经元进行正向传播和反向传播,另外一些神经元的参数值保持不变,以减轻过拟合。dropout机制使得每个神经元在训练时只用了样本集中的部分样本,这相当于对样本集进行采样,即bagging的做法。最终得到的是多个神经网络的组合。
二、欠拟合
1.定义
欠拟合在wiki上找不到独立词条… 拿英文顶一下。
Underfitting occurs when a statistical model cannot adequately capture the underlying structure of the data. An underfitted model is a model where some parameters or terms that would appear in a correctly specified model are missing.[2] Underfitting would occur, for example, when fitting a linear model to non-linear data. Such a model will tend to have poor predictive performance.
当统计模型不能充分捕获数据的底层结构时,就会发生欠拟合。欠拟合模型是指在正确指定的模型中出现的某些参数或术语丢失的模型。例如,当将线性模型拟合到非线性数据时,会出现欠拟合。这样的模型往往具有较差的预测性能。
欠拟合经典例子:「Pytorch」用二次多项式拟合三次多项式一百万次,看看最后能做到多好?
https://blog.youkuaiyun.com/ftimes/article/details/105152688
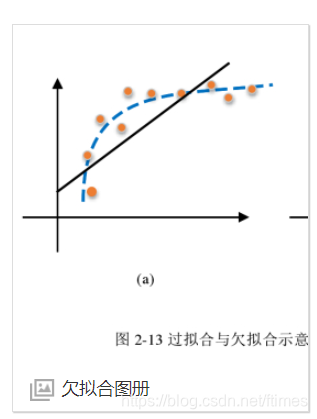
2.常见原因
“欠拟合”常常在模型学习能力较弱,而数据复杂度较高的情况出现,此时模型由于学习能力不足,无法学习到数据集中的“一般规律”,因而导致泛化能力弱。
个人经验,可能是因为模型设计不合理,也可能是因为数据集太少。
3.解决办法
过拟合和欠拟合是所有机器学习算法都要考虑的问题,其中欠拟合的情况比较容易克服, 常见解决方法有:
- 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强;
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数;
- 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力;
- 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging。
----from百度百科
三、大话过拟合欠拟合
简单来说,过拟合就是太过于了解细节,欠拟合就是太不了解。
--------------------------------------分割线---------------------------------------------
【过拟合】
假设我是一个没谈过恋爱的人,
我就约等于一个待训练的模型。
突然有一天,我的朋友对我说:你该学会怎么谈恋爱了。
然后我就谈了一批女孩子,
她们都喜欢喝56°的水。
在8:00到9:00左右睡觉,
在7:00 到 8:00左右起床,
在午夜12:00起夜WC。
谈了一批以后,我以为我学会了如何去爱一个人。
然后我就给心目中的女神告了白。
早上7:00,我兴致勃勃地叫她起床。
她虽然不高兴,但是没有说。
晚上8:00,我让她睡觉。
她看起来似乎有些生气,嘴上却说着:“亲爱的,你生活真健康。”
午夜十二点,我端了一杯56度的水走进了房间;
“亲爱的,起床尿尿了。渴了就喝口水。”
她睡眼朦胧的接过水杯,一下子被烫醒,喷在了我的脸上。
生气地说道:“你有病啊?!拿这么烫的水给我喝?”
我茫然道:“以前谈的一百个女朋友都喜欢喝热水啊,”
第二天,我没了女朋友。
这就是不能过拟合的原因。
【欠拟合】
假设我是一个没谈过恋爱的人,
我就约等于一个待训练的模型。
突然有一天,我的朋友对我说:你该学会怎么谈恋爱了。
然后我就谈了一批女孩子,
女的。
谈了一批以后,我以为我学会了如何去爱一个人。
然后我就给心目中的女神告了白。
“你当我女朋友吧!”
女神娇羞道:“嗨呀,你好直白呀,我哪里好了~”
我:“我喜欢你是个女人,我以前谈了一百个都是女人。”
第二天,我被拉黑了。
这就是不能欠拟合的原因。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









