 Python中的进程与线程:概念、实现与进程池
Python中的进程与线程:概念、实现与进程池




简介
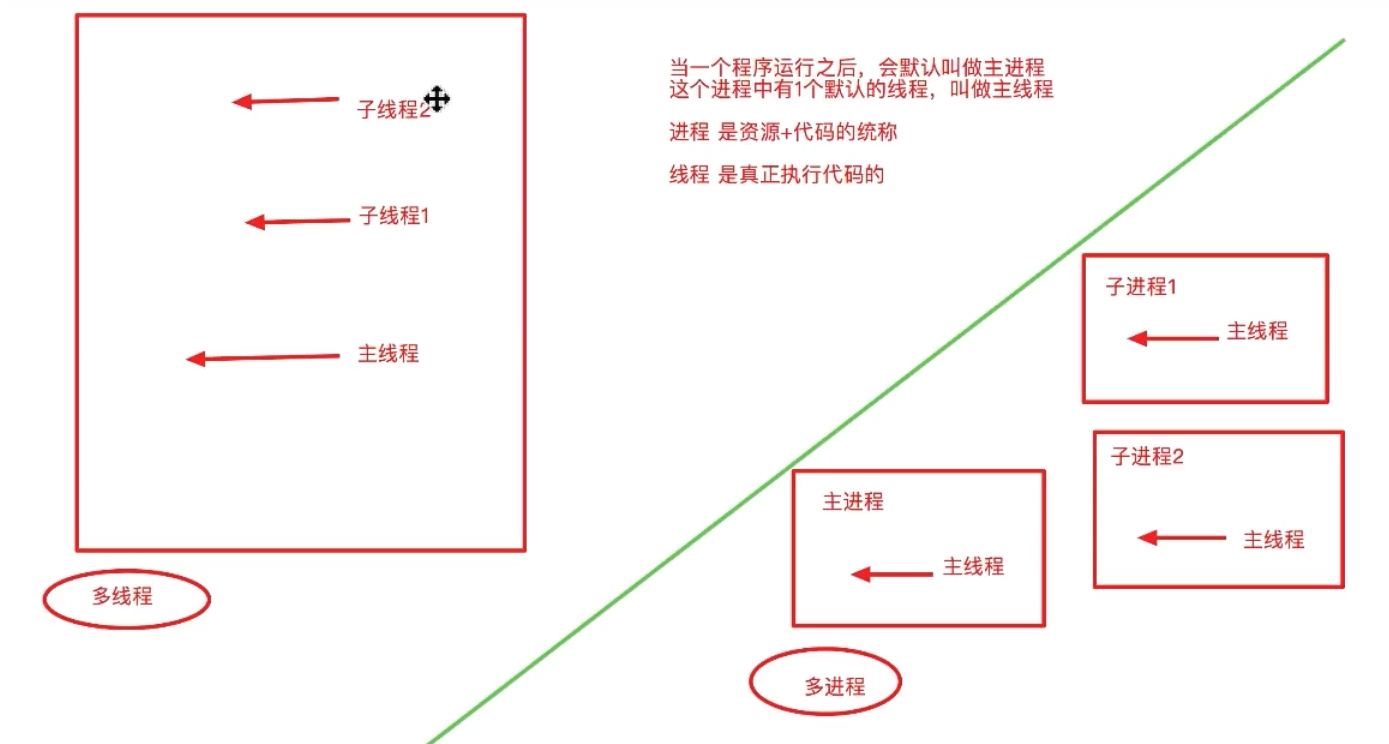
在windows中,启动一个程序+资源等于一个进程,进程是由多个线程组成的,进程理解为管理层,而线程是工人
通俗解释:
- 进程:能够完成多任务,比如,在同一台电脑上能够同时运行多个QQ
- 线程:能够完成多任务,比如,一个qq中的多个聊天窗口
进程与线程:
定义不同
- 进程是系统进行资源分配和调度的一个独立单位
- 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源
区别
- 一个程序至少有一个进程,一个进程至少有一个线程
- 线程的划分尺度小于进程(资源比进程小),使得多线程程序的并发性高
- 进程在执行过程中拥有独立的内存单元,而多个线程共享内存,而从极大地提升了程序的运行效率
- 线程不能独立执行,必须依存于进程中
- 可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线的工人
优缺点
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护,而进程正相反
进程之间不共享全局变量
- 当创建一个子进程的时候,会复制父进程的很多东西(全局变量)
- 子进程和主进程是单独的两个进程,不是一个
- 当一个进程结束的时候,不会对其他的进程产生影响
线程之间共享全局变量 - 所有的线程都在同一个进程中,这个进程是主进程
- 当一个进程结束的时候,不会对其他的进程产生影响
实现方法
无输入输出
from mulitprocessing import Process
import time
def test():
while True:
print("--test--")
time.sleep(1)
class MyProcess(Process):
def run(self):
while True:
print("myprocess")
time.sleep(1)
if __name__ == "__main__":
p = Process(target=test)
p1 = MyProcess()
p.start()
p1.start()
while True:
print("--main--")
time.sleep(1)
有输入无输出
from multiprocessing import Process
import time
def test(*args, **kwargs):
while True:
print(args[0], "->", kwargs['num2'])
time.sleep(1)
class MyProcess(Process):
def __init__(self, num1, num2) -> None:
super().__init__()
self.num1 = num1
self.num2 = num2
def run(self) -> None:
while True:
print(self.num1 + self.num2)
time.sleep(1)
if __name__ == "__main__":
p = Process(target=test, args=(1,), kwargs={'num2':2})
p1 = MyProcess(1, 2)
p.start()
p1.start()
while True:
print("--main--")
time.sleep(1)
有输入有输出
def test(*args, **kwargs):
que = kwargs['que']
for value in ['A', 'B', 'C']:
que.put(value)
class MyProcess(Process):
def __init__(self, que) -> None:
super().__init__()
self.que = que
def run(self) -> None:
while True:
time.sleep(0.5)
if not self.que.empty():
value = self.que.get()
print('Get %s from queue.' % value)
else:
break
def main():
q = Queue()
p = Process(target=test, args=(1,), kwargs={'num2':2, 'que': q})
p1 = MyProcess(q)
p.start()
p1.start()
进程池
限制进程数(创建一个进程和杀死一个进程时间效率较低),重复利用进程,来保证计算机进程的效率
from multiprocessing import Pool
import os
import time
def worker(num):
for i in range(5):
print(f"===pid={os.getpid()}===num={num}=")
time.sleep(1)
def main():
# 3表示进程中最多有3个进程一起执行
pool = Pool(3)
for i in range(10):
print(f'-----{i}-----')
# 向进程池中添加任务
pool.apply_async(worker, args=(i,))
pool.close() # 关闭进程池
pool.join() # 主进程在这里等待,只有子进程全部结束之后,再会开启主进程,同时可以回收进程资源
if __name__ == "__main__":
main()
在Python中,Pool.apply()和Pool.apply_async()都可用于实现子进程的并行处理,但它们之间确实存在一些区别:
阻塞:Pool.apply()将阻塞主进程,直到进程池中的所有任务都完成。而Pool.apply_async()不会阻塞进程,它会立即返回一个AsyncResult对象,并在后台异步执行进程任务。
返回结果:Pool.apply()方法会返回进程的执行结果,因此必须等到子进程执行完再返回结果。而Pool.apply_async()方法不会立即返回结果,但可以立即得到一个AsyncResult对象,并且可以通过调用AsyncResult.get()方法获取对应进程的执行结果。
并行度:Pool.apply()方法是串行处理任务的,但Pool.apply_async()方法可以并行处理多个任务,可以更快的执行一些任务。
因此,如果需要在主进程中等待所有进程任务完成并获取结果,可以使用Pool.apply()。而如果不需要阻塞主进程并且想要更高的并行处理率,建议使用Pool.apply_async()。
from multiprocessing import Pool
import time
def square(num):
time.sleep(1) # 模拟耗时操作
return num * num
if __name__ == '__main__':
nums = [1, 2, 3, 4, 5]
with Pool(processes=4) as pool:
results = []
for num in nums:
result = pool.apply_async(square, args=(num,))
results.append(result)
# 获取结果
for result in results:
print(result.get())
进程池通信
使用Manager中的Pool
from multiprocessing import Manager, Pool
import time
import os
def reader(q):
print(f'reader启动({os.getpid()}), 父进程为({os.getppid()})')
for i in range(q.qsize()):
print(f'reader从Queue获取到消息:{q.get()}')
def write(q):
print(f'wirter启动({os.getpid()}), 父进程为({os.getppid()})')
for i in "itcast":
q.put(i)
if __name__ == "__main__":
print(f"({os.getpid()}) start")
q = Manager().Queue()
po = Pool()
po.apply_async(write, (q,))
time.sleep(1)
po.apply_async(reader, (q,))
po.close()
po.join()
print(f"({os.getpid()}) End")
总结
创建进程方式:
- 直接创建Process对象,用target指定函数,这个函数就是新的进程执行的代码
- 自定义一个类,继承Process,一定要重写run
- 进程池,Pool(3)
区别:1和2默认主进程等待子进程,而3主进程结束后会杀死子进程,使用json等待子进程



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











