






一、代码的调试分析
一般来说,开发程序不是简单的写代码,写测试代码,真正的高手,往往隐藏在手面的代码调试和分析上。假设一个程序总是在线上不定期的有问题,大家都无法解决,而一个开发者能够在很短的时间内把问题找到。那么可以想象其代码调试、分析和本地复现的能力肯定不一般。可以说,真正能解决问题的开发者,才更容易为别的开发者认可。
一般来说,可以把调试分成三大类:
- 本地调试
- 附加调试
- 远程调试
这个不用细说,在前面的GDB相关调试分析中也说明过多次。不清楚的可以回头翻看一下相关的内容。而如果从另外一个角度来将调试和分析分类,又可以分成以下几种: - 使用IDE分析调试
一般说,成熟的语言都有大公司提供的IDE,其中集成了相当多的调试用的各种方式和分析工具,最典型的莫过于宇宙第一IDE,Vistual Studio系列了。当然,安卓、IOS等也都有类似的工具。假如一门语言缺少这么一个好的IDE,那么可以负责任的说,它肯定难于被更广大的开发者接受 - 使用代码分析调试
当然这就是传统的代码分析,即打个Print,写个日志等等。包括后来一些语言或库提供的打桩的接口等等,都可以划分到这一个部分。使用代码分析,特别适合一些复杂(如高并发异步)、不易现场调试以及硬件等一系列场景 - 使用工具分析调试
使用工具是一种非常好的调试分析方式,如果一个开发者不会使用一些流行的工具进行相关的调试分析,那么其调试的水平肯定受限。良好的调试分析工具,如一些公司提供的工具,可以迅速定位相关的问题并给出解决的建议。大家可以参考一下内存的检查工具。工具最显著的特点,就是提高代码分析调试的效率。
二、CUDA程序的调试
CUDA为开发人员贴心的安排了很多开发工具,它们包括编译器、分析器、集成IDE及其插件、调试器和内存检查器等等。它们对于开发CUDA程序的重要性是不言而喻的。本节将重点分析一下调试和分析工具。
CUDA中的调试和分析也是按上述的调试进行分类的。这里重点对本地调试的方法进行一下相关的说明:
- CUDA中的代码调试
- 使用提供的分析接口调试
在CUDA中提供了相关的分析接口调试分析的机制,如限定目标调试分析,可以使用“cuda_profiler_api.h”提供的接口如cudaProfilerStart()和cudaProfilerStop()进行范围控制,有没有想到前面的prof相关的分析方法?不过在应用时需要添加–profile-from-start标志。
使用–timeout 选项来限制应用程序执行的时间,可想而知,当开发的程序中需要分析一些较长的工作任务时非常用用
使用–devices 选项来指定要分析的GPU,这也非常有用,可以用来查找定位怀疑的可能的设备核心
当然还有很多,比如–kernels、–event和–metrics等等,然后就可以使用nvprof进行分析调试了。
需要说明的是,目前CUDA已经推出了更优秀的NVIDIA Nsight Systems 和 NVIDIA Nsight Compute,建议大家在可能的情况下使用后者。
另外还有一个CUDA的工具提供了API即NVTX,它提供如nvtxRangePushA()和nvtxRangePop()等相关的开发接口 - 使用断言进行调试:
断言调试是开发者最常用的方式,这个可能对广大开发者者来说非常好理解,CUDA框架中提供了void assert(int expression)断言来实现结果的判断,使用方式与c/c++中的相关断言宏类似。 - 使用CUDA的错误机制调试
开发者都知道,在Linux开发中,如果调用一个API出现问题,都可以使用错误机制来得相关的错误ID来确定是何种错误并进行提示。CUDA也提供了类似的机制。比如调用cudaMalloc()函数如果因为内存不足失败,则可以通过调用cudaGetLastError()捕获由内核调用触发的标志。通过它可以得到错误状态。不过这个标志需要手动处理并且它不并保证错误发生的时机的确切性,大家可以使用cuda_helper.h中提供的checkCudaError()来打印相关的错误消息。
- CUDA的IDE及相关工具调试
- 使用Nsight(NVIDIA Nsight Systems 和 NVIDIA Nsight Compute)及其相关插件(Vistual Studio等等)调试分析
对于Windows平台的开发人员,CUDA Toolkit提供了Nsight相关的工具,可以集成到VS中进行应用。这个工具非常简单易用,它使得CUDA程序的调试和分析一如了普通的C++应用程序的开发。直接下断点即可进行调试、分析处理。
它主要有几个部分:图形调试(用于Direct3D及OpenGL等应用程序);CUDA调试(由于版本的不同可能只支持GPU调试或同时支持CPU和GPU的调试);性能分析器(用于分析当前GPU的性能);CUDA内存检查器(用于运行时检查GPU的内存问题)
如何安装环境可参考前面的文章“CUDA编程环境安装”。 - 使用CUDA GDB进行调试分析
CUDA GDB,和GDB一样,支持本地和远程调试分析。当然可调试的程序需要使用-G(GPU)和-g(CPU)的调试编译选项才允许。它的用法和GDB没有什么不同,可以对变量、调用栈等进行查看和相关的分析,细节上可能是有些名字的细微差别罢了。 - 使用CUDA memcheck进行运行时分析调试
内存问题在哪儿都是一个老生常谈的问题,不过怎么谈也谈不完。GPU同样也是如此,CUDA memcheck提供了对GPU中内存安全访问的相关检查机制如内存访问错误如越界、对齐等;硬件异常引起的错误;内存分配API(Malloc/free)等的错误;内存泄露(经典的问题);
三、在Window上的应用调试例程
下面用前面一个例子来演示下在vs2017中如何使用Nsight进行初步的调试:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
// CUDA核函数:向量加法
__global__ void vecAdd(const float *a, const float *b, float *c, int num) {
int i = blockDim.x * blockIdx.x + threadIdx.x;//此处打一个断点
if (i < num) {
c[i] = a[i] + b[i];
}
}
int main(void) {
// 设置向量大小
int num = 100000;
size_t size = num * sizeof(float);
printf("[Vector addition of %d elements]\n", num);
// 分配主机内存
float *h1 = (float *)malloc(size);
float *h2 = (float *)malloc(size);
float *h3 = (float *)malloc(size);
// 初始化主机数组
for (int i = 0; i < num; ++i) {
h1[i] = rand() / (float)RAND_MAX;
h2[i] = rand() / (float)RAND_MAX;
}
// 分配设备内存
float *d1 = NULL;
float *d2 = NULL;
float *d3 = NULL;
cudaMalloc((void **)&d1, size);
cudaMalloc((void **)&d2, size);
cudaMalloc((void **)&d3, size);
// 拷贝数据到设备
cudaMemcpy(d1, h1, size, cudaMemcpyHostToDevice);
cudaMemcpy(d2, h2, size, cudaMemcpyHostToDevice);
// 启动核函数
int tdPerBlock = 256;
int bPerGrid = (num + tdPerBlock - 1) / tdPerBlock;
printf("CUDA set: %d blocks of %d threads\n", bPerGrid, tdPerBlock);
vecAdd << <bPerGrid, tdPerBlock >> >(d1, d2, d3, num);
// 拷贝结果回主机
cudaMemcpy(h3, d3, size, cudaMemcpyDeviceToHost);
// 验证结果
for (int i = 0; i < num; ++i) {
if (fabs(h1[i] + h2[i] - h3[i]) > 1e-5) {
fprintf(stderr, "verification err id: %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test OK\n");
// 释放内存
free(h1);
free(h2);
free(h3);
cudaFree(d1);
cudaFree(d2);
cudaFree(d3);
cudaDeviceSynchronize();
system("pause");
return 0;
}
在Vs2017中在上面的断点位置处打上断点(方法与直接使用VS调试打断点方法一样),直接点击菜单中的“Nsight”,在下拉菜单中选择“Start CUDA Debugging”,程序随即启动,并停留在断点处。由于本机的显卡级别较低(所以其驱动版本也低),所以此不支持CPU和GPU的同时调试(从查阅的资料中大概是支持CUDA10.1级别的显卡可以同时支持)。然后就可以点击“Nsight”的子菜单中的相关菜单项如针对具体的Wrap和相关的Block等进行调试和分析,见下图。
菜单相关:
切换Active Wrap的变化:
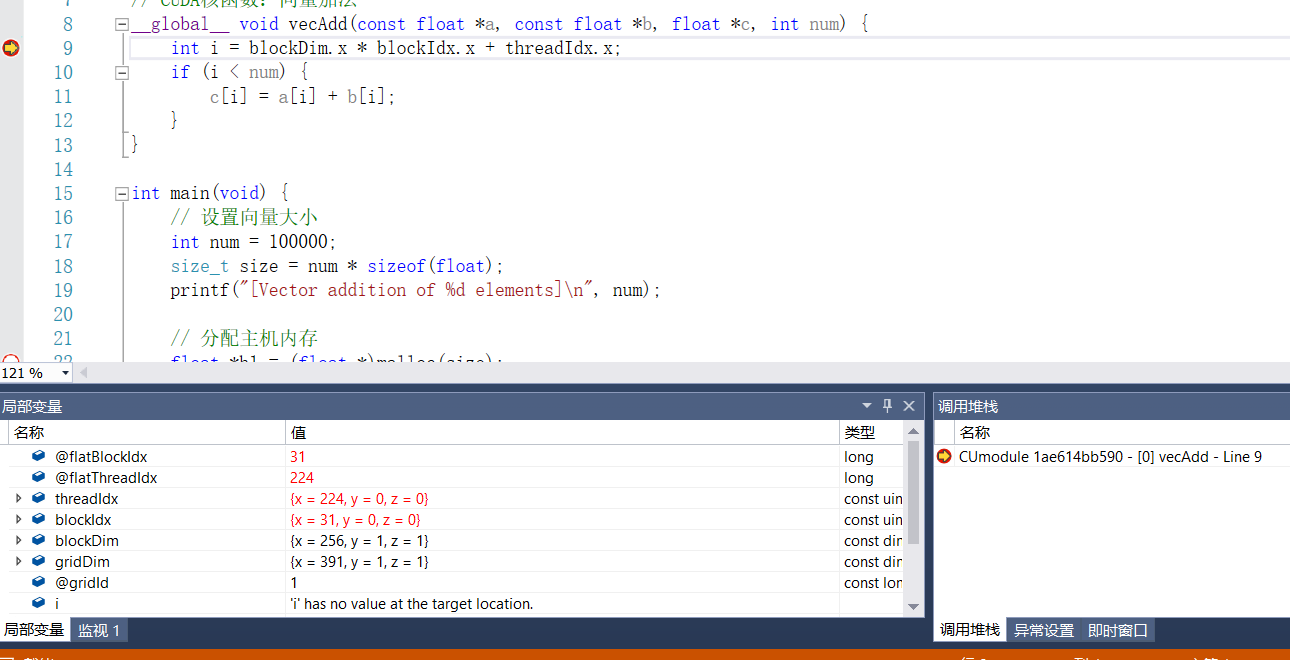
此处只简单展示一下如何使用nsight工具的方法,更多的细节应用在后面会进行专门的说明。
四、辅助分析工具
CUDA中有不少的辅助调试分析的工具,这里简单的介绍一下:
- NVIDIA Compute Sanitizer
用于验证功能是否正确的检查器,可以替代memcheck。它是NVIDIA官方出品 - apitrace:用于对图形API进行跟踪,对整个流程进行刻录、回话和调试,对于一些比较不容易重现的Bug非常有用。比如Direct3D以及OpenGL等图形API。支持跨平台使用
- TAU (Tuning and Analysis Utilities):跨平台的并行性能分析工具集,可对调用堆栈、路径等进行分析合并,自动捕获CUDA内核、内存等相关的性能数据。可以全栈应用(CPU+GPU等)
五、总结
这次仅仅是对CUDA程序的调试和分析做一个整体的说明,以后会跟随着CUDA编程的推进针对一些具体的相关调试分析再逐一进行详细的分析和使用说明。搞过开发的都清楚,如果不能掌握良好的调试方法和调试手段,没有趁手的调试工具,那么想写出一个安全稳定的程序难之又难。还是那句话,工欲善其事,必先利其器。古人诚不我欺!


















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









