




对于网络爬虫来说header是很重要的一环,因为有些网站只认可浏览器发送的访问请求。
网上的例子多是Chrome的,Firefox的较少。
第一步:
使用百度打开一个网页
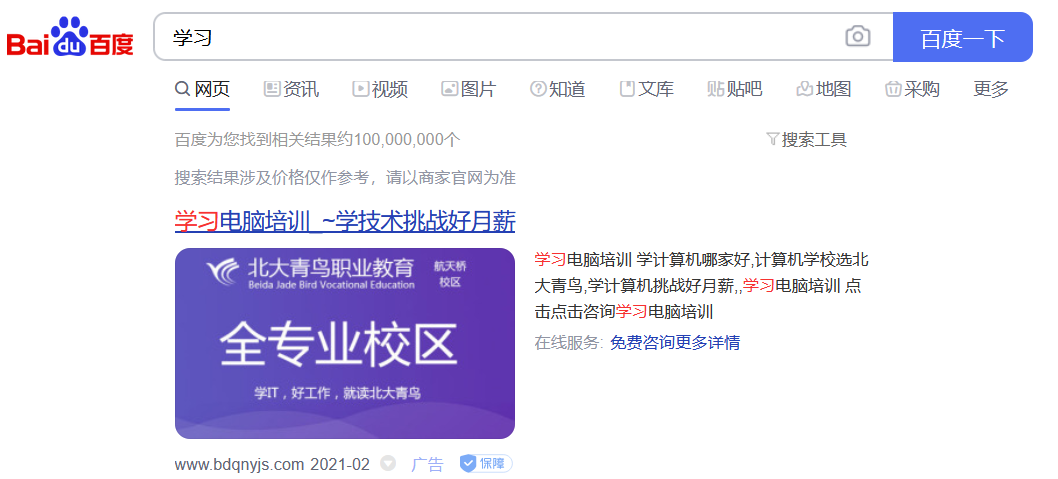
第二步:
按F12进入开发者模式
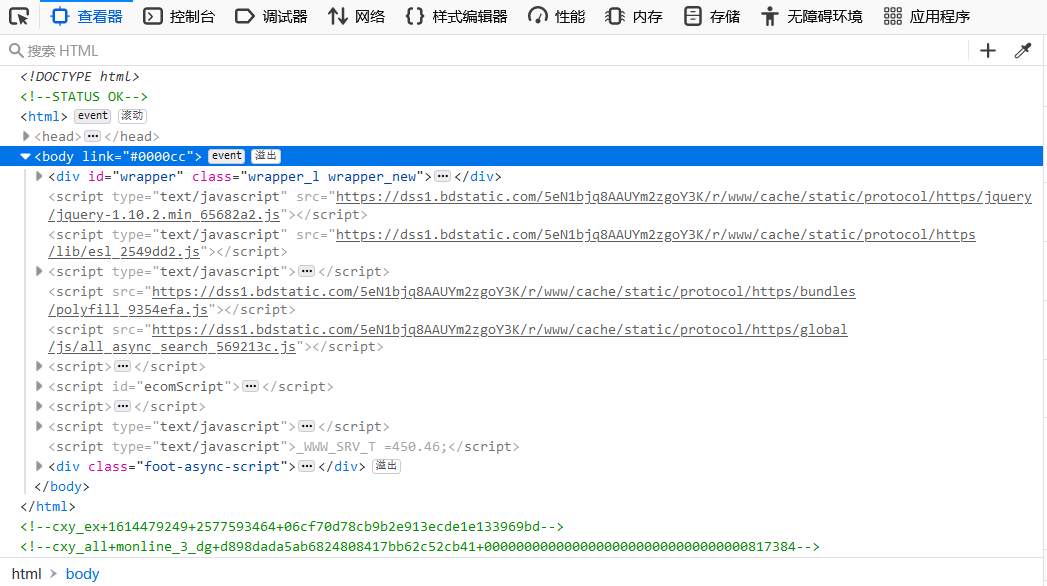
第三步:
选择网络
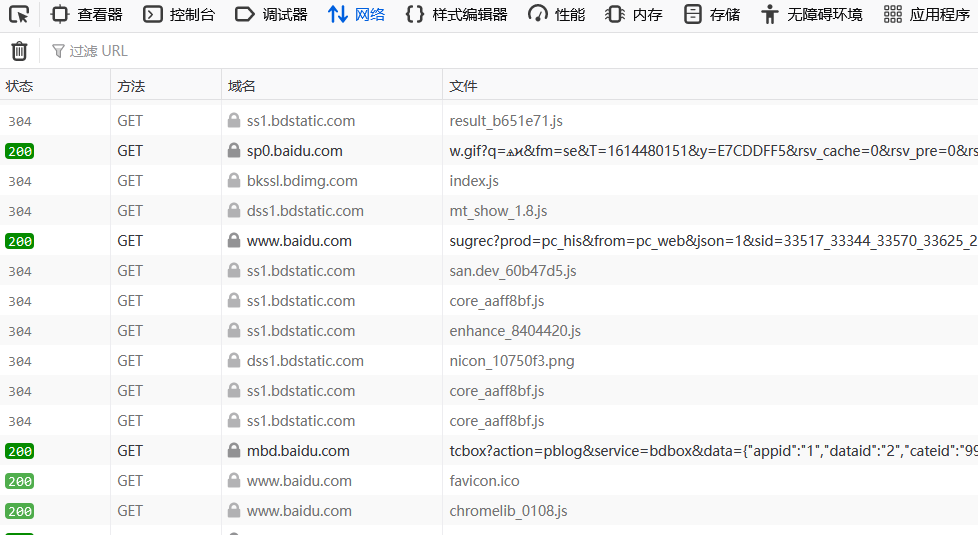
第四步:
点击一项进去
右下角可以看到User-Agent
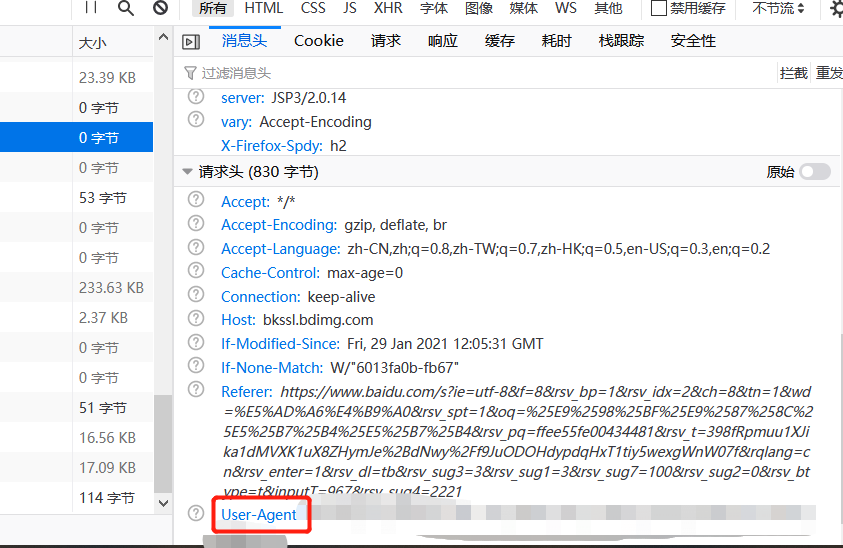
有这个就可以进行接下来的网络爬虫了。
 本文介绍如何通过浏览器获取网页的User-Agent信息,这对于网络爬虫至关重要。文章详细解释了使用Chrome和Firefox等浏览器的开发者工具来查找User-Agent的具体步骤。
本文介绍如何通过浏览器获取网页的User-Agent信息,这对于网络爬虫至关重要。文章详细解释了使用Chrome和Firefox等浏览器的开发者工具来查找User-Agent的具体步骤。
对于网络爬虫来说header是很重要的一环,因为有些网站只认可浏览器发送的访问请求。
网上的例子多是Chrome的,Firefox的较少。
第一步:
使用百度打开一个网页
第二步:
按F12进入开发者模式
第三步:
选择网络
第四步:
点击一项进去
右下角可以看到User-Agent
有这个就可以进行接下来的网络爬虫了。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1869
1869





