







 本文详细介绍了如何在MySQL8.0中部署组复制,包括配置参数、设置用户凭证、启动组复制以及进行容错测试。在部署过程中,强调了网络稳定性对性能的影响,并提供了处理常见问题的解决方案,如成员无法连接和GTID冲突。最后,通过模拟主库宕机,展示了组复制的自动故障切换功能。
本文详细介绍了如何在MySQL8.0中部署组复制,包括配置参数、设置用户凭证、启动组复制以及进行容错测试。在部署过程中,强调了网络稳定性对性能的影响,并提供了处理常见问题的解决方案,如成员无法连接和GTID冲突。最后,通过模拟主库宕机,展示了组复制的自动故障切换功能。
部署组复制时,建议将各个成员分布在不同的物理服务器上以达到容错的功能。但由于组复制成员的状态需要时刻保持同步,组内各成员需要时刻保持双向通信,因此其性能受到网络的延迟和带宽影响很大,建议部署在网络稳定,延迟较低的环境中(例如同一机房)。
目录
一、准备工作
要完成基本组复制的部署(具备容错功能),至少需要3台服务器,这里用3台服务器来演示基本部署步骤。每台服务器上已经完成了MySQL 8.0.13的基础安装,安装步骤:
MySQL 8.0 二进制文件安装_mysql 二进制安装_V1ncent Chen的博客-优快云博客
如果是自己练习可以装1台虚拟机然后直接复制2台出来(记得修改主机名、IP和MySQL数据目录下auto.cnf文件中的MySQL服务器的UUID)。
用于演示的3台服务器如下:
- 192.168.3.71(主机名master,MySQL8.0.13)
- 192.168.3.72(主机名slave01,MySQL8.0.13)
- 192.168.3.73(主机名slave02,MySQL8.0.13)
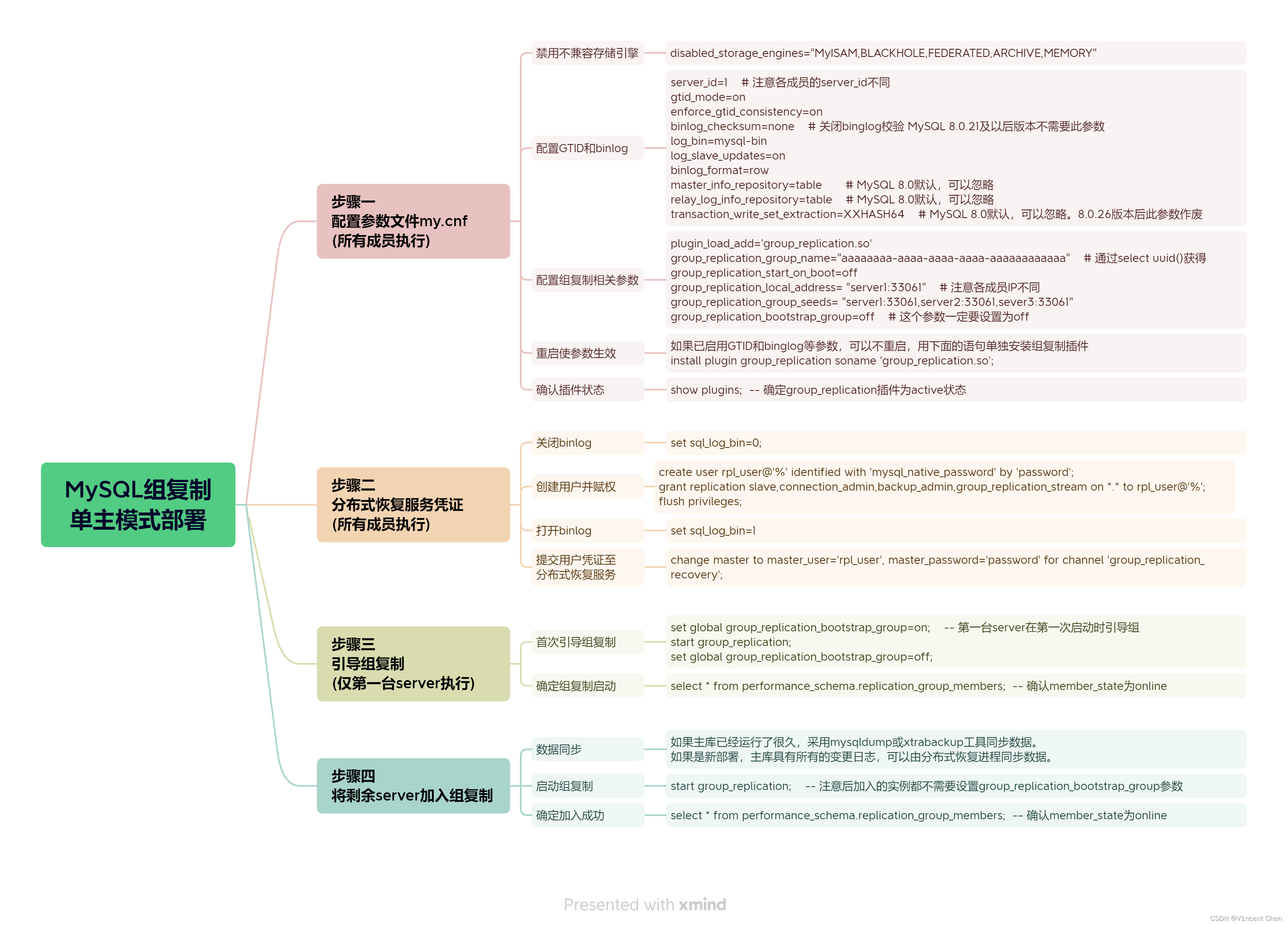
二、组复制部署步骤
组复制可以以单主或多主模式运行,默认是单主模式,这里选取192.168.3.71(主机名master)作为单主读写服务器,其他2台为只读服务器。
2.1 修改参数文件
组复制的事务传递是基于GTID的,且与部分引擎不兼容,因此需要修改相应的参数内容。
修改主库参数,在参数文件[mysqld]模块下新增下列参数(修改前备份旧参数文件):
#----------------Storage_engine----------------
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
#----------------Replication----------------
server_id=71
gtid_mode=on
enforce_gtid_consistency=on
binlog_checksum=none
log_bin=mysql-bin
log_slave_updates=on
binlog_format=row
#----------------Group replication----------------
plugin_load_add='group_replication.so'
group_replication_group_name="29e026d1-b67c-11ed-9421-0800276c19d8"
group_replication_start_on_boot=off
group_replication_local_address= "192.168.3.71:33061"
group_replication_group_seeds= "192.168.3.71:33061, 192.168.3.72:33061, 192.168.3.73:33061"
group_replication_bootstrap_group=off部分参数说明:
- disabled_storage_engines,组复制的数据必须存储在事务型引擎中。在多主模式下,事务冲突监测的机制是乐观型,即先执行事务,再检测冲突。如果有冲突则所有的成员都必须回滚,因此无法执行回滚的非事务型的存储引擎和组复制不兼容,需要禁用。
- Replication部分的参数是配置GTID复制和binlog,参数说明可以见前面GTID配置的文章:
MySQL复制(三):GTID复制(Replication using GTIDs)_V1ncent Chen的博客-优快云博客
- plugin_load_add='group_replication.so',服务器重启的时候加载组复制插件
- group_replication_group_name="UUID()",设置组的UUID,可以事先用select uuid()获取,然后填在这里,所有成员保存相同。
- group_replication_start_on_boot=off,设置成off,在MySQL启动时不会自动启动组复制
- group_replication_local_address= "host1:port" ,设置本地成员的内部通信地址,port与MySQL服务不同,建议设置为33061
- group_replication_group_seeds= "host1:port, host2:port, host3:port" 组复制的成员信息
- group_replication_bootstrap_group=off,设置是否引导组服务(即创建一个组),一定要设置为off,否则每次重启都会引导一个新组出来。
完成上面参数的配置后重启服务器使参数生效,并通过show plugins命令确认组复制插件已安装:
show plugins;![]()
2.2 设置分布式恢复服务的用户凭证
当有新成员加入组复制时,会通过分布式恢复进程(Distributed Recovery Process)来同步数据。分布式恢复进程会先找一个数据的捐赠者(Donor),并通过一个名为group_replication_reocvery的通道将捐赠者binlog中的事务发送给新成员。在这里需要一个授权用户凭证来建立分布式恢复的连接。这个用户在所有的组成员上都必须存在。
在主库执行下列命令创建连接用户:
set sql_log_bin=0;
create user repuser@'%' identified by 'reppassword';
grant replication slave on *.* to repuser@'%';
grant connection_admin on *.* to repuser@'%';
grant backup_admin on *.* to repuser@'%';
flush privileges;
set sql_log_bin=1;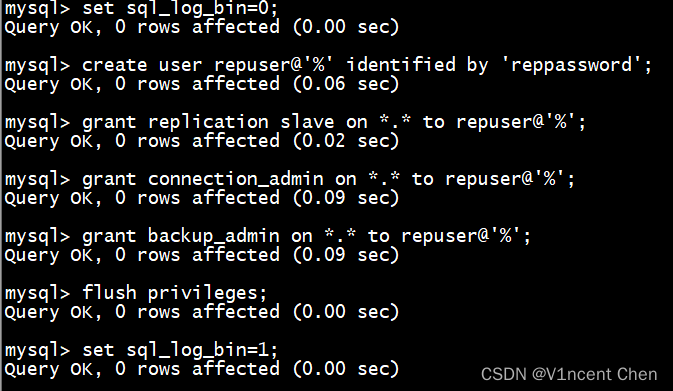
创建好用户后,将用户凭证指定为分布式恢复进程使用:
change master to master_user='repuser', master_password='reppassword' for channel 'group_replication_recovery';
2.3 组复制引导
第一次启动组复制称作引导,引导会创建一个组出来。通过group_replication_bootstrap_group参数来控制引导动作。引导组复制必须由单一服务器完成且只需要执行一次。如果group_replication_bootstrap_group设置为on,则每次重启都会创建出一个同名新组,这也是前面参数中将其设置为off的原因。
执行下列命令引导组复制:
set global group_replication_bootstrap_group=on;
start group_replication;
set global group_replication_bootstrap_group=off;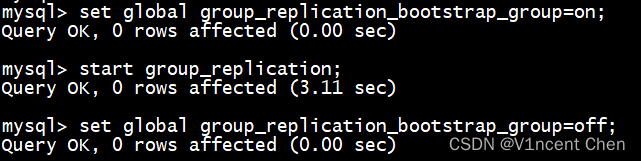
注意只有在第一次启动组复制时,才需要设置group_replication_bootstrap_group,后续成员加入时都不能设置此变量,否则会产生经典的分布式系统问题 --- 脑裂(split brain)。
一旦start group_replication;语句成功返回后,组复制就成功启动了,可以通过performance_schema.replication_group_members确认引导结果:
select * from performance_schema.replication_group_members;
查询结果显示member_state为online,member_role为primary,说明组复制已经引导成功了。
我们在主库运行一些事务:
create database test;
use test;
create table t1(id int auto_increment primary key);
insert into t1 values(null);
insert into t1 values(null);
insert into t1 values(null);
commit;然后查看二进制日志中的内容:
show binlog events in '日志名';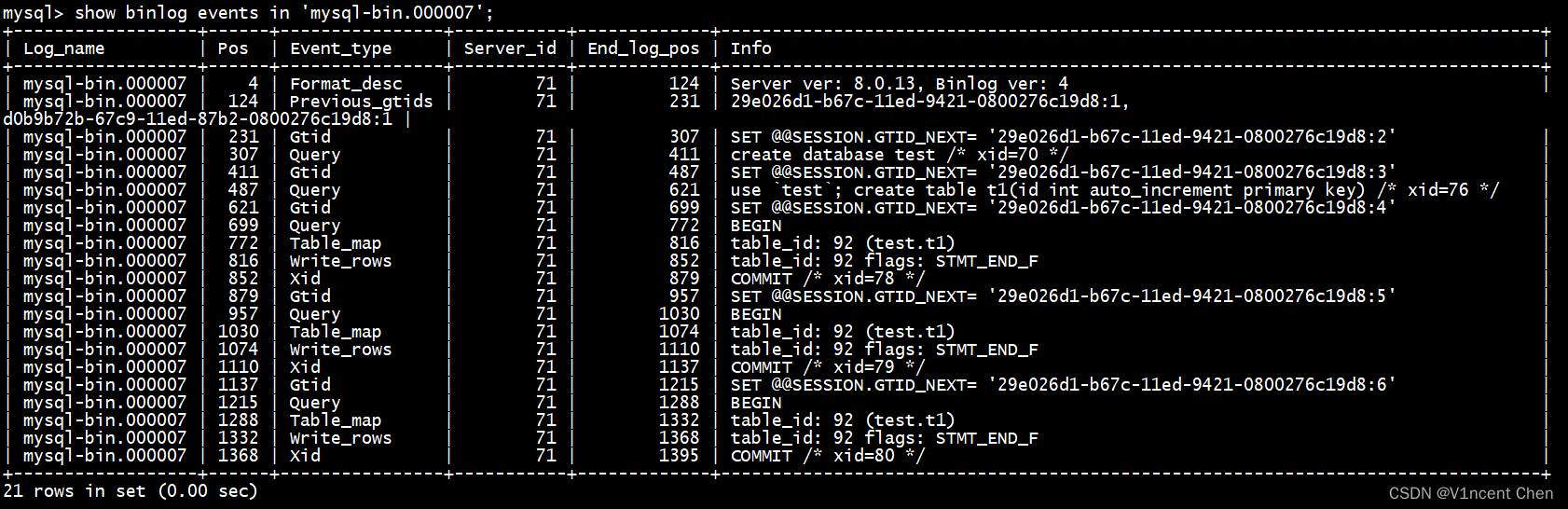
可以看到上面日志已写入二进制日志,此时主库可以作为捐赠者(Donor),可以将这些事务变更同步给后加入的成员。
2.4 将其他成员加入组复制
完成前面三步后,我们已经创建出了一个组,并且其中已有1台主库在运行了,下面需要将另外两个成员也加入组复制。
新成员加入组时会有一个数据恢复的动作,如果加入时组内数据已经很大了,那么这个过程可能会耗费很长时间,并且如果主库purge过二进制日志,那么恢复会失败。此时应使用备份恢复工具(mysqldump/xtrabackup等)将待加入的成员数据状态还原至离主库较近的时间点,以缩短加入后的数据恢复时间。
本次示例中是全新安装的环境,数据变更很少,且主库具有所有变更的日志,可以将新成员直接加入,由分布式恢复进程来同步数据。
加入的方法与前面类似,首先将下列必要的参数加入配置文件并重启生效,注意修改server_id和group_replication_local_address至对应的值,其他参数保存一致。
[mysqld]
#----------------Storage_engine----------------
disabled_storage_engines="MyISAM,BLACKHOLE,FEDERATED,ARCHIVE,MEMORY"
#----------------Replication----------------
server_id=72 # 修改为自己的server_id
gtid_mode=on
enforce_gtid_consistency=on
binlog_checksum=none
log_bin=mysql-bin
log_slave_updates=on
binlog_format=row
#----------------Group replication----------------
plugin_load_add='group_replication.so'
group_replication_group_name="29e026d1-b67c-11ed-9421-0800276c19d8"
group_replication_start_on_boot=off
group_replication_local_address= "192.168.3.72:33061" # 修改为自己的地址
group_replication_group_seeds= "192.168.3.71:33061, 192.168.3.72:33061, 192.168.3.73:33061"
group_replication_bootstrap_group=off然后创建分布式恢复凭证:
set sql_log_bin=0;
create user repuser@'%' identified by 'reppassword';
grant replication slave on *.* to repuser@'%';
grant connection_admin on *.* to repuser@'%';
grant backup_admin on *.* to repuser@'%';
flush privileges;
set sql_log_bin=1;
change master to master_user='repuser', master_password='reppassword' for channel 'group_replication_recovery';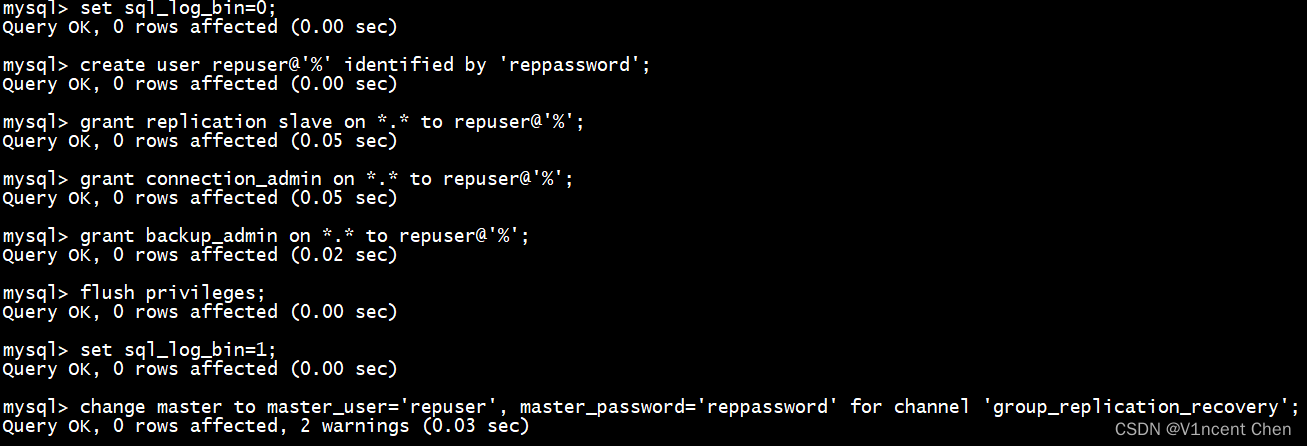
启动组复制,加入组:
start group_replication; # 注意不需要再引导组了
select * from performance_schema.replication_group_members;
此时我们看到第二个成员已经成功加入组复制,成员角色为secondary,状态为online。
用相同的操作步骤将第三个成员加入组,注意其刚加入的状态为recovering,代表其正在同步数据,追赶主库:

待第三名成员的状态也变为online时,组复制的部署即完成:

三、组复制容错测试
3.1 杀死主库
为了测试组复制的容错,在主库上直接杀掉MySQL进程(非正常关闭),模拟服务器宕机。
killall mysqld![]()
3.2 观察角色切换
在原来的从库上查询成员状态(kill命令在两次查询之间执行),注意此时服务器slave01的角色自动从secondary变为primay,表示其被提升为新的主库:
select * from performance_schema.replication_group_members;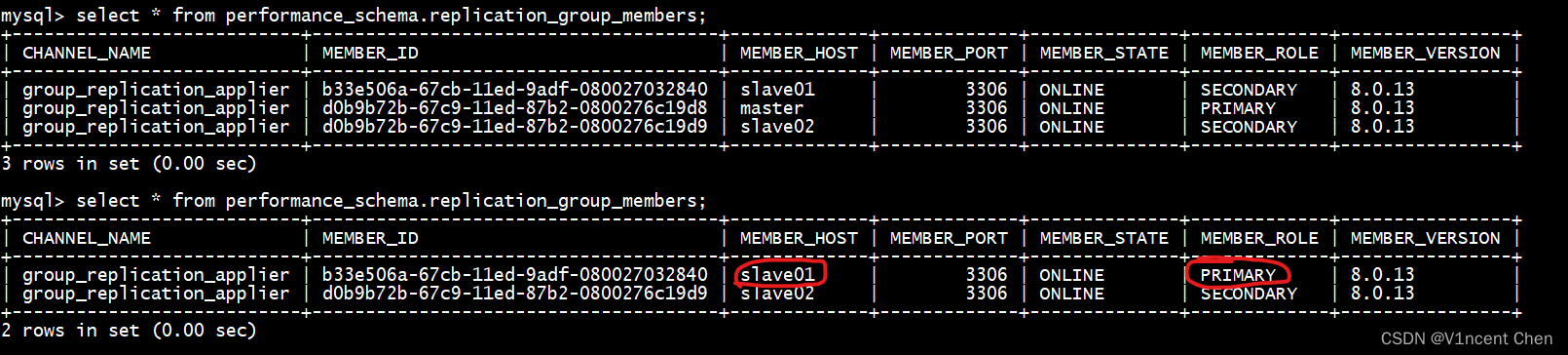
3.3 原主库重新加入组复制
将原主库重新启动,并加入组复制,注意此时宕机的主库将以从库的身份加入组复制(不会自动恢复主库身份),主库依然是上次切换的slave01:
start group_replication;
select * from performance_schema.replication_group_members;
四、部署过程可能遇到的问题
4.1 无法连接其他成员
Error connecting to all peers.

解决方法:
此问题是防火墙导致,关闭防火墙即可。
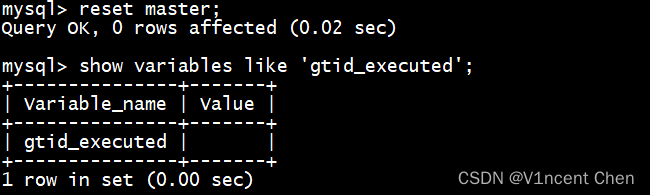
4.2 成员GTID中存额外的事务,无法加入组
This member has more executed transactions than those present in the group.

解决方法:
执行reset master清除gtid_executed中已执行的事务,重新加入即可

















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









