



 本文介绍了如何使用C++调用微软的Text-to-Speech(TTS)技术,通过安装微软语音平台SDK、Runtime和Language Packs,然后在VS中创建C++项目,设置头文件,初始化,并创建文本框和Slider控件来控制语速,实现文字的有声阅读功能。
本文介绍了如何使用C++调用微软的Text-to-Speech(TTS)技术,通过安装微软语音平台SDK、Runtime和Language Packs,然后在VS中创建C++项目,设置头文件,初始化,并创建文本框和Slider控件来控制语速,实现文字的有声阅读功能。
首先安装微软语音平台,它包括了软件开发包SDK(MicrosoftSpeechPlatformSDK),运行时Runtime(Microsoft Server Speech Platform Runtime),以及各种语言包Language Packs,例如MSSpeech_TTS_zh-CN_HuiHui,以上涉及的三个安装包,下载地址。
依次安装完成后,VS新建C++项目,头文件包含
#include <sphelper.h>
#pragma comment(lib,"sapi.lib")
初始化,界面上创建一个文本框,添加cstring变量m_Edit1,用于输入文字;
一个Slider控件,对应变量m_sliderc,用于调整语速。
pVoice = NULL; //初始化COM
if (FAILED(CoInitialize(NULL)))
{
mvcErr = true;
}
//初始化SAPI 界面上
HRESULT hr = CoCreateInstance(CLSID_SpVoice, NULL, CLSCTX_ALL, IID_ISpVoice, (void **)&pVoice);
ISpObjectToken * pSpObjectToken = NULL;
WCHAR* pReqAttr = NULL;
pReqAttr = L"language=804";
if (SUCCEEDED(SpFindBestToken(SPCAT_VOICES, pReqAttr, NULL, &pSpObjectToken)))//804代表中文 409英文
{
pVoice->SetVoice(pSpObjectToken);
pVoice->SetRate(m_sliderc.GetPos());//语速 -5~5
pVoice->Speak(m_Edit1, 0, NULL);
pSpObjectToken->Release();
}
else {
mvcErr = true;
}
if (!SUCCEEDED(hr))
{
mvcErr = true;
}
if (mvcErr)
{
m_Msg = _T("没有安装语音SDK");
UpdateData(false);
}
效果如下:
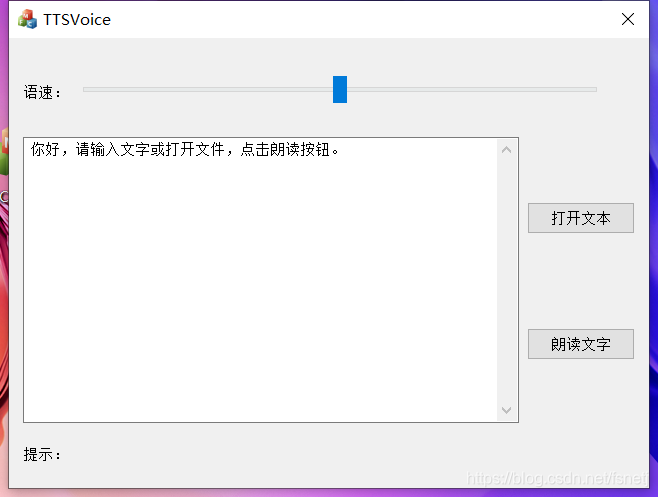
下载完整项目源码。


















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











