







对于普通数据库用户,使用最多的就是查询语句。大部分业务功能的瓶颈都与SQL性能有关,所以SQL语句的优化是必备的技能,而要优化SQL就必须先搞清楚数据库后台是如何执行SQL,访问数据的。
当用户向数据库提交一个查询SQL后,数据库会将SQL解析为执行计划。这个执行计划就是获取数据的步骤和方法。根据SQL写法的不同,表之间的连接方式可能不同,效率也不同。MySQL中最终的访问数据的方法分为下列几种,我们可以在SQL的执行计划type列看到这些访问方法:
以下的访问方法仅限于MySQL数据库,Oracle数据库的访问方法有所不同。
- const(system)
- eq_ref
- ref
- ref_or_null
- fulltext
- index_merge
- unique_subquery
- index_subquery
- range
- index
- all
下面依次解释各种访问方法:
1. const(system)
常量访问,当通过表的"主键"或"非空唯一索引"进行"常量等值匹配"访问表中数据时,访问类型就是const。此访问类型只会执行一次,查询最多只会查询出1条数据,因此在复杂的SQL中会被优先执行并直接替换为常量,然后再执行SQL的其他部分,以提升效率。
我们创建一张表并插入2条数据,并通过主键id访问数据:
create table const_table(id int primary key, name varchar(32));
insert into const_table values(1,'Vincent'),(2,'Victor');
commit;
explain select * from const_table where id=1;通过执行计划看到访问类型为const:

system的访问方式是const的一种特殊情况,当表中数据只有1条且统计数据是准确的时候,访问类型为system。我们将表中数据只保留1条,引擎改为MyISAM(会存储准确的统计信息),再次观察执行计划,可以看到访问类型即是system。
delete from const_table where id=2;
alter table const_table engine=myisam;
explain select * from const_table where id=1;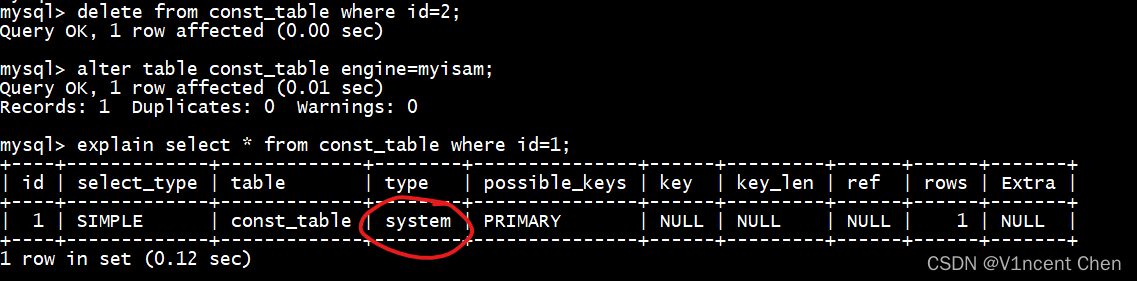
2. eq_ref
等值引用,当表之间通过等值连接(连接条件是=)访问时,且使用"主键"或"非空唯一索引"访问被驱动表时,访问类型即是eq_ref,这是效率最高的连接访问方式。
create table employees
(id int primary key,
name varchar(32));
create table jobs
(id int primary key, -- 主键
uk int, -- 唯一索引
idx int, -- 非唯一索引
job varchar(32),
unique key(uk),
key(idx)
)
insert into employees values(1,'Vincent'),(2,'Victor'),(3,'Grace');
insert into jobs values(1,1,1,'DBA'),(2,2,2,'Student'),(3,3,3,'Manager');我们创建2张表,分别插入3条数据,我们通过主键连接查询,观察执行计划,由于连接条件是通过主键等值匹配,因此访问方法为eq_ref。
explain
select jobs.* from employees,jobs
where employees.id=jobs.id
and employees.id in(1,2);
3. ref
普通引用,当表之间同过等值(连接条件是=或<=>)访问时,使用普通索引(未使用"主键"或"非空唯一索引")访问被驱动表时,访问类型即是ref,这是效率比较高的连接访问方式。
我们在eq_ref的演示SQL上,将连接条件中jobs.id替换为jobs.idx,虽然2个字段中值一样,但是jobs.idx上的是普通二级索引。
explain
select jobs.* from employees,jobs
where employees.id=jobs.idx
and employees.id in(1,2);

注意这里的访问类型变成了ref而不是上个示例中的eq_ref,因为idx上的索引为非唯一索引(无法通过索引获取唯一记录)。
4.ref_or_null
这种访问方式和ref类似,只是MySQL在判断连接值时会额外做一步判断连接条件上的值是否包含null。这种连接类型大部分是在处理子查询的场景中使用:
explain
select * from employees
where employees.id in (select idx from jobs where jobs.idx=3 or jobs.idx is null);
示例子查询的条件是jobs.idx=3 or jobs.idx is null,因此连接中的type类型变成了ref_or_null。
5. fulltext
全文索引访问,全文索引是一种特殊的索引类型,只能建立在char,varchar或text类型的数据上,用来在大量的文本中匹配某种模式(大文本比like匹配快很多)。全文索引使用下面的语法进行查询,共3种检索方式,这里不详细叙述。
MATCH (col1,col2,...) AGAINST (expr [search_modifier])
6. index_merge
索引合并,MySQL通过对同一个表中的多个索引进行范围扫描(range),再将各个扫描结果集合计,得到最终结果集。注意参与索引合并的索引必须来自同一个表,不能跨表。此访问方法在同时使用多个索引时常用。
由于示例表太小,容易走全表扫描,另外找了一张数据较多的表做演示,在cor_crm_loan表中,loan_id为主键,credit_id和cust_id各有一个二级索引,当以这些列作为组合查询条件时,访问类型显示为index_merge,代表使用了索引合并方法。
explain
select * from cor_crm_loan where loan_id=602 or cust_id=682;
注意Extra列中的using union,代表使用的是index_merge的union合并算法。index_merge的算法有3种算法:
- index_merge intersection
- index_merge union
- index_merge sort-union
index_merge intersection 算法取多个索引范围扫描交集,在多个索引条件使用 and 连接时使用。
index_merge union 算法是取多个范围扫描并集,在多个索引条件使用 or 连接时使用。
index_merge sort-union 算法和union类似,唯一的区别是sort-union算法要先取回所有的结果后排序,再将结果返回给客户端。
index_merge intersection示例(注意extra列中的 using intersect):
explain
select * from cor_crm_loan where credit_id=31324 and cust_id=600;

index_merge sort-union示例(注意extra列中的 using sort_union):
explain
select * from cor_crm_loan where credit_id < 31324 or cust_id < 600;
7.unique_subquery
唯一子查询,在某些子查询场景替换eq_ref访问方法。
value IN (SELECT primary_key FROM single_table WHERE some_expr)
8.index_subquery
和unique_subquery类似,某些场景替换in子查询,只是在查询中使用的是非唯一索引。
value IN (SELECT key_column FROM single_table WHERE some_expr)
9.range
索引范围扫描,根据搜索条件扫描一个范围区间的索引,此访问方法非常常见,在where条件中使用=, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN() 这些操作符均会使用索引范围扫描。
range示例(我们在条件中使用了 < 扫描一个区间):

10.index
索引全扫描,和全表扫描(ALL)类似,只是这个扫描的是整个索引树。一般在两种场景下会使用此访问方法:
1. 索引覆盖,即索引中包含了 select 域中需要的所有信息,此时只需要扫描索引就可以满足查询,不再需要回表操作。
2.全表扫描时,需要按某个索引排序。
索引覆盖场景示例:
我们在select中只查询了索引列,MySQL只需要进行索引全扫描就可以返回结果,不会进行回表操作,注意extra列中的 using index,代表使用了索引覆盖:
explain
select credit_id from cor_crm_loan;
全表扫描场景示例:
我们在普通查询后面加了一个order by,要求按主键降序排列,此时也会使用索引全扫描来消除实际的排序动作(索引是预先排好序的数据结构)。
explain
select * from cor_crm_loan order by loan_id desc;

11. all
人人都熟悉的全表扫描,大部分情况下是效率最低的访问方法(当表中数据较少时,全表扫扫描性能也可能优于索引,因为索引大部分是二次访问,随机读取,全表扫描是顺序读取)。特别当表中数据量较大时,使用全表扫描往往会消耗大量系统资源,严重时导致系统挂起。
全表扫描示例,将上个示例中order by子句去掉,即是全表扫描。
explain
select * from cor_crm_loan;
以上即是MySQL中数据主要的访问方法,了解各种方法的使用场景,可以帮助我们快速定位SQL性能瓶颈,写出更高效的SQL。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









