







1. BN层的作用
优势:
(1)BN使得网络中每层输入数据的分布相对稳定,加速模型学习速度
(2)BN使得模型对网络中的参数不那么敏感,简化调参过程,使得网络学习更加稳定
(3)BN允许网络使用饱和性激活函数(例如sigmoid,tanh等),缓解梯度消失问题
(4)BN具有一定的正则化效果
劣势:
(1)batch_size较小的时候,效果差
(2)RNN中效果差
(3)测试阶段
训练和测试


2. 空洞卷积
空洞卷积(dilated convolution)是针对图像语义分割问题中下采样会降低图像分辨率、丢失信息而提出的一种卷积思路。利用添加空洞扩大感受野,让原本 3 × 3 3\times 3 3×3的卷积核,在相同参数量的情况下,用于 5 × 5 ( d i l a t e d r a t e = 2 ) 5 \times 5(dilated rate=2) 5×5(dilatedrate=2)或者更大的感受野,无须下采样。
存在问题:
- 局部信息丢失:由于空洞卷积的计算方式类似于棋盘格式,某一层得到的卷积结果,来自上一层的独立的集合,没有相互依赖,因此该层的卷积结果之间没有相关性,即局部信息丢失。
- 远距离获取的信息没有相关性:由于空洞卷积稀疏的采样输入信号,用来获取远距离信息。但是这种信息之间没有相关性,同时当对大物体分割时,会有一定的效果,但是对于小物体来说,有弊无利。
3. 图像插值方法
-
最近邻元法。最近邻像素即为替代像素的方法
-
二次插值法
已知(x1, y1, f (x1, y1)),(x1, y2, f (x1, y2)),(x2, y1, f (x2, y1)),(x2, y2, f (x2, y2))
用双线性插值估计 f(x, y):
先对 x 进行插值去求 f(x,y1) 和 f(x,y2):f ( x , y 1 ) = f ( x 1 , y 1 ) ⋅ x 2 − x x 2 − x 1 + f ( x 2 , y 1 ) ⋅ x − x 1 x 2 − x 1 f\left(x, y_{1}\right)=f\left(x_{1}, y_{1}\right) \cdot \frac{x_{2}-x}{x_{2}-x_{1}}+f\left(x_{2}, y_{1}\right) \cdot \frac{x-x_{1}}{x_{2}-x_{1}} f(x,y1)=f(x1,y1)⋅x2−x1x2−x+f(x2,y1)⋅x2−x1x−x1
f
(
x
,
y
2
)
=
f
(
x
1
,
y
2
)
⋅
x
2
−
x
x
2
−
x
1
+
f
(
x
2
,
y
2
)
⋅
x
−
x
1
x
2
−
x
1
f\left(x, y_{2}\right)=f\left(x_{1}, y_{2}\right) \cdot \frac{x_{2}-x}{x_{2}-x_{1}}+f\left(x_{2}, y_{2}\right) \cdot \frac{x-x_{1}}{x_{2}-x_{1}}
f(x,y2)=f(x1,y2)⋅x2−x1x2−x+f(x2,y2)⋅x2−x1x−x1
然后再去求
f
(
x
,
y
)
f(x, y)
f(x,y) :
f
(
x
,
y
)
=
f
(
x
,
y
1
)
⋅
y
2
−
y
y
2
−
y
1
+
f
(
x
,
y
2
)
⋅
y
−
y
1
y
2
−
y
1
f(x, y)=f\left(x, y_{1}\right) \cdot \frac{y_{2}-y}{y_{2}-y_{1}}+f\left(x, y_{2}\right) \cdot \frac{y-y_{1}}{y_{2}-y_{1}}
f(x,y)=f(x,y1)⋅y2−y1y2−y+f(x,y2)⋅y2−y1y−y1
㓚果
x
2
=
1
,
x
1
=
0
,
y
2
=
1
,
y
1
=
1
x_{2}=1, x_{1}=0, y_{2}=1, y_{1}=1
x2=1,x1=0,y2=1,y1=1, 那么:
f
(
x
,
y
)
=
(
1
−
y
)
⋅
(
1
−
x
)
⋅
f
(
0
,
0
)
+
(
1
−
y
)
⋅
x
⋅
f
(
1
,
0
)
+
y
⋅
(
1
−
x
)
⋅
f
(
0
,
1
)
+
y
⋅
x
⋅
f
(
1
,
1
)
f(x, y)=(1-y) \cdot(1-x) \cdot f(0,0)+(1-y) \cdot x \cdot f(1,0)+y \cdot(1-x) \cdot f(0,1)+y \cdot x \cdot f(1,1)
f(x,y)=(1−y)⋅(1−x)⋅f(0,0)+(1−y)⋅x⋅f(1,0)+y⋅(1−x)⋅f(0,1)+y⋅x⋅f(1,1)
RoI Align 就行用的双线性插值对连续点利用周围的四个点进行双线性插值
4. Focal loss
ohem
smiOTA
α
\alpha
α 平衡了正负样本数量,但实际上,目标检测中大量的候选目标都是易分样本,这些样本会使损失很低,因此模型应关注那些难分样本,将高置信度的样本损失函数降低一些,就有了Focal loss
F
L
=
{
−
α
(
1
−
p
)
γ
l
o
g
(
p
)
i
f
y
=
1
−
(
1
−
α
)
p
γ
l
o
g
(
1
−
p
)
i
f
y
=
0
FL = \left\{\begin{matrix} -\alpha(1-p)^{\gamma} log(p) & if \ y =1\\ -(1-\alpha)p^{\gamma} log(1-p) & if \ y =0 \end{matrix}\right.
FL={−α(1−p)γlog(p)−(1−α)pγlog(1−p)if y=1if y=0
5. 深度可分离卷积和分组卷积
一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map
相比常规的卷积操作,其参数数量和运算成本比较低
常规卷积操作
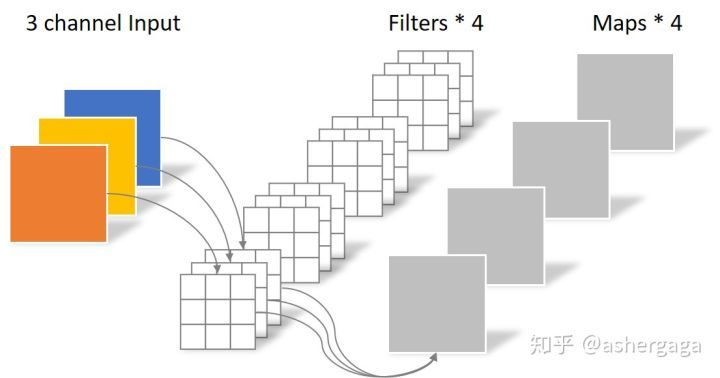
卷积层共4个Filter,每个Filter包含了3个Kernel,每个Kernel的大小为3×3。因此卷积层的参数数量可以用如下公式来计算:
N_std = 4 × 3 × 3 × 3 = 108
深度可分离卷积
- 逐通道卷积
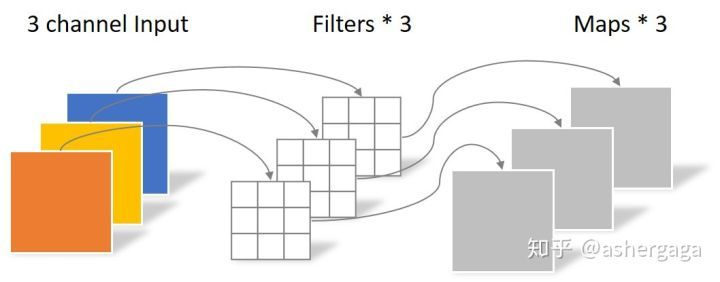
其中一个Filter只包含一个大小为3×3的Kernel,卷积部分的参数个数计算如下:
N_depthwise = 3 × 3 × 3 = 27
- 逐点卷积
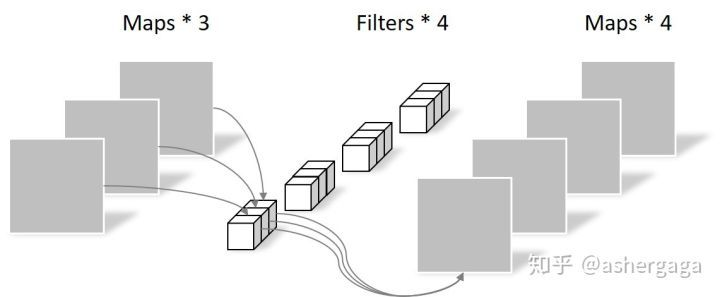
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,同样输出了4张Feature map,与常规卷积的输出维度相同
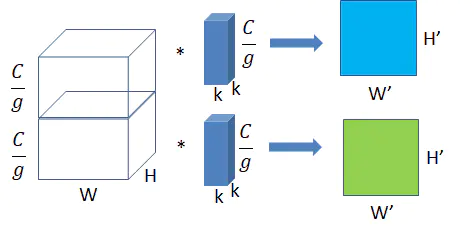
将图一卷积的输入feature map分成组,每个卷积核也相应地分成组,在对应的组内做卷积,如上图2所示,图中分组数,即上面的一组feature map只和上面的一组卷积核做卷积,下面的一组feature map只和下面的一组卷积核做卷积。每组卷积都生成一个feature map,共生成个feature map。
输入每组feature map尺寸: ,共有组;
单个卷积核每组的尺寸:,一个卷积核被分成了组;
输出feature map尺寸:,共生成个feature map。
现在我们再来计算一下分组卷积时的参数量和运算量:
参数量
运算量
6. 为什么说Dropout可以解决过拟合?
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
详细学习链接
7. 知识蒸馏
知识蒸馏指的是将复杂模型(teacher)中的dark knowledge迁移到简单模型(student)中去,一般来说,teacher模型具有强大的能力和表现,而student模型则体量很小。通过知识蒸馏,希望student模型能尽可能逼近亦或是超过teacher模型,从而用更少的复杂度来获得类似的预测效果,实现模型的压缩和量化。
总结来说,知识蒸馏,可以将一个网络的知识转移到另一个网络。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。知识蒸馏,可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
8. 1x1卷积核作用
- 降维/升维
- 增加非线性
- 跨通道信息交互(channal 的变换)
9. add_with_concat
联系
- c o n c a t concat concat 操作时时将通道数增加, a d d add add 是特征图相加,通道数不变。
- 对于 C o n c a t Concat Concat的操作,通道数相同且后面带卷积的话, a d d add add等价于 c o n c a t concat concat之后对应通道共享同一个卷积核。
区别
- 对于 C o n c a t Concat Concat操作而言,通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
- 对于 a d d add add层更像是信息之间的叠加。这里有个先验, a d d add add前后的 t e n s o r tensor tensor语义是相似的。
结论
因此,像是需要将 A A A与 B B B的 T e n s o r Tensor Tensor进行融合,如果它们语义不同,则我们可以使用 C o n c a t Concat Concat的形式,如 U N e t UNet UNet, S e g N e t SegNet SegNet这种编码与解码的结构,主要还是使用 C o n c a t Concat Concat。
而如果 A A A与 B B B是相同语义,如 A A A与 B B B是不同分辨率的特征,其语义是相同的,我们可以使用 a d d add add来进行融合,如 F P N FPN FPN、 R e s N e t ResNet ResNet等网络的设计。
10. CNN
CNN
- 局部连接:不是全连接,而是使用size相对input小的kernel在局部感受视野内进行连接(点积运算)
- 权值共享:在一个卷积核运算中,每次都运算一个感受视野,通过滑动遍历的把整个输入都卷积完成,而不是每移动一次就更换卷积核参数
两者目的都是减少参数。通过局部感受视野,通过卷积操作获取高阶特征,能达到比较好的效果。
池化的意义
1.特征不变形:池化操作是模型更加关注是否存在某些特征而不是特征具体的位置。
2.特征降维:池化相当于在空间范围内做了维度约减,从而使模型可以抽取更加广范围的特征。同时减小了下一层的输入大小,进而减少计算量和参数个数。
3.在一定程度上防止过拟合,更方便优化。
11. 感受野
感受野(
R
e
c
e
p
t
i
v
e
Receptive
Receptive
F
i
e
l
d
Field
Field)的定义是卷积神经网络每一层输出的特征图(
f
e
a
t
u
r
e
feature
feature
m
a
p
map
map)上的像素点在原始输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应原始输入图片上的区域,如下图所示。
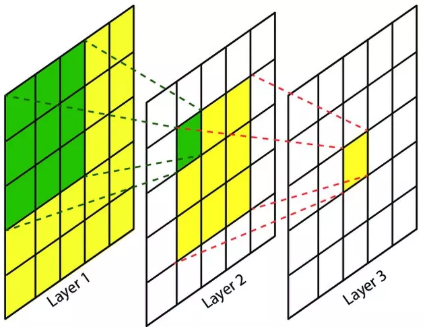
RF = 1 #待计算的feature map上的感受野大小
for layer in (top layer To down layer):
RF = ((RF -1)* stride) + fsize
stride 表示卷积的步长; fsize表示卷积层滤波器的大小
12. 欠拟合和过拟合
解决欠拟合:
- 添加其它特征项。组合、泛化、相关性、上下文特征、平台特征等特征是特征添加的重要手段,有时候特征项不够会导致欠拟合。
- 添加多项式特征。例如将线性模型添加二次项或三次项使泛化能力更强。例如,FM(Factorization Machine)模型、FFM(Field-aware Factorization Machine)模型,其实就是线性模型,增加了二阶多项式,保证了模型一定的拟合程度。
- 可以增加模型的复杂程度。
- 减小正则化系数。正则化的目的就是用来防止过拟合的,但是先模型出现了欠拟合,则需要减少正则化参数。
解决过拟合:
- 重新清洗数据,数据不纯会导致过拟合,此类情况需要重新清洗数据。
- 增加训练样本数量。
- 降低模型复杂程度。
- 增大正则项系数。
- 采用dropout方法,dropout方法,通俗的讲就是在训练的时候让神经元以一定的概率不工作。
- early stopping,减少迭代次数。
- 增大学习率。
- 添加噪声数据。数据增强。
- 树结构中,可以对树进行剪枝。
- 减少特征项。
13. 优化器
- 非自适应优化器
GD、BGD、SGD、SGDM - 自适应优化器
Adagrad、Adadelta、RMSprop、Adam
14. 神经网络模型不收敛
原因
-
忘记对你的数据进行归一化
-
忘记检查输出结果
-
没有对数据进行预处理
-
没有使用任何的正则化方法
-
使用了一个太大的 batch size
-
使用一个错误的学习率
-
在最后一层使用错误的激活函数
-
网络包含坏的梯度
-
网络权重没有正确的初始化
-
使用了一个太深的神经网络
-
隐藏层神经元数量设置不正确
对应的解决办法分别是:
-
对数据进行归一化,常用的归一化包括零均值归一化和线性函数归一化方法;
-
检测训练过程中每个阶段的数据结果,如果是图像数据可以考虑使用可视化的方法;
-
对数据进行预处理,包括做一些简单的转换;
-
采用正则化方法,比如 L2 正则,或者 dropout;
-
在训练的时候,找到一个可以容忍的最小的 batch 大小。可以让 GPU 并行使用最优的 batch 大小并不一定可以得到最好的准确率,因为更大的 batch 可能需要训练更多时间才能达到相同的准确率。所以大胆的从一个很小的 batch 大小开始训练,比如 16,8,甚至是 1。
-
不采用梯度裁剪。找出在训练过程中不会导致误差爆炸的最大学习率。将学习率设置为比这个低一个数量级,这可能是非常接近最佳学习率。
-
如果是在做回归任务,大部分情况下是不需要在最后一层使用任何激活函数;如果是分类任务,一般最后一层是用 sigmoid 激活函数;
-
如果你发现你的训练误差没有随着迭代次数的增加而变化,那么很可能就是出现了因为是 ReLU 激活函数导致的神经元死亡的情况。可以尝试使用如 leaky ReLU 或者 ELUs 等激活函数,看看是否还出现这种情况。
-
目前比较常用而且在任何情况下效果都不错的初始化方式包括了“he”,“xaiver”和“lecun”。所以可以任意选择其中一种,但是可以先进行实验来找到最适合你的任务的权值初始化方式。
-
从256到1024个隐藏神经元数量开始。然后,看看其他研究人员在相似应用上使用的数字
15. 权重初始化方法
- 初始化为常数
- 均值初始化
- 正态函数初始化
- Aavier初始化:尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于 0 0 0
- 何凯明初始化
16. 网络模型训练技巧
17. 时序建模模块
RNN、LSTM…
18. 激活函数
- sigmoid
- tanh
- relu
- leakrelu、prelu、elu、selu、gelu
- mish、swish
19. AUC和ROC
总样本中,90%是正样本,10%是负样本。我们知道用准确率是有水分的,但是用TPR和FPR不一样。这里,TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系,所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。
AUC-随机抽取一个阳性样本和一个阴性样本,分类器正确判断阳性样本的值高于阴性样本的概率 = AUC 。
AUC表示的是正例排在负例前面的概率。
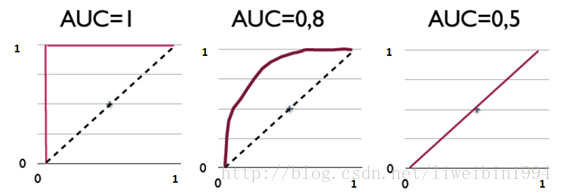 比如上图,第一个坐标系的AUC值表示,所有的正例都排在负例的前面。第二个AUC值,表示有百分之八十的正例排在负例的前面。
比如上图,第一个坐标系的AUC值表示,所有的正例都排在负例的前面。第二个AUC值,表示有百分之八十的正例排在负例的前面。
学习混淆矩阵和Accuracy、Precision、Recall、F1 score、AP、mAP、IoU、mIoU、真阳率、假阳率
https://zhuanlan.zhihu.com/p/46714763
https://www.zhihu.com/question/39840928
https://blog.youkuaiyun.com/liweibin1994/article/details/79462554
20. L1和L2
- L 1 L1 L1正则化项是模型各个参数的绝对值之和。 L 2 L2 L2正则化项是模型各个参数的平方和的开方值。
- L 1 L1 L1正则化可以使部分权重为 0 0 0,产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择;一定程度上, L 1 L1 L1也可以防止过拟合,当 L 1 L1 L1的正则化系数很小时,得到的最优解会很小,可以达到和 L 2 L2 L2正则化类似的效果。
- L 2 L2 L2正则化通过权重衰减,可以使所有的权重趋向于 0 0 0,但不为 0 0 0,导致模型权重参数较小且较为平滑,防止模型过拟合( o v e r f i t t i n g overfitting overfitting);
- L 2 L2 L2正则化的效果是对原最优解的每个元素进行不同比例的放缩; L 1 L1 L1正则化则会使原最优解的元素产生不同量的偏移,并使某些元素为 0 0 0,从而产生稀疏性。
21. 标签平滑- l a b e l label label s m o o t h i n g smoothing smoothing
标签平滑采用如下思路:在训练时即假设标签可能存在错误,避免“过分”相信训练样本的标签。当目标函数为交叉熵时,这一思想有非常简单的实现,称为标签平滑(
L
a
b
e
l
Label
Label
S
m
o
o
t
h
i
n
g
Smoothing
Smoothing)。
没有标签平滑计算的损失只考虑正确标签位置的损失,而不考虑其他标签位置的损失, 这就会出现一个问题,即不考虑其他错误标签位置的损失,这会使得模型过于关注增大预测正确标签的概率,而不关注减少预测错误标签的概率,最后导致的结果是模型在自己的训练集上拟合效果非常良好,而在其他的测试集结果表现不好,即过拟合,也就是说模型泛化能力差。
平滑过后的样本交叉熵损失就不仅考虑到了训练样本中正确的标签位置( o n e one one- h o t hot hot 标签为 1 1 1 的位置)的损失,也稍微考虑到其他错误标签位置( o n e one one- h o t hot hot 标签为 0 0 0 的位置)的损失,导致最后的损失增大,导致模型的学习能力提高,即要下降到原来的损失,就得学习的更好,也就是迫使模型往增大正确分类概率并且同时减小错误分类概率的方向前进。
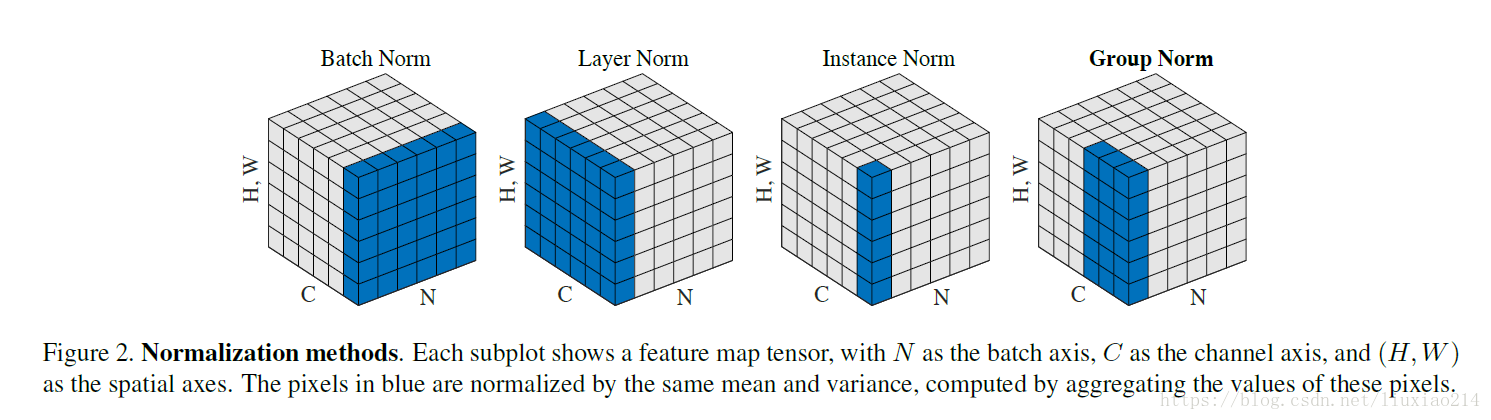
22. BN,LN,IN,GN, SN
batchNorm是在batch上,对NHW做归一化,对小batchsize效果不好;
layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
GroupNorm将channel分组,然后再做归一化;
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
详细学习链接
23. FPN为何能够提升小目标的精度
低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。原来多数的object detection算法都是只采用顶层特征做预测。FPN同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的。所以可以提升小目标的准确率。
24. Softmax与sigmoid计算公式
y
(
x
i
)
=
1
1
+
e
−
x
i
y(x_i) = \frac{1}{1+e^{-x_i}}
y(xi)=1+e−xi1
y
(
x
i
)
=
e
x
i
∑
j
=
1
j
=
k
e
x
j
y(x_i) = \frac {e^{x_i}}{\sum_{j=1}^{j=k}e^{x_j}}
y(xi)=∑j=1j=kexjexi
详细学习链接
详细学习链接
25. 为什么分类问题的损失函数采用交叉熵而不是均方误差MSE?
- 交叉熵计算量更小一点,mse需要计算每一个类别。
- 以sigmoid为例(softmax也是一样,可以看做是sigmoid的多维推广),MSE反向传播的时候需要计算sigmoid梯度,会发生梯度弥散,交叉熵会消掉 梯度这项 (y-z)*x 误差越大,更新值越大,比较合理。
26. 为什么使用ROC和AUC评价分类器?
因为ROC曲线有很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。再实际数据中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本可能随着时间变化。
27. CNN的平移不变性的理解
简单地说,卷积+最大池化约等于平移不变性。
卷积:简单地说,图像经过平移,相应的特征图上的表达也是平移的。
池化:比如最大池化,它返回感受野中的最大值,如果最大值被移动了,但是仍然在这个感受野中,那么池化层也仍然会输出相同的最大值。
所以这两种操作共同提供了一些平移不变性,即使图像被平移,卷积保证仍然能检测到它的特征,池化则尽可能地保持一致的表达。
28. 提升小目标?
- 提高图像采集的分辨率
- 增加模型的输入分辨率
- tile你的图像
- 通过增强生成更多数据
- 自动学习模型anchors
- 过滤掉无关的类别
- FPN
- SFPN
- 注意力机制
- 增加检测头
- PANet
29. Smooth-L1 loss相比L1 loss和L2 loss的优势在哪里?这些loss 的公式
总结
对于大多数CNN网络,我们一般是使用L2-loss而不是L1-loss,因为L2-loss的收敛速度要比L1-loss要快得多。
对于边框预测回归问题,通常也可以选择方损失函数(L2损失),但L2范数的缺点是当存在离群点(outliers)的时候,这些点会占loss的主要组成部分。比如说真实值为1,预测10次,有一次预测值为1000,其余次的预测值为1左右,显然loss值主要由1000决定。所以FastRCNN采用稍微缓和一点绝对损失函数(smooth L1损失),它是随着误差线性增长,而不是方增长。
Smooth L1 和 L1 Loss 函数的区别在于,L1 Loss 在0点处导数不唯一,可能影响收敛。Smooth L1的解决办法是在 0 点附使用方函数使得它更加*滑。
Smooth L1的优点
相比于L1损失函数,可以收敛得更快。
相比于L2损失函数,对离群点、异常值不敏感,梯度变化相对更小,训练时不容易跑飞。
详细学习链接
30. 常用的分类损失和常用的回归损失
常见的回归损失函数有:
- 平方损失 (squared loss)
- 绝对值 (absolute loss)
- Huber损失 (huber loss)
分类问题的损失函数:
- 0-1损失 (zero-one loss)
- Logistic loss
- Hinge loss
- 指数损失
- modified Huber loss
31. 对IOU loss了解嘛?(CIOU,DIOU,GIOU)
L2损失能有效的衡量数据间的差异,数据差异越大损失越大,损失差异越小损失越小,但鲁棒性较差,受异常数据影响较大。并且在训练初期,损失会比较大,训练难度高。
L1损失的鲁棒性较好,损失较为稳定,但在训练后期,很能收敛到稳定值,且在0处的导数值不存在。
smoothL1能够融合了L2和L1损失各自的优点,趋利避害,能够实现较好的训练效果。但在目标检测中,并不是无关联的点进行损失计算这么简单,还要考虑边框之间的位置,距离等信息。smoothL1无法表达边框更高层次的信息。
IoU Loss能够去判断能够很好的计算边框之间的位置信息损失,解决了smoothL1的无边框损失的漏洞,但IoU无法去判断两个边框之间的距离信息,比如在两个边框无交集时,IoU无法判断边框之间的真正的距离信息。
GIoU Loss加入了外接边框边框信息,实现了无交集边框的距离计算,但在边框包含关系中退化为IoU loss,无法有效判断边框位置。
在认真审视了边框要素包括重叠面积,中心点距离,长宽比三方面后,DIoU Loss通过增加中心点距离和外界边框关系,改善了中心点距离和边框距离关系。
在DIoU Loss 基础上,CIoU Loss增加了长宽比信息,进一步满足了边框之间的信息要求,实现了训练回归框更快更好的Loss
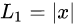
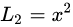
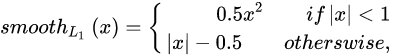

IoU优点:
- 能够更好的反应重合程度
- 具有尺度不变性
缺点:
- 当不相交时loss为0

c表示最小外接矩形面积
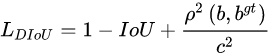
欧式距离
c两边框对角线距离
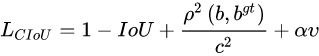
v是用来衡量长宽比一致性的参数
α是用于做trade-off的参数
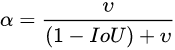
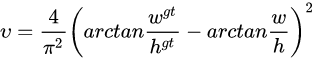
32. RCNN – Faster RCNN
33. YOLO系列对比
YOLOv1 将图像划分为sxs个网络,每个cell负责预测物体中心落在该网格中的Object。
每个网格预测b个bounding box,每个bounding box包含x,y,w,h和confidence信息
loss包括位置损失、置信度损失、类别损失三类,损失函数均为MSE
位置损失中提到
w
\sqrt{w}
w
整个网络较为简单,通过卷积提取到7x7x1024的feature map,然后2个全连接输出7x7x30的结果,当然,这是在VOC数据集,图像被划分为7x7份,每个网格对应2个位置信息(x,y,w,h,confidence)+20个类别信息
YOLOv2相比YOLOv1有较大的改进:
- BN层
- 更高分辨率的分类器
- anchor-base(kmeans聚类)(类别预测与边界框相关)
- 多尺度训练
- 直接位置预测
- 更细粒的特征(passthrogh)
- DarkNet19(3x3替代了7x7)
YOLOv3相比于YOLOv2改进:
- DarkNet53(residual)
- Neck部分提供了FPN结构(concate)
- Head 部分提供了多层特征图预测结果,3x(13*13+2626+5252)
- 类别预测(Class Prediction)(使用sigmoid代替了softmax,可实现多类别检测)
- 边界框预测和代价函数计算(边界框置信度分数通过逻辑回归的sigmoid函数,正负样本类别判断方法变化,每个GT只能有一个正样本边框,IoU>0.5后的其他预测框忽略,IoU<0.5为负样本)
- anchor bbox prior不同:v2作者用了5个anchor,一个折衷的选择,所以v3用了9个anchor,提高了IOU。
YOLOv4比YOLOv3提升:
- CSPDarkNet53
- Neck(SPP(1x1、5x5、9x9、13x13)、PANet)
- 数据增强mosaic
- 边界框回归损失CIoU loss,极大值抑制DIoU-NMS
- 使用了MISH激活函数
- DropBlock
- 交叉小批量归一化 (CmBN)
- 边界框预测sigmoid函数进行了调整,增加了样本的数量
YOLOv5相比YOLOv4提升:
- 自适应锚框计算
- Focus结构
- Neck中也使用了CSP结构
- 边界框回归损失使用GIoU loss
- 加权nms
- YOLOv4采用了较多的数据增强方法,而yolov5使用了3中数据增强:缩放、色彩空间调整与Mosaic数据增强。
- yolov5采用的激活函数包括leakyReLU和Sigmoid,yolov5的中间隐藏层使用的是leakyReLU激活函数,最后的检测层使用的是Sigmoid激活函数。而yolov4使用的是mish与leakyReLU激活函数,主干网络使用的mish。mish激活函数的复杂度较高
- yolov5提供了两个优化函数Adam与SGD,并且都预设了与之匹配的训练超参数,默认使用SGD。而yolov4采用SGD优化函数。
yolox:
- Decoupled Head解耦头,分别预测分类和回归的结果
- Data Aug,数据增强,相比于Yolov3-spp,mosaic+mixup
- Anchor Free。
Anchor Free 的好处是全方位的。1). Anchor Based 检测器为了追求最优性能通常会需要对anchor box 进行聚类分析,这无形间增加了算法工程师的时间成本; 2). Anchor 增加了检测头的复杂度以及生成结果的数量,将大量检测结果从NPU搬运到CPU上对于某些边缘设备是无法容忍的。当然还有; 3). Anchor Free 的解码代码逻辑更简单,可读性更高。 - 多平台部署
详细学习链接
deeplab
deeplabv1为解决pooling 下采样时造成的信息丢失和空间不变性问题提出空洞卷积和全连接条件随机场(CRF,deeplabv3不使用),也提出了MSc,前五层使用,参数量较大,提升不大,不建议使用
deeplabv2同样提出了v1的问题,并且增加了对多尺度目标问题的解决。通过减少下采样的使用和空洞卷积改善下采样问题,优化了CRF方法,提出ASPP网络解决多尺度问题。
deeplabv3替换了backbond,resnet主干特征提取网络,改进了ASPP结构(1个1x1,3个3x3,1个全局pooling),引入了Mulit-grid结构(重复了3次resnet最后一个网络的三次操作),也就是串行链接和并行链接两种结构,一般是使用了并行链接,去除了CRF后处理。
34. yolo比RetinaNet的优势SSD
35. 了解anchor-free?
YOLOV1
学习链接
36. anchor-based 和anchor-free区别
anchor-based典型代表是Faster Rcnn、YOLOV2、YOLOV3等,这种是基于先验的候选框尺寸进行预测目标位置,(候选框的基本尺寸通过kmeans聚类得到)。而anchor-free是未使用先验候选框参数,让候选框根据目标自动学习大小变换,典型的YOLOV1,CornerNet、DenseBox等。
学习链接
学习链接
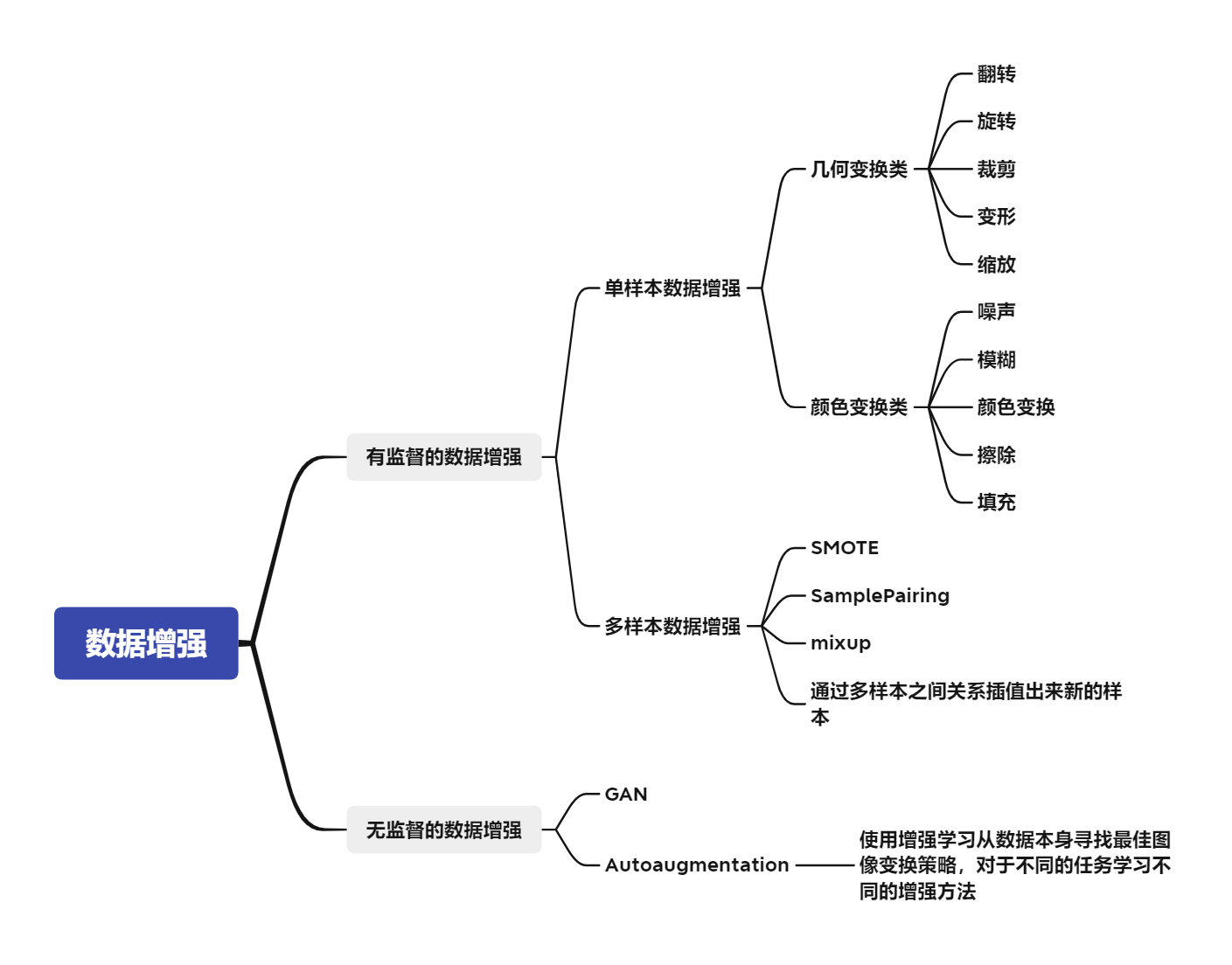
37. 数据增强
数据增强可以分为,有监督的数据增强和无监督的数据增强方法。其中有监督的数据增强又可以分为单样本数据增强和多样本数据增强方法,无监督的数据增强分为生成新的数据和学习增强策略两个方向。
详细学习链接
38. mosaic增强
将4张图像拼接起来!
- 增强数据的多样性
- 增加目标个数
- BN能一次性统计多张图片的参数
39. kmeans聚类先验候选框
1 在所有的bboxes中随机挑选k个作为簇的中心。
2 计算每个bboxes离每个簇的距离1-IOU(bboxes, anchors)
3 计算每个bboxes距离最近的簇中心,并分配到离它最近的簇中
4 根据每个簇中的bboxes重新计算簇中心,这里默认使用的是计算中值,自己也可以改成其他方法
5 重复3到4直到每个簇中元素不在发生变化
40. 梯度消失和梯度爆炸及解决方案
梯度消失和梯度爆炸产生的主要原因有:一是使用了深层网络,二是采用了不合适的损失函数。
解决方案:
(1)pre-training + fine-tunning
(2)Relu、leaky Relu…
(3)BN
(4)残差网络
(5)LSTM的门结构
梯度爆炸附加:
(6)重新设计网络模型
(7)梯度阶段
(8)权重正则化
41 提高网络泛化能力的方法
- 使用更多的数据集
- 使用更大批次
- 调整数据分布
- 调整目标函数
- 调整网络结构
- 数据增强
- 权值正则化
- Dropout
42 RNN梯度消失问题
总梯度被近距离主导,远距离梯度消失或者被忽略不计
43 RNN和Transformer差别
- RNN在两个点距离较远的关系通过长距离传输送达,而Transformer直接q,k即可获得
- RNN无法实现并行化训练,而Transformer可以实现并行化训练
44 Transformer使用多头注意力机制
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息。可以考虑想卷积的通道数,获取不同的信息关注度。
45 Transformer为什么Q和K使用不同的权重矩阵生成,为什么不能使用同一个值进行自身的点乘?
使用Q/K/V不相同可以保证不同空间的投影,增强表达能力,提高了泛化能力。
46 transformer计算attention的时候为什么选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
为了计算更快。矩阵加法计算量简单,但是作为整体计算attention的时候,计算量量和点乘相似。
47 为什么在进行softmax之间需要对attention进行scaled(除以dk的平方根)
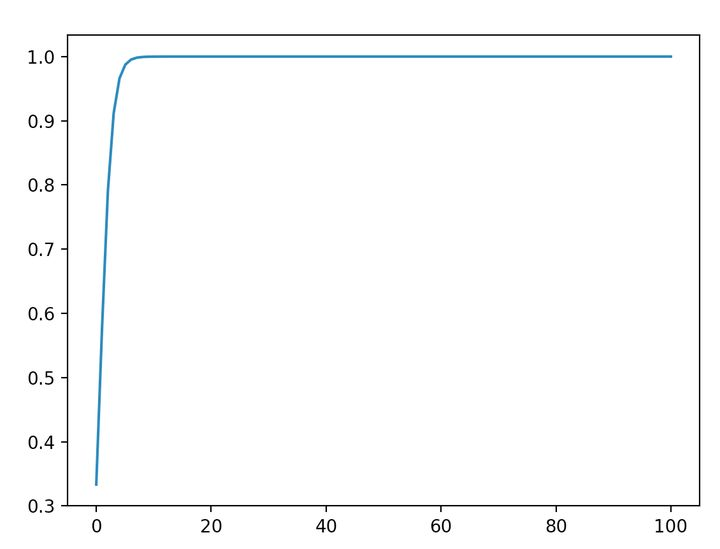
可以看到,数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。
48 计算attention score的时候如何对padding做mask操作
padding位置位置置为负无穷(一般来说-1000就可以),softmax计算时, e x e^x ex中x趋近于负无穷为0
49 CNN和RNN区别?
相同点
- 传统神经网络的扩展
- 前向计算产生结果,反向计算模型更新
- 每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接
不同点
- CNN空间扩展,神经元与特征卷积,RNN时间扩展,神经元与多个时间输出计算
- RNN可以用于描述时间上连续状态的输出,有记忆功能,CNN用于静态输出
- RNN全局模型参数共享(U,W,V),CNN神经元内卷积共享
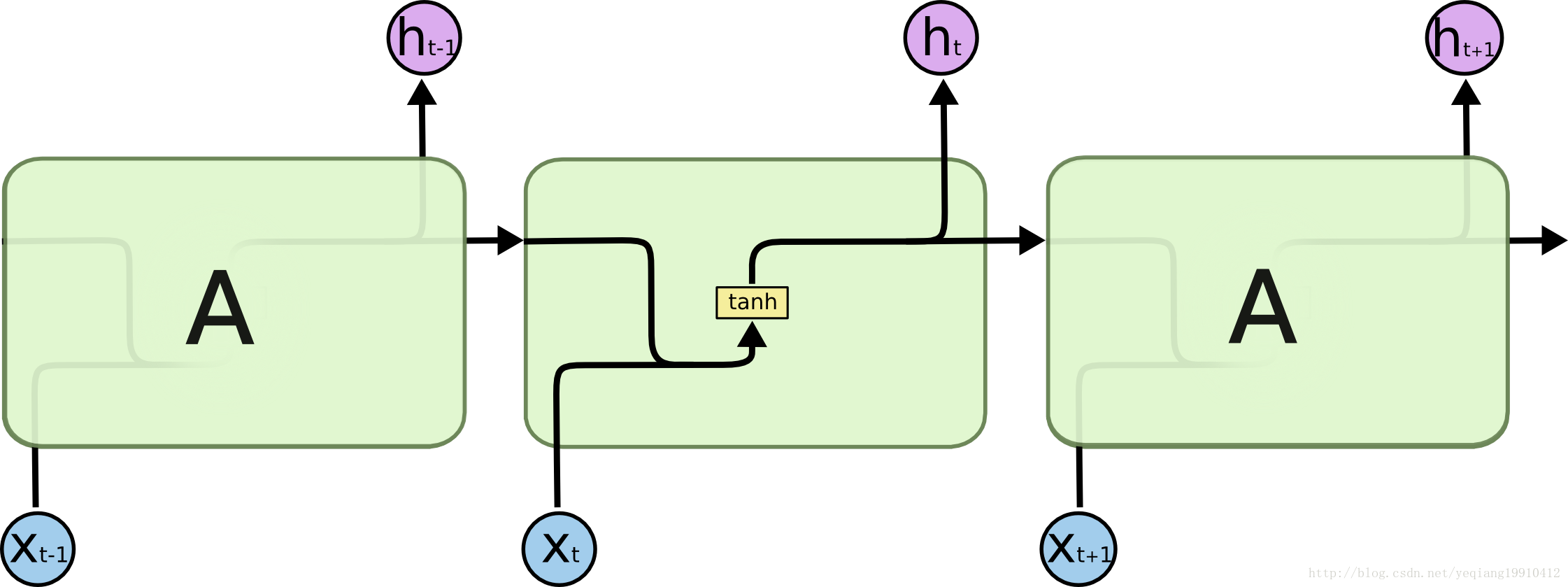
50 RNN和LSTM、GRU区别
普通RNN与LSTM的比较
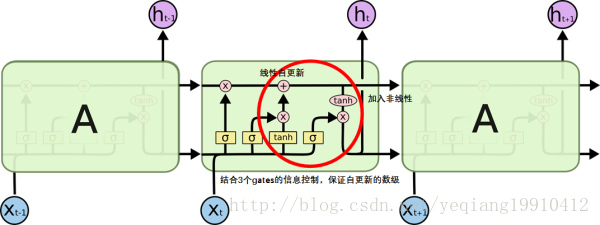
LSTM通过3个gate设置,有效的解决了梯度消失问题。
LSTIM比较GRU
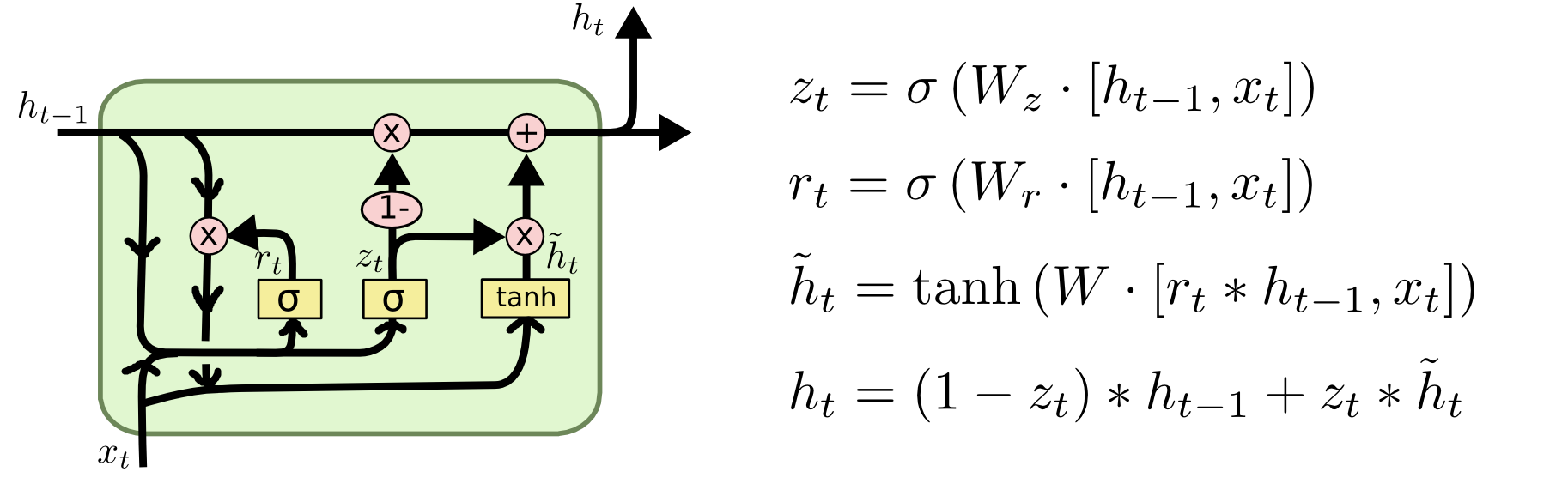
- LSTM 有三个 Gate,而 GRU 仅两个;
- GRU 没有 LSTM 中的 Cell,而是直接计算输出;
- GRU 中的 Update Gate 类似于 LSTM 中 Input Gate 和 Forget Gate 的融合;而观察它们结构中与上一时刻相连的 Gate,就能看出 LSTM 中的 Forget Gate 其实分裂成了 GRU 中的 Update Gate 和 Reset Gate。
51 transform相比于CNN优势在哪?
transformer的优势就在于利用注意力的方式来捕获全局的上下文信息从而对目标建立起远距离的依赖,从而提取出更强有力的特征。
(1)CNN是通过不断地堆积卷积层来完成对图像从局部信息到全局信息的提取,不断堆积的卷积层慢慢地扩大了感受野直至覆盖整个图像;但是transformer并不假定从局部信息开始,而且一开始就可以拿到全局信息,学习难度更大一些,但transformer学习长依赖的能力更强,另外从ViT的分析来看,前面的layers的“感受野”(论文里是mean attention distance)虽然迥异但总体较小,后面的layers的“感受野“越来越大,这说明ViT也是学习到了和CNN相同的范式。没有“受限”的transformer一旦完成好学习,势必会发挥自己这种优势。
(2)CNN对图像问题有天然的inductive bias,如平移不变性等等,以及CNN的仿生学特性,这让CNN在图像问题上更容易;相比之下,transformer没有这个优势,那么学习的难度很大,往往需要更大的数据集(ViT)或者更强的数据增强(DeiT)来达到较好的训练效果。
好在transformer的迁移效果更好,大的数据集上的pretrain模型可以很好地迁移到小数据集上。还有一个就是ViT所说的,transformer的scaling能力很强,那么进一步提升参数量或许会带来更好的效果(就像惊艳的GPT模型)。
52 先验和后验概率(贝叶斯公式)


53 极大似然估计
样本太多,无法得出分布的参数值,可以采样小样本后,利用极大似然估计获取假设中分布的参数值。
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
https://zhuanlan.zhihu.com/p/26614750
54 最大似然损失
在回归任务中等价于MSE损失
在分类任务中等价于交叉熵损失
55 目标检测:怎么处理不同类别数据不平衡的问题
- 数据扩充
- loss权重调整(Focal Loss)
56 模型压缩的方法
- 网络裁剪:参数裁剪、神经元裁剪
- 知识蒸馏
- 参数量化
参数量化(parameter quantization)通过对模型的参数做一些限制来减小模型的体积。 - 模型结构设计:
- 直接Mobile系列:DW,PW
- Shuffle系列:组卷积




















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











